

【每周快報】1204-1210 AWS 服務更新
前言
這周進入了 AWS re:Invent 的第二周,除了在活動中宣布重大新服務外,AWS 也持續為各個服務做改善。在機器學習方面,Amazon SageMaker 新增了高達五種新功能,像是 Amazon SageMaker JumpStart 替使用者預先建立好模型來作為解決方案,而 Amazon SageMaker Edge Manager 則能夠讓使用者管理多個 Edge Devices 上的 model。在大數據方面,AWS 則為 Amazon Redshift 推出不少新功能,我們也會在此篇文章中一一介紹。
想針對 AWS re:Invent 發布的內容了解更多的朋友,也可以參考 【2020 AWS re:Invent 即時新聞】- Machine Learning Keynote 以及 【2020 AWS re:Invent 即時新聞】- Andy Jassy Keynote唷!
焦點新聞
Amazon HealthLake – 管理多達 PB 等級的個人醫療數據
Amazon HealthLake 是一項符合 HIPAA 規範的服務,讓醫療產業的相關人員,像是醫療照護提供商、健康保險公司和製藥公司等使用者,能夠儲存、轉換、查詢和分析 PB 等級的醫療數據。
醫療數據通常容易因為不同的機構、系統而四散各處;或因紀錄人員的習慣不同,讓數據格式不同而不完整。如果能有一個解決方案,可以統整這些凌亂的數據,就可以幫助醫療人員更加了解病患的醫療病史、個人背景、家庭遺傳因子…等,也就更容易依據這些數據做診療上的決策。
Amazon HealthLake 來解決上述挑戰,使用者可以快速的從 on-premise 環境上傳數據到 Amazon HealthLake,HealthLake 利用機器學習技術,從格式、結構、字體不同的數據中,擷取具有醫療意義的內容,並產生符合 Fast Healthcare Interoperability Resources (FHIR) 工業標準格式的資料,降低醫護人員整理數據的困難。
另外,使用者可以利用 HealthLake 整理後的資料,串接 AWS 其他服務,像是用 SageMaker 做未來預測、用 QuickSight 產生 BI 圖表。

參考來源至:Introducing Amazon HealthLake to make sense of health data
Amazon Neptune ML – 可快速且精準的預測圖形
Amazon Neptune 是一個全託管的圖形化資料庫,支援熱門的圖形模型 Property Graph 與 W3C RDF 及其查詢語言 Apache TinkerPop Gremlin 與 SPARQL。
AWS 一直以來都在思考該如何降低機器學習的技術門檻,讓每個使用者都可以快速上手、並且訓練與部署自己的機器學習模型,以往要整合資料庫中的資料,做 Model Training 並部署至應用端,通常需要 Database administrator (DBA) 跟 Data Scientist 一起合力做建立模型、擷取資料、資料正規化與一連串的調整與配合才會有結果。
對於那些數據量非常龐大(關係圖非常複雜)的使用者來說,要準確的預測既困難又耗時,現有的 ML 方法(例如 XGBoost)也無法有效運行,因為它們是為了表格數據而設計的,因此 AWS 在此次 re:Invnet 中宣佈了 Neptune ML 功能,透過圖神經網絡(GNN)針對 Neptune 資料庫的關聯進行預測。

Neptune ML 主要還是透過 SageMaker 進行機器學習訓練與部署,AWS 會在其中自動完成當中繁重的資料處理流程,並透過開源的 Deep Graph Library(DGL)進行訓練。
參考來源至:Amazon announces Amazon Neptune ML: easy, fast, and accurate predictions for graphs
圖片來源至:Amazon Neptune ML
Amazon Lookout for Metrics
基本上任何規模的組織或企業都會監控數據的趨勢與變化,以紀錄與避免意外狀況發生,但尋找這些異常並非易事。
傳統會用 Rule-based 來篩選某一範圍的數據,但如果範圍太窄,會導致過多的錯誤警報;但如果範圍太廣,則會導致忽略異常。再者維運人員該如何制定這個範圍也是一大難題,可能會時間、季節、特殊節日而有所不同,因此需要經常手動更新。
在此次 re:Invent 中,AWS 推出了 Amazon Lookout for Metrics,使用機器學習(ML)來檢測、診斷業務數據中的異常值,使用者只需將數據來源設定好(支援 S3、CloudWatch、Redshift 和 RDS 等 AWS 服務,以及 Salesforce、Marketo 和 Amplitude 等第三方 SaaS 服務),Lookout for Metrics 便會自動檢查這些數據並建立 ML 模型,此後便可於偵測到異常值時透過其他推播通知服務(SNS)進行告警。
Amazon SageMaker 推出新功能
Amazon SageMaker Pipelines – 專為機器學習而構建的 CI / CD 服務
在進行 Machine Learning 機器學習之前,使用者需要收集很多不同類型的資料,並做前處理讓資料變得更乾淨,再把資料放在 S3 Bucket、Athena 或是 Redshift。接著,還需要花費許多時間在資料集中尋找 feature,完成之後才可以開始訓練自己的模型。
以往使用者在做 Model Training 的時候,需要拆分不同階段進行,當有新的資料進來便要重新跑一次訓練、部署的流程;透過 SageMaker Pipeline,使用者可以更輕鬆的執行 Model Training 的流程以達到 CI/CD 自動化流程。

參考來源至:Introducing Amazon SageMaker Pipelines, first purpose built CI/CD service for machine learning
圖片來源至:New – Amazon SageMaker Pipelines Brings DevOps Capabilities to your Machine Learning Projects
Amazon SageMaker Edge Manager – 管理多個 Edge Devices 上的 model
在 2018 年 AWS 發布了 SageMaker Neo 讓使用者輕易部署 Machine Learning 到那些終端設備上,但是一個 Neo 只能部署一個 model,對於那些大場域的使用者來說,需要管理太多 Neo。

推出 SagaMaker Edge Manager 來管理、監控及更新那些終端裝置與 model。除此之外,使用者還可以透過 Edge Manager,對自己的 model 進行加密,提供安全性。
參考來源至:AWS introduces Amazon SageMaker Edge Manager – Model Management for Edge Devices
Amazon SageMaker Feature Store – 用來存放、分享、取用 ML features 的儲存庫
為了避免所謂的 “garbage in, garbage out (GIGO)” 的情況發生,開發者習慣針對訓練資料集作前處理,像是 missing values 怎麼處理、偏離值要不要剔除、需不需要做 data normalize 正規化…等特徵工程 (feature engineering),越高品質的資料集會訓練出越好的模組。
Feature engineering 常會應用於整理 raw data、訓練模型以及評估模型的準確性,因此 feature 會經過多次使用,重複相同的操作而耗費大量時間。
透過 SageMaker Feature Store 使用者可以簡化 Feature engineering 的流程,更輕易地組織、管理、取用訓練資料的特徵和資料。

Amazon SageMaker JumpStart – 使用者可快速地取用預先建構的模型作為解決方案
有許多開發人員希望可以將機器學習模型結合到自身的解決方案中,以解決其業務問題。但是,對於剛接觸機器學習的使用者而言,構建、訓練、部署,再繼續優化模型。整個過程不僅要花費不少時間,也需要具備一定的背景知識,因此往往讓人望之卻步。
為了解決入門門檻較高的問題,部分的使用者會取用一些公開的資源,例如:TensorFlow Hub、PyTorch Hub 等開源的社群,在其尋找適合的的 model。但這只解決了其中一個步驟,使用者還需要自行找到適合的部署工具、收集資料並轉換成可利用的格式、測試 model…等,仍需要花費不少工敷。
AWS 推出 Amazon SageMaker JumpStart,提供已經打包好的 solution,例如:瑕疵檢測、預測性維護、需求預測..等,使用者可直接引入應用程式。
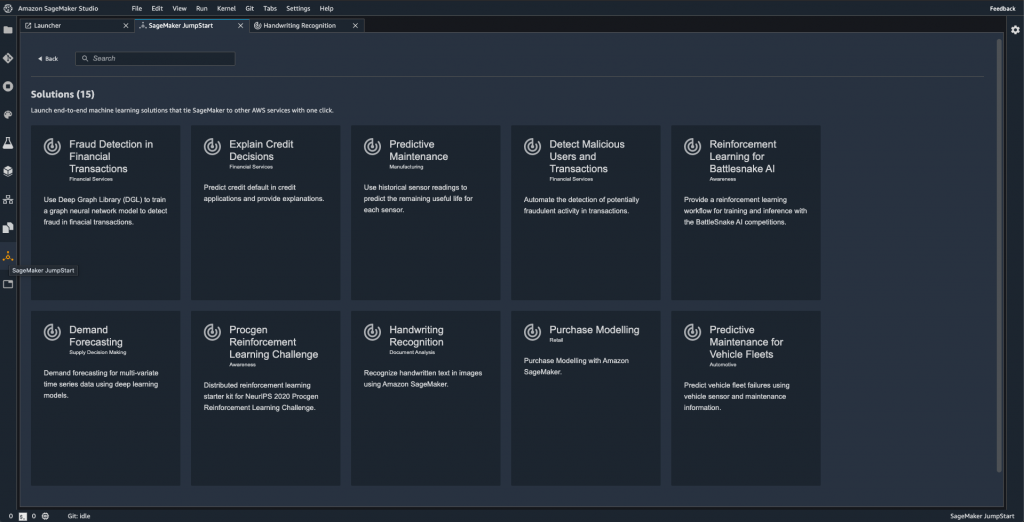
- 選擇符合自身情境的 solution 後,可以在 detail 頁面看到更多與該 solution 相關的資訊。例如:使用的 dataset、適合的場景
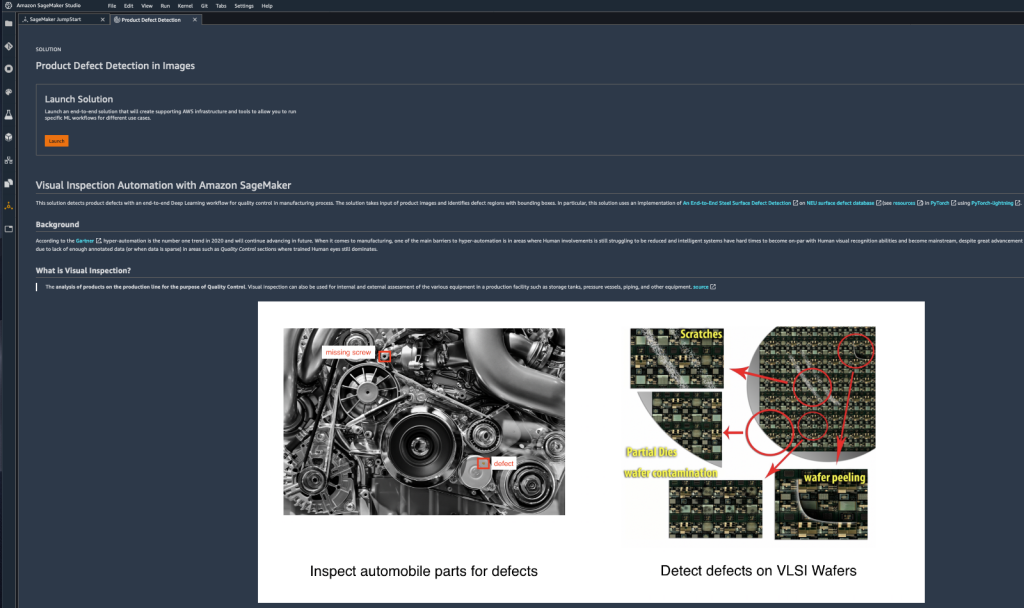
另外,SageMaker JumpStart 也有提供在 TensorFlow Hub、PyTorch Hub 上,已經訓練好的 model,再透過結合至 SageMaker Studio,讓使用者可以在找到適合的 model 之後,直接進行後續的動作。

圖片來源至:Amazon SageMaker JumpStart Simplifies Access to Pre-built Models and Machine Learning Solutions
Amazon SageMaker Clarify – 監測機器學習過程的偏差值以利了解 model 的推論行為
偏差值普遍存在於資料本身,像是人的年齡或收入在資料集裡的分佈不平均,就可能導致訓練出來的 model 只對特定年齡 / 收入的人做預測時,結果比較準確。除了資料本身的偏差值以外,有時也源自於演算法;運算的邏輯不同,可能增加或減少 model 預測的參考值,讓結果失真。
因此在 Machine Learning 的整個生命週期裡,每一個階段都可以重新檢視 model 的公平性與可解釋性,像是檢查初始數據的分佈、經過前處理後的結構、訓練後 model 的預測結果…等,都可能存在偏差。
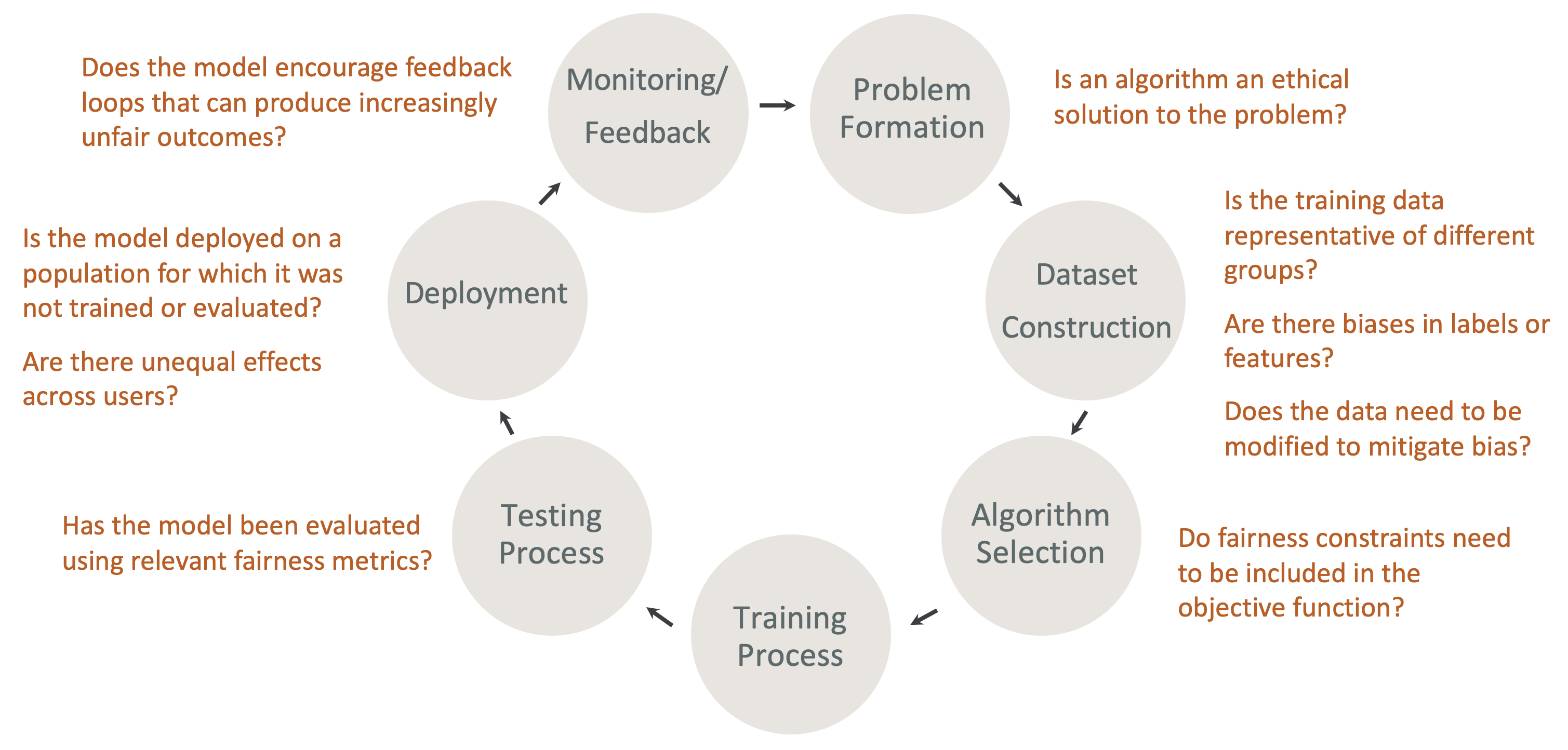
Amazon SageMaker Clarify 通過檢測潛在的偏差值來幫助改善使用者的機器學習模型,同時也有助於解釋 model 做預測的依據。SageMaker Clarify 除了可以在準備過程中,檢測數據是否存在偏差之外,也可以檢查訓練後的 model 是否因偏差而推論不佳,並持續監控存在偏差的可能性。
SageMaker Clarify 還包括功能重要性的比重圖,可幫助解釋 model 做預測的依據,讓使用者可以採取正確的措施予以糾正。

參考來源至:Detect bias in ML models and explain model behavior with Amazon SageMaker Clarify
Amazon Redshift 推出新功能
Amazon Redshift ML
去年底 AWS 推出 Amazon Athena ML 跟 Amazon Aurora ML 功能,廣受資料分析師、資料庫開發者及資料科學家喜愛,今天 AWS 也針對 Redshift 推出 Amazon Redshift ML 服務,幫助 Amazon Redshift 使用者可以使用 SQL 相容語法創建、訓練及部屬 ML 模型。結合 Amazon SageMaker 使用者就可以不用搬移資料也不用學習新技能就可以使用 AI 服務了。
Automatic Table Optimization
隨著時間的推移,資料庫中的資料也會越來越多,同時也會有一些資料被刪除,而資料庫中的資料被刪除後會讓 Distribution 跟 sort key 錯亂掉,造成執行 query 的效率變差。以往使用者需要定時手動重新排序,今天之後有了 Amazon Redshift Automatic Table Optimization 使用者只須要啟用這個功能即可達成自動化效能優化的需求。
參考來源至:Amazon Redshift announces Automatic Table Optimization
Data Sharing (preview)
許多企業常常在資料共享性與權限控管上會有互相矛盾,對於資料倉儲而言,很難做到僅讓某部分的員工存取某一部分的資料,以往為了共享這些資料,需要自行複製數據來源中的資料去另一處給其他人員存取,但除了很麻煩之外,儲存的成本也相當高。
此次更新後 RedShift 推出 data sharing 功能,讓使用者可以 real-time 跨 Redshift Cluster 共享數據(甚至是跨 Account 級別的共享),使用者也無需擔心權限問題,Data sharing 可以從 Schema、Table、Views 等不同層級來控管數據共享的權限。

Amazon Redshift 現在可與第三方平台的資料結合,並統一呈現在同一個 Console 畫面 (Preview)
RedShift 整合第三方合作軟體至主控台中,方便使用者更快速的選擇資料導入 RedShift 的方式,使用者若要啟用可以從 Redshift 主控台中的 Cluster Details 選擇任一第三方合作軟體(SalesForce、Google Analytics、Facebook Ads、Slack、Jira、Splunk 和 Marketo 等),選擇完合作夥伴後,會跳轉至該合作夥伴的設定頁面中,在那可以設定資料倒入至 RedShift 的相關設定(ETL、數據來源等)。
AWS 也歡迎其他第三方軟體加入此行列中,所以若想被整合至 RedShift 中可透過 redshift-partners@amazon.com 來諮詢。
參考來源至:Amazon Redshift announces native console integration with partners (Preview)
Amazon EMR Studio – 簡化 EMR 建構及部署程式碼過程的 IDE
Amazon EMR 是 AWS 處理大數據的服務,支援 Apache Spark、Apache Hive、Apache HBase、Apache Flink、Apache Hudi 和 Presto 來處理龐大的資料。
EMR Studio 是一個整合式開發環境(IDE),讓資料科學家可以更輕鬆地開發、視覺化和調用R、Python、Scala 和 Java based 的應用程式。
EMR Studio 可用 AWS SSO 的方式登入,也就是說使用者無需登錄(擁有) AWS 帳號。資料科學家可以自己安裝 Library,並使用 GitHub 和 BitBucket 等代碼存儲庫進行協作,或者使用編排服務(例如 Apache Airflow 或適用於 Apache Airflow 的 Amazon Managed Workflows)執行 Jupyter Notebook。
參考來源至:Amazon EMR Studio makes it easier for data scientists to build and deploy code
Amazon ECS 推出 Deployment Circuit Breaker (Preview)
當使用者利用 ECS Service 來部署應用程式時,常常會發生部署失敗的狀況。而起因有很多種可能,像是 Dockerfile 編寫錯誤導致 Tasks 執行失敗、環境參數設定錯誤…等程式編寫上的失誤,或是因為 Compute Layer 資源不足而無法順利啟用 Tasks。
在過去,當 ECS Service 啟用 Tasks 失敗時,會不斷的 retry,嘗試重新啟用,導致部署的動作停滯在 retry。而這時候,最令人擔心的其實是影響到系統表現,因此開發者會額外設置通知的機制,才能即時偵測到異常狀態。當 Fail 發生,就要盡快手動 debug,恢復正常。
現在,AWS 推出了 ECS Deployment Circuit Breaker (Preview),支援 EC2 和 Fargate 類型。通過此功能,ECS Service 現在會自動 rollback 不健康 (unhealthy) 的 Tasks 至上一個正常的版本,而無需手動操作,讓開發者能夠快速發現失敗的部署動作,也不必擔心因為部署失敗而浪費資源或讓系統產生延遲。
- 以下簡單做了一個測試:原先在 ECS 部署了一個 python app

- 透過 AWS CLI 來查詢 ECS Service 的狀態:
aws ecs describe-services --services ECS_SERVICE_NAME --cluster ECS_CLUSTER_NAME --query services[]

- 在修改 Dockerfile 之後,刻意造成 Container 無法成功啟用,也就會讓 ECS Service 部署新版應用程式失敗。持續查詢 ECS Service 狀態,會看到新版的 Tasks 呈現 Fail。

- ECS Deployment Circuit Breaker 會幫助開發者自動 rollback 到上一個可以正常運作的版本。

參考來源至:Amazon ECS Announces the Preview of ECS Deployment Circuit Breaker
Amazon VPC Reachability Analyzer – 簡化網路環境測試與偵錯的流程
通常使用者在開啟一個 VPC 環境時,需要設定許多在 VPC 內的元件,例如:IGW, NAT Gateway, Route Table, Security Group, NACL…等,不僅設定過程繁瑣,也容易因為不小心設錯,讓 VPC 內的資源無法彼此溝通或是失去連網能力。
這時候使用者就需要一個個檢查每項元件的設定,浪費使用者的時間。此次更新後,使用者可以利用 VPC Reachability Analyzer,分析阻斷連線的原因。VPC Reachability Analyzer 可以在 ENI、Gateway、Peering、Security Group、VPN Connection…等流量會經過的地方來做檢測,從簡易的圖表知道連線通過哪些位置。
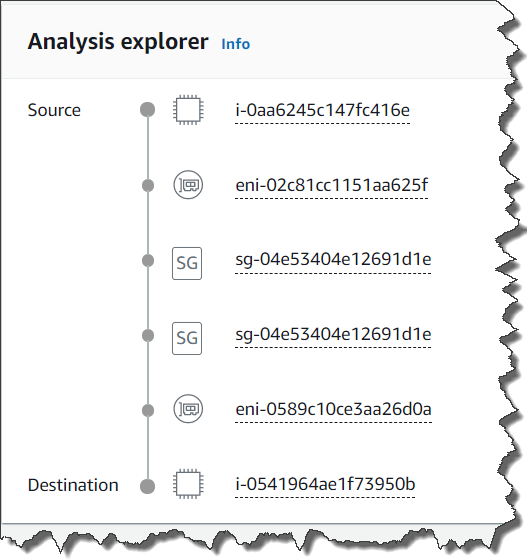
如果連線失敗,VPC Reachability Analyzer 也可以告知使用者是出於什麼原因導致連線失敗,並建議使用者解決方式,簡化偵錯的流程。

其他服務更新
Amazon Kendra 支援 Google Drive connector 與 incremental learning
Amazon Kendra 是一個基於機器學習的智慧搜尋服務,可以幫助使用者在大量資料中輕鬆地找出使用者想要的內容。這次 Kendra 新增了四項更動:
- 新增了對於 Google Drive 的支持,使用者就可以輕鬆的在 Google Drive、 Google Docs 跟 Google Slides 快速找出所需的檔案文件了。
- Amazon Kendra 將基於使用者的搜尋行為與回饋來不斷優化搜索結果,例如:某次使用者查詢了「X」文件,而 Kendra 會回傳多筆與「X」相關的文件或內容,但可能第三筆結果為最符合多數使用者需求的文件,所以他們點選了第三筆資料,Kendra 會從中學習,並再下一次相同查詢時將原先第三筆結果優先放置於最上方顯示。
- Amazon Kendra 支援自定義的同義詞。每個產業的專用術語皆不同,甚至不同組織之間也有不同的講法,使用這項新功能,Kendra 可以使用自定義的同義詞來做搜索、查詢,以提高搜索結果的準確性。
- 對於許多組織而言,資料通常以散亂的形式存儲在多個地方,例如:S3 Bucket、Microsoft OneDrive 等雲端解決方案;或是 Atlassian Confluence、GitLab 等儲存庫,以及 ERP、SAP 和 Slack 等平台。現在,Kendra 可以連結多個資料來源來做查詢,提高找到目標資料的速度。
參考來源至:Amazon Kendra adds Google Drive connector, Amazon Kendra launches incremental learning, Amazon Kendra adds support for custom synonyms, Amazon Kendra launches connector library
Amazon ECR 現在可以跨 Region 複製 Images 的功能
現今有越來越多應用程式是以 Container 為運算的基底,而為了保持應用程式低延遲的特性,開發者傾向在多個地點部署相同的架構,讓應用程式更加靠近不同地區的 end-user,或是達到高可用性。
而為了克服 Region 之間的隔離性,開發者需要在多個 Region 放置 image repository,不僅成本提高,在應用程式利用 CI / CD 做更版時,也要寫額外的程式碼,讓 image 推送到多個地方以觸發各 Region 的 pipeline,增加整個流程的複雜度。

現在 ECR 提供可以跨 Region 複製 images 的功能,讓開發者可以利用一個 docker push 指令,即可複製到多個 Region。不僅可以解決跨 Region、跨 AWS Account 複製 images 的困難,也可以作為備份、災難復原的機制。
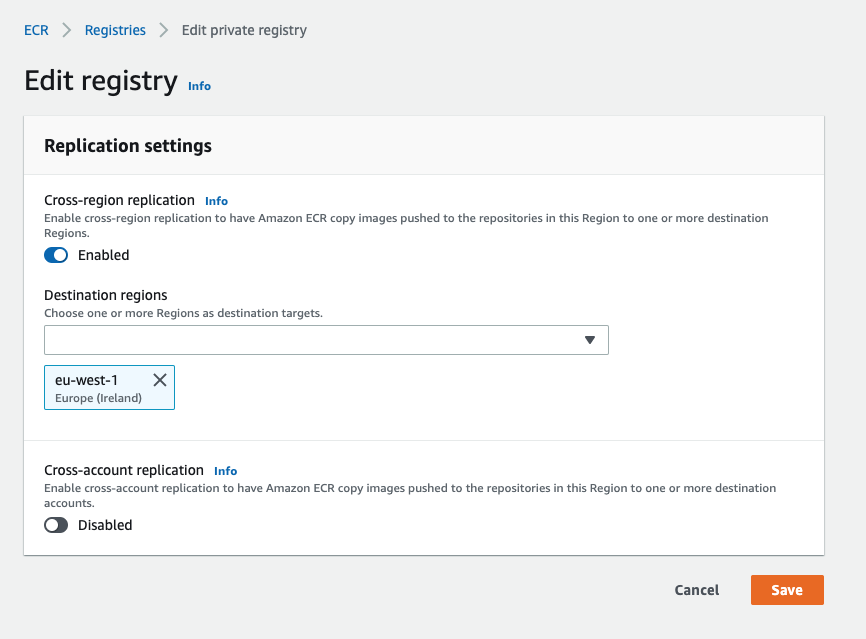
參考來源至:Amazon ECR announces cross region replication of images
Amazon Forecast Weather Index – 自動新增天氣資訊以優化預測的準確度
天氣狀況有時會改變消費者的消費意願,進而影響產品銷售決策、人員分配和能源消耗狀況,因此對於零售、旅行、娛樂、保險和能源領域的業者來說,天氣成了預測未來需求應參考的因素之一。
雖然天氣的歷史資訊可以幫助顯示出季節性需求,但要針對每日的天氣變化做出預測,就比較困難。除此之外,收集、整理和有效使用實時天氣資訊又是另一項挑戰,而且需要不斷維護系統狀態。
現在,AWS 推出 Amazon Forecast Weather Index,使用者可以自動地將當地最新的天氣資訊納入 Forecast dataset,提高 Forecast Predictors 預測準確性。

使用者在引入 dataset 時,dataset 裡必須包含地點相關資訊,例如:經緯度。接著,還需要選取時區 (time zone),或是讓 Forecast 直接從 dataset 中提取時區的資訊。
Tag:Amazon ECR, Amazon ECS, Amazon EMR Studio, Amazon Forecast Weather Index, Amazon HealthLake, Amazon Kendra, Amazon Lookout for Metrics, Amazon Neptune ML, Amazon Redshift, Amazon Redshift ML, Amazon SageMaker, Amazon SageMaker Clarify, Amazon SageMaker Edge Manager, Amazon SageMaker Feature Store, Amazon SageMaker JumpStart, Amazon SageMaker Pipelines, Amazon VPC Reachability Analyzer, Automatic Table Optimization, CI/CD, Data Sharing, Deployment Circuit Breaker, Edge Devices, EMR, Google Drive connector, incremental learning, PB
You may also like

【焦點新聞|Microsoft Build 2022】

【焦點新聞】0512-0525 AWS 服務更新
