

Amazon Personalize 利用機器學習建立個人化推薦系統
大綱

Amazon Personalize 是一種機器學習服務,可讓開發人員輕鬆地為其應用程式建立個別化的建議。
使用 Amazon Personalize,用戶可以從應用程式提供活動串流、頁面檢視、註冊、購買等等,以及要推薦的項目,例如:文章、產品、影片或音樂。 用戶也可以選擇向使用者提供 Amazon 個人化的額外人口統計資訊,例如:年齡或地理位置。Amazon Personalize 將處理和檢查資料、識別有意義的內容、選擇正確的演算法,以及訓練和最佳化針對資料自訂的個人化模型。
事前準備
- 確認操作環境在 US East (N. Virginia),其縮寫為 us-east-1。
- 下載 ratings.csv 到本地端。
建置過程
一、建立 S3 Bucket
-
在 Service menu 選單中,選擇 S3。
-
選擇 Create bucket。
-
為你的 S3 bucket 輸入一個 獨特的 名字。
-
選擇介面左下角的 Create。
-
搜尋你的 bucket 名字,並點選其名稱以進入此 bucket。
-
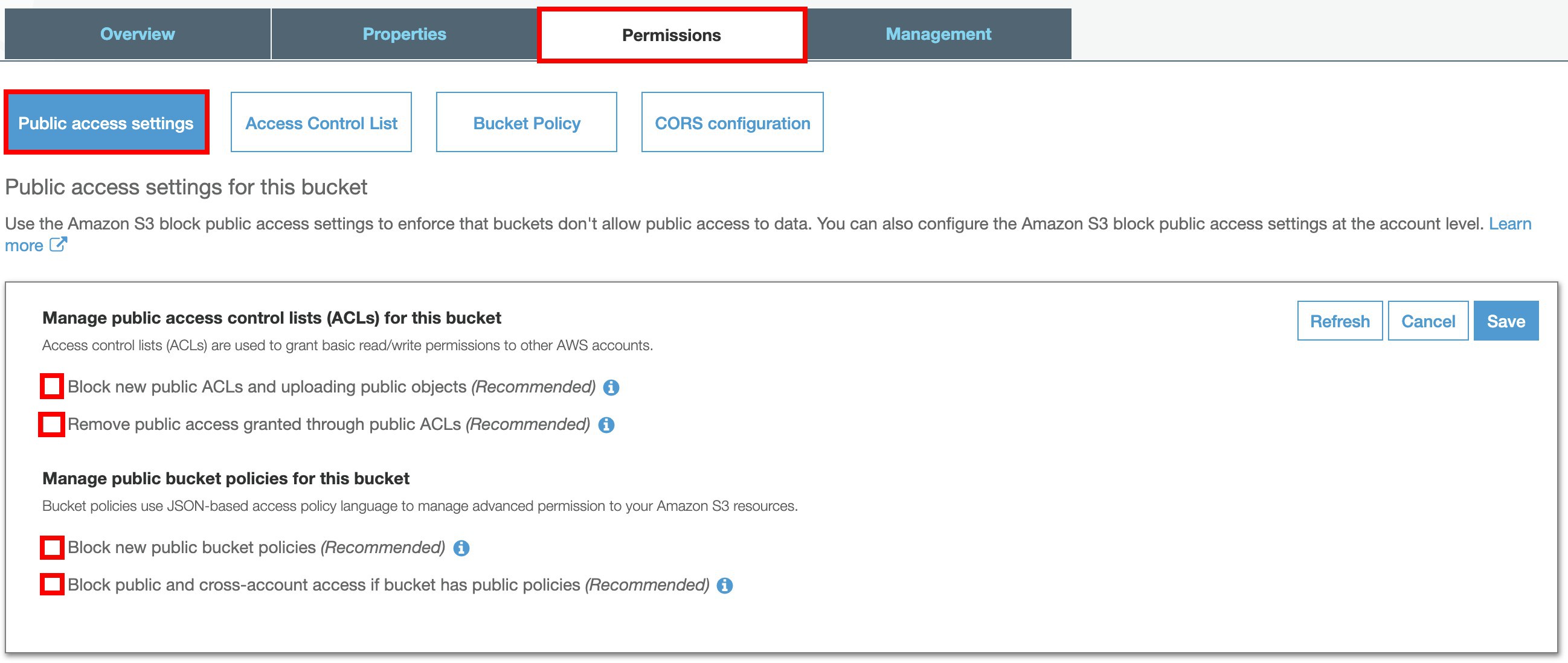
選擇 Permissions 標籤,並選擇 Public access settings, 點選 Edit。
-
反選所有的 ☑,選擇 Save。
-
選擇 Bucket policy,複製並貼上底下的 json 程式碼,記得將
更換成你自己的 Bucket name,並選擇 Save。
{
"Version": "2012-10-17",
"Id": "PersonalizeS3Bucket AccessPolicy",
"Statement": [
{
"Sid": "PersonalizeS3BucketAccessPolicy",
"Effect": "Allow",
"Principal": {
"Service": "personalize.amazonaws.com"
},
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<your-bucket-name>",
"arn:aws:s3:::<your-bucket-name>/*"
]
}
]
}
-
選擇 Create folder,檔案名稱請輸入 movie rating。
-
點選檔案名稱以進入此檔案。
-
選擇 Upload, 選擇 Add files,選擇我們在 Prerequisites下載的<ratings.csv>,選擇介面左下角的 Upload。
-
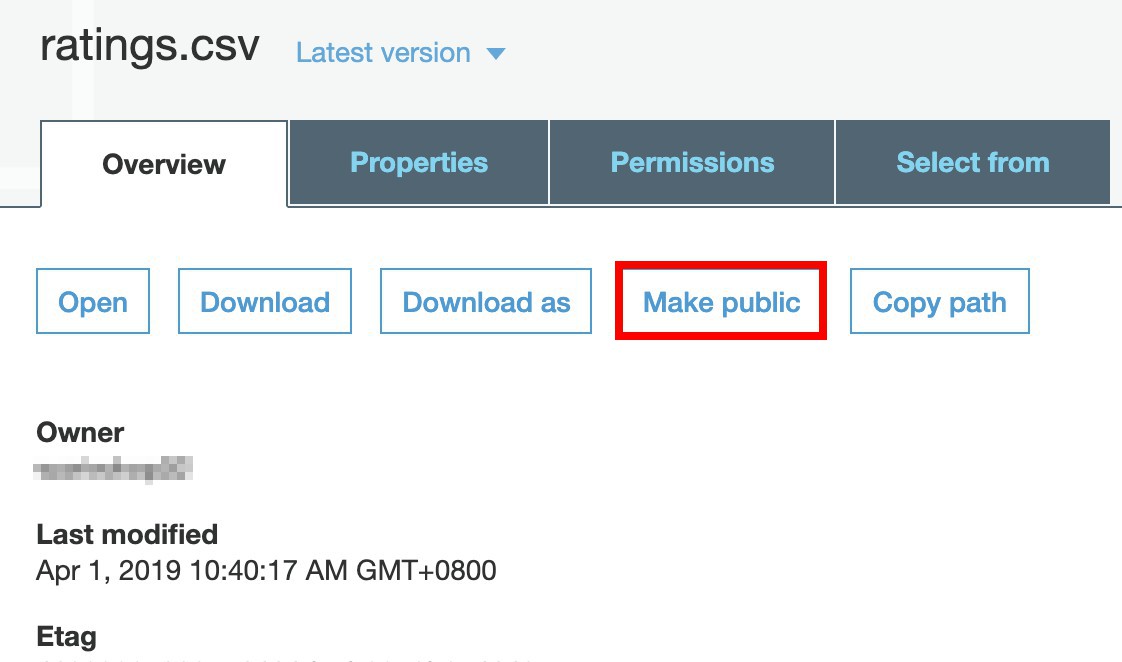
點選檔案名稱以進入做設定。
-
點選 Make Public 讓檔案變成可讀取的。
二、建立 IAM Role
-
在 Service 選單中,選擇 IAM。
-
在左方的選單中,選擇 Roles,並點選 Create role。
-
在 Select type of trusted entity 底下,選擇 AWS service,至於 Choose the service that will use this role 選擇 Personalize,如果你找不到此服務,選 EC2 就好,並選擇 Next:Permissions。
-
搜尋並 ☑:
- AmazonS3ReadOnlyAccess
- CloudWatchFullAccess
-
選擇 Next:Tags 你可以選擇是否加上標籤,否則,選擇 Next:Review。
-
在 Role name 輸入
PersonalizeRole,並確認你已經選取兩個 policies,選擇 Create role。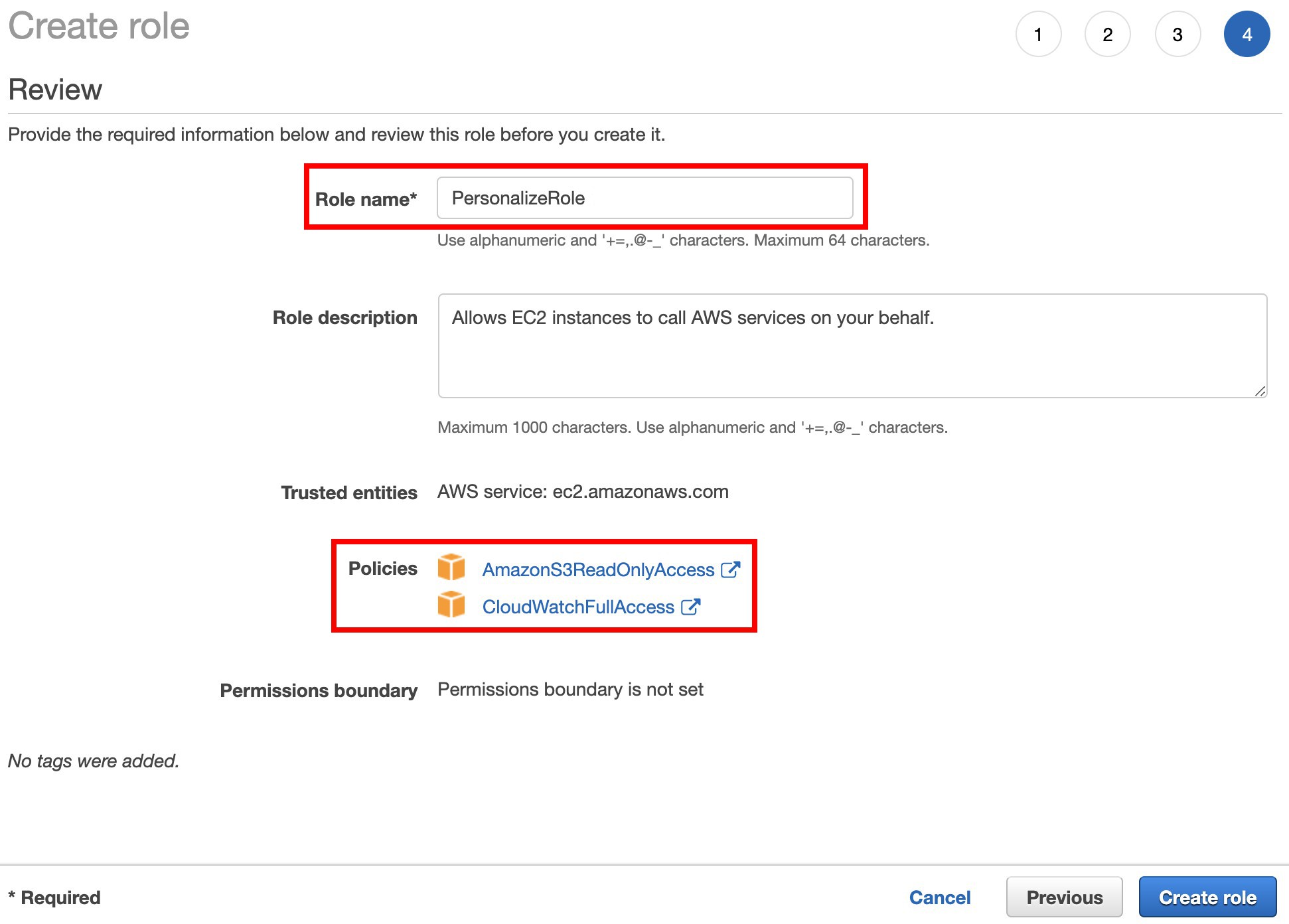
-
搜尋你剛剛創好的 Role name:
PersonalizeRole。 -
複製 Role ARN 到記事本,我們接下來的步驟會用到。
-
選擇 Trust relationships,點選 Edit trust relationship。
-
複製並貼上底下的 json 碼,以取代 Policy Document:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "personalize.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
- 選擇 Update trust policy。
三、建立 Dataset group
-
在 Service 選單中,選擇 Amazon Personalize。
-
如果是第一次使用 Personalize,選擇 Get Started,否則,選擇 Create dataset group。
-
在 Dataset group name 輸入
my-personalize-dataset-group,並且 ☑ Upload user-item interaction data for Input data。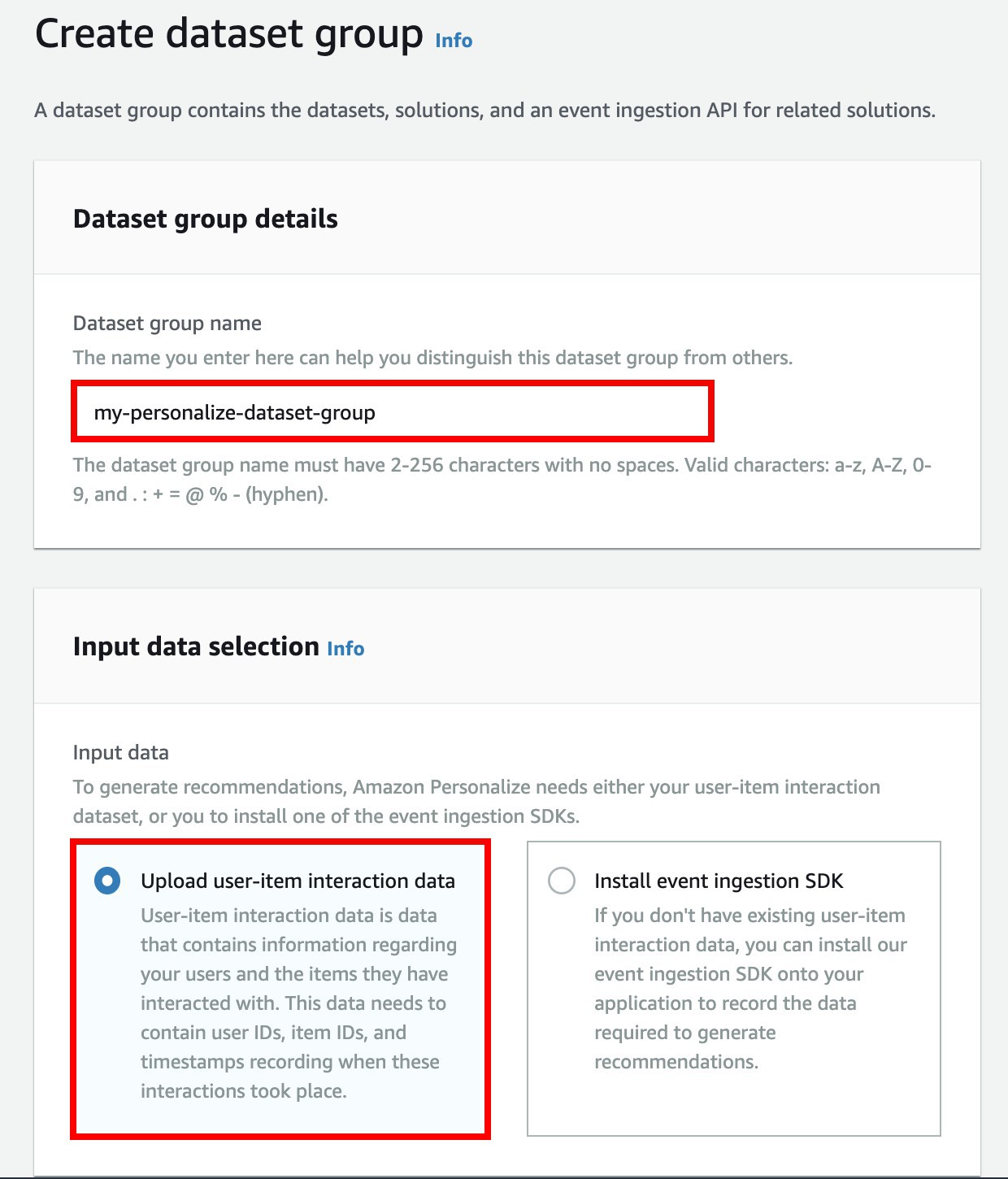
-
點選 Next。
-
在 Dataset name 輸入
my-dataset。 -
在 Schema selection 選擇 Create new schema,並在 New schema name 輸入
my-schema,複製並貼上底下的 json code到 Schema definition。User-item interaction data 的 json 格式 必須 有這三個 fields:
- USER_ID
- ITEM_ID
- TIMESTAMP
可以再寫好這三個 fields 之後寫上其他的 fields。
{
"type": "record",
"name": "Interactions",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "USER_ID",
"type": "string"
},
{
"name": "ITEM_ID",
"type": "string"
},
{
"name": "RATING",
"type": "string"
},
{
"name": "TIMESTAMP",
"type": "long"
}
],
"version": "1.0"
}
-
選擇 Next。
-
在 Dataset import job name 輸入
my-dataset-import,並貼上 Role ARN 到 Custom IAM role ARN,輸入 <ratings.csv> 存在 S3 中的路徑:s3://<your-bucket-name>/movie rating/ratings.csv。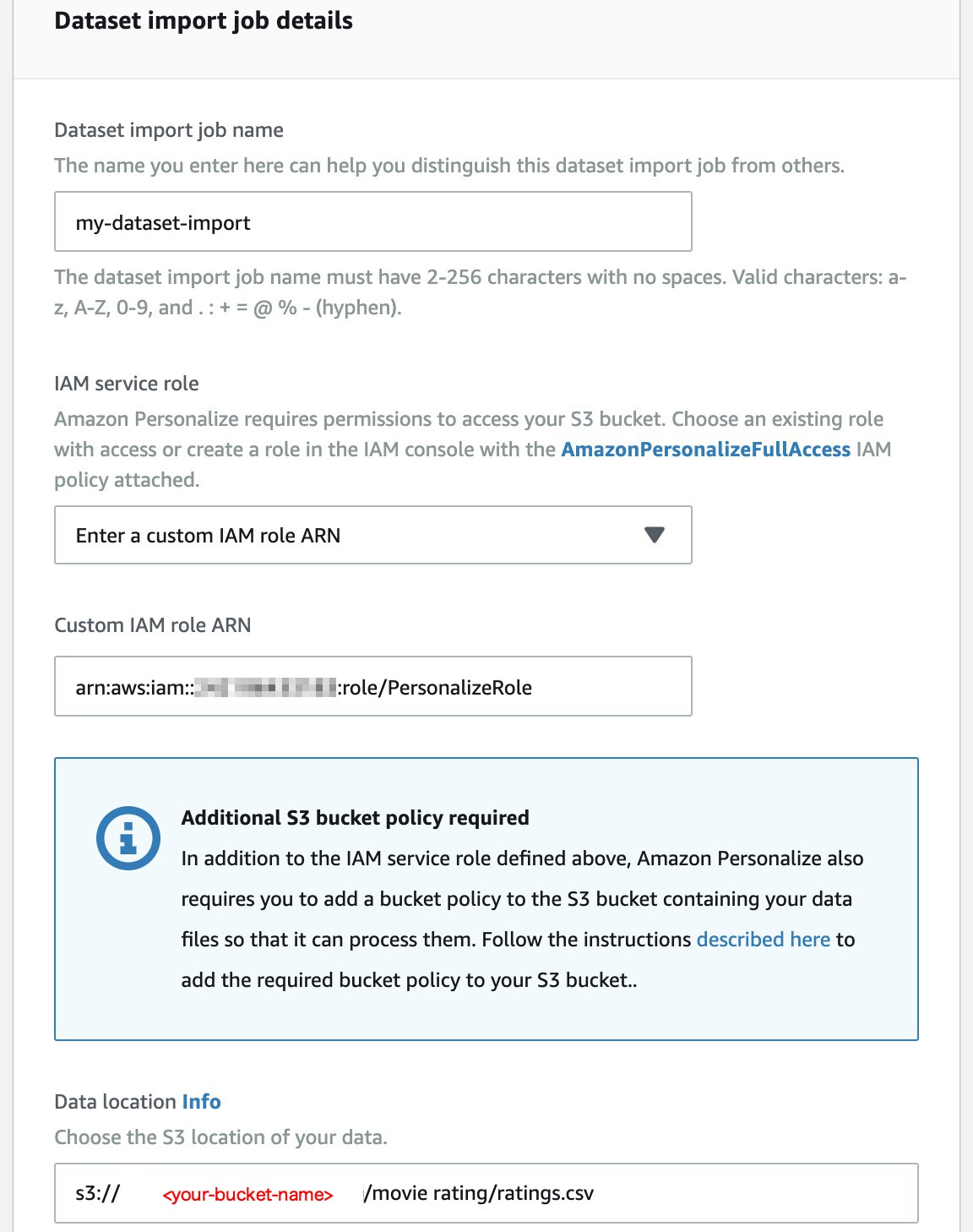
-
選擇 Finish。
-
等待 User-item interaction data 建立,它的狀態會在建立好的時候轉變為Active,這個部分大概需要 5-10 分鐘。
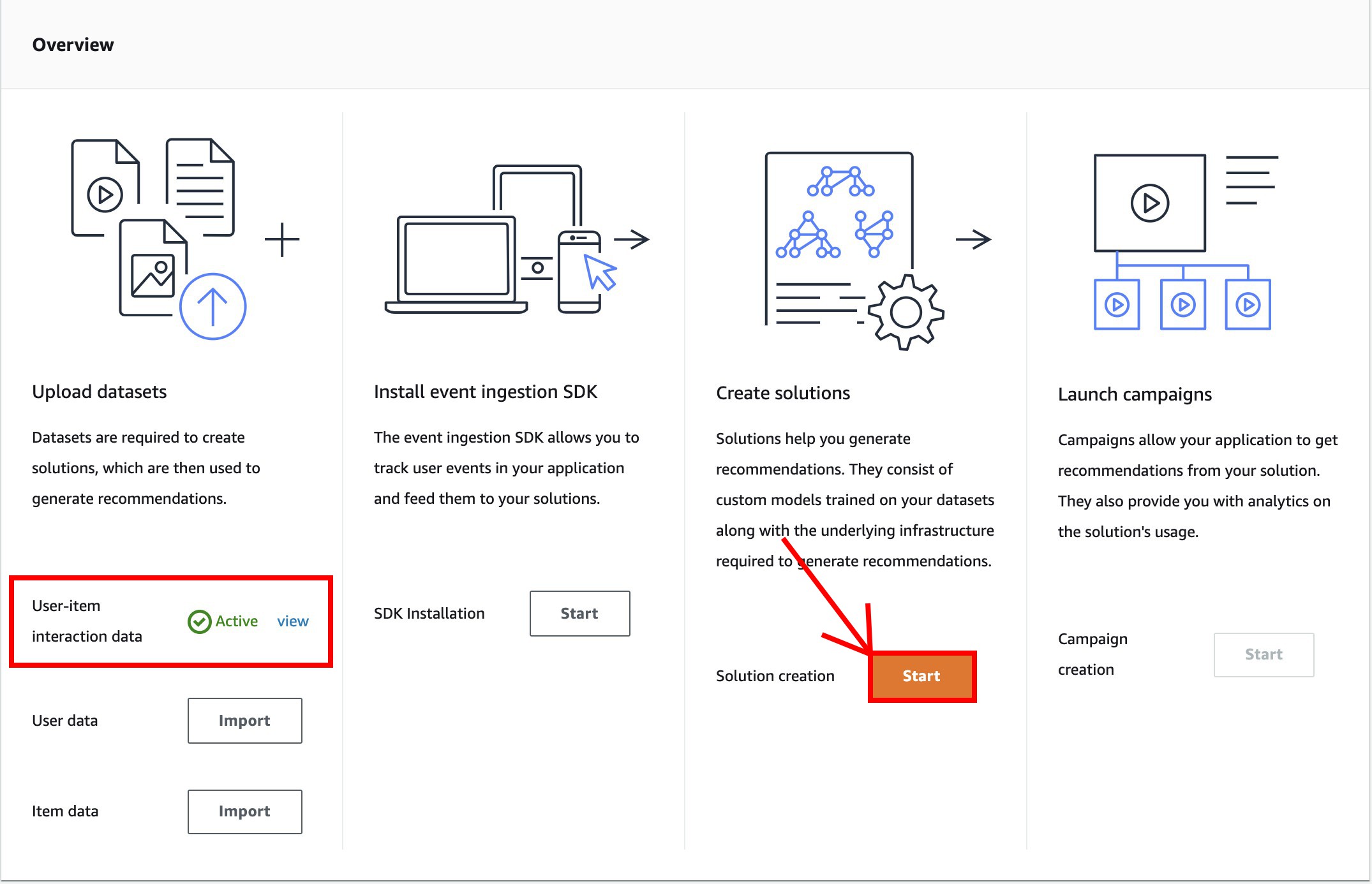
四、建立 solutions
-
在 Create solutions 窗格,選擇 Start。
-
在 Solution name 輸入
my-solution,並且 ☑ Automatic (AutoML)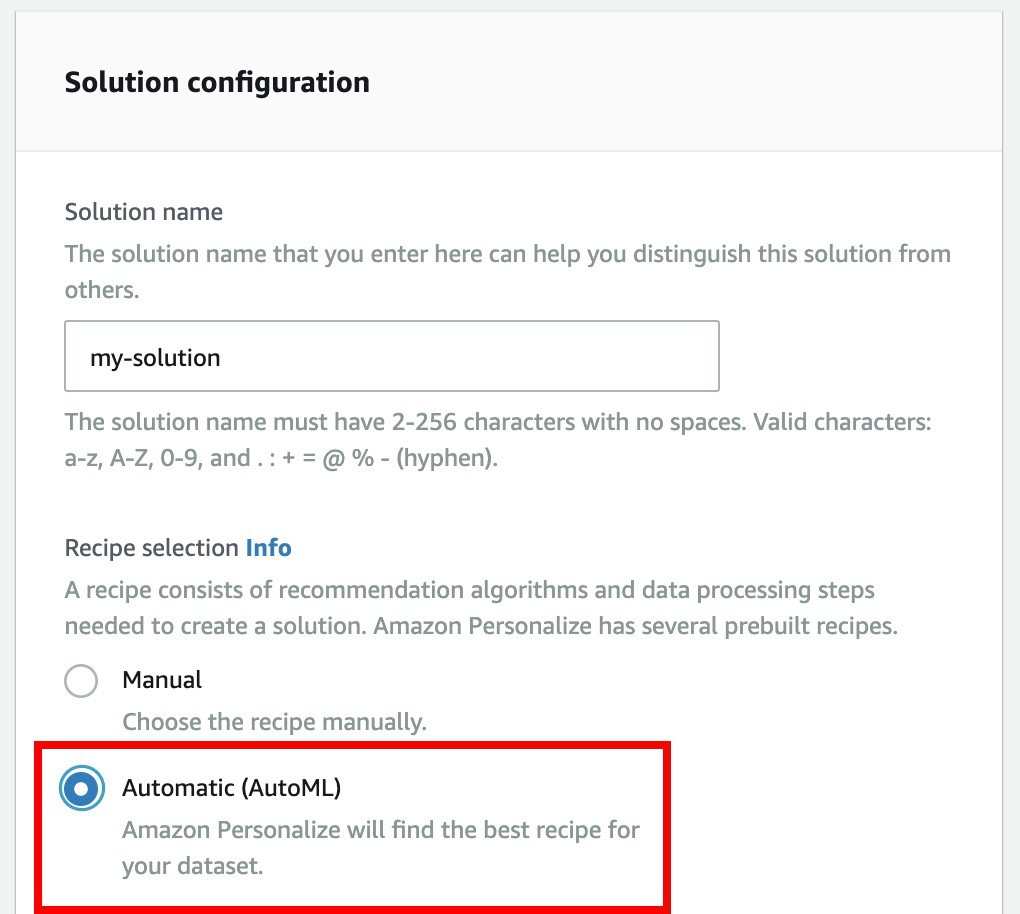
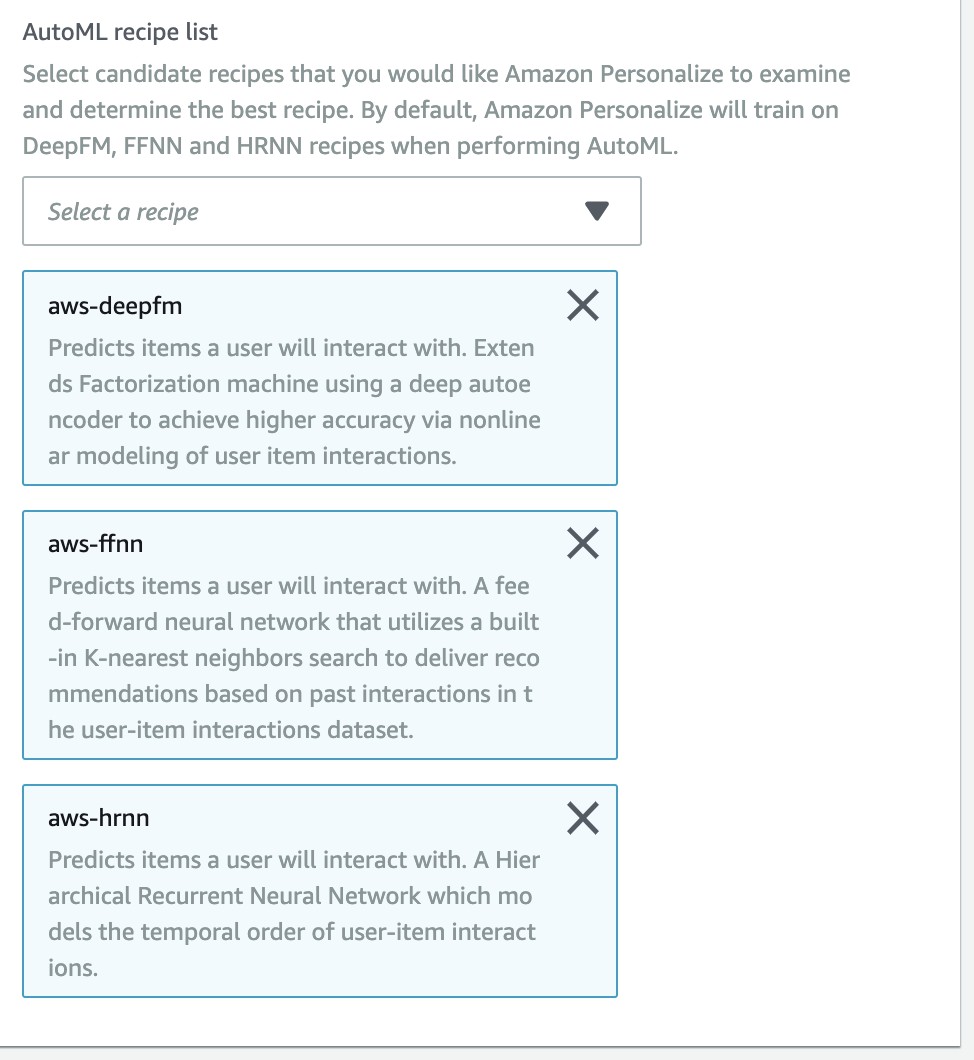
-
這部分會預設選擇三個機器學習的方法:
- aws-deepfm
- aws-ffnn
- aws-hrnn
-
選擇 Next 檢查詳細的資訊,如果沒有問題,選擇 Finish.
-
等待 Solution creation,這個部分大概需要 30-40 分鐘。
五、建立 Campaign
-
在 Launch campaigns 窗格,選擇 Create new campaign。
-
在 Campaign name 輸入
my-campaign,Solution 選擇 my-solution,將 Minimum provisioned transactions per second 保留為預設。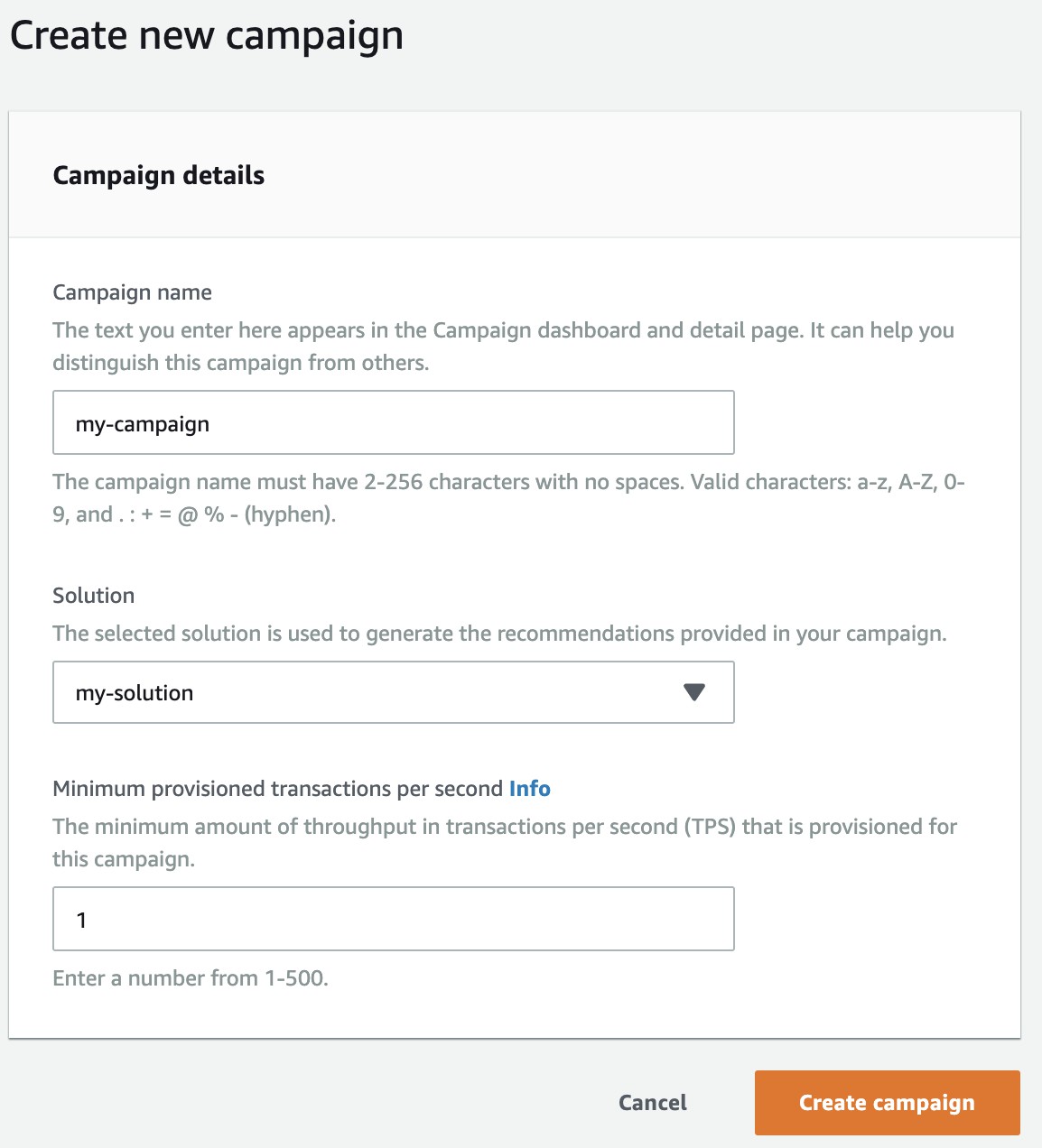
-
等待 Campaign 的建置,這個部分大概需要 10-20 分鐘。
-
在建置完成後,你會看到這個介面,可以輸入你喜歡的 USER_ID,並點選 Get recommendations,例如:
200,底下便會輸出推薦的電影名稱。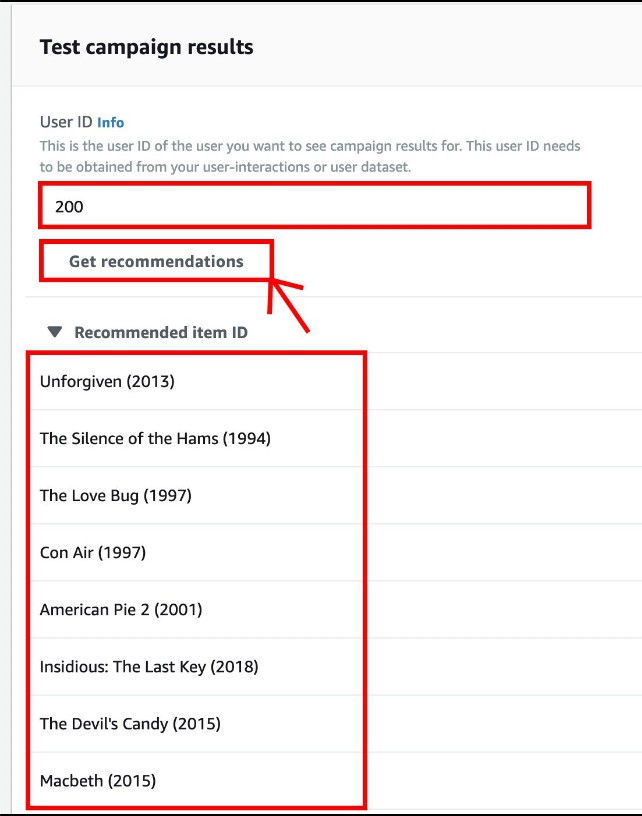
Conclusion
恭喜! 你已經學會如何 上傳資料集, 利用 Amazon Personalize 提供的機器學習方式,最後 利用 Amazon Personalize 製作個人化推薦系統.
Clean up
- Campaign:
my-campaign. - Solution:
my-solution. - Dataset group:
my-personalize-dataset-group. - S3 bucket.
- IAM Role:
PersonalizeRole.
Tag:Amazon Personalize, Amazon S3, AWS, IAM Role, S3
You may also like

【焦點新聞|Microsoft Build 2022】

【焦點新聞】0428-0511 AWS 服務更新
