

AWS re:Invent 2019 Day 2
Global Infrastructure
AWS Local Zone
从现在起 AWS Global Infrastructure 除了 Region、AZ 外,在 AZ 之下又多了 Local Zone (LZ),提供一个相对 AZ 又更贴近于使用者、延迟更低、响应速度更快的部署目标。
第一个 Local Zone (LZ) 为于洛杉矶,区域代号为 us-west-2-lax-1a ,提供使用者延伸 VPC Resources:EC2 Instances (T2, C5, M5, R5, R5d, I3en, G4)、EBS (io1, gp2)、FSx、ALB 至洛杉矶,更贴近当地 End-User,也将于 2020 在 LAX 洛杉矶部署第二个 Local Zone us-west-2-lax-1b。

相信未来全球各地会有更多的 Local Zone 出来,集结拓展为下一代基础建设。
参考来源至:AWS Local Zones
Instance Computing
New Instance Type: Ifn1, M6g, R6g, C6g
搭载 AWS Inferentia 晶片的 Inf1 Intstance,针对机器学习运算、成本做优化,和同等级运算效能之 G4 Instance 相比,成本约降低 40%。
搭载最新 Arm-based AWS Graviton2 Processor,和现行 x86-based M5/R5/C5 相比,效能约提升40%,约在 2020 Q1 GA。
- SPECjvm® 2008: +43% (estimated)
- SPEC CPU® 2017 integer: +44% (estimated)
- SPEC CPU 2017 floating point: +24% (estimated)
- HTTPS load balancing with Nginx: +24%
- Memcached: +43% performance, at lower latency
- X.264 video encoding: +26%
- EDA simulation with Cadence Xcellium: +54%
参考来源至:Graviton2-Powered General Purpose, Compute-Optimized, & Memory-Optimized EC2 Instances
AWS Compute Optimizer
在诸多 Well-Architect 案例中为了做效能优化、成本优化,时常透过 Monitoring 确定 EC2 Instances 运作情况、是否需要更换 Instance Type、是否 Over-provisioning 或是 Under-provisioning …等考量。
AWS Compute Optimizer 以机器学习方式分析 Account 中过往 EC2 使用状况,来源自 CloudWatch 所记录Metrics,不论是 Built-in Metrics 或者是透过CloudWatch Agent 推中之 Custom Metrics,进一步分析、判断 Instances 是否需要调整、可以升级/降级至哪个 Instance Type。


现已正式发布、并支援以下 Region:US East (N. Virginia), US West (Oregon), Europe (Ireland), US East (Ohio), South America (São Paulo)。
更重要的是此服务为免费使用!强烈建议若有部署 EC2 Instances 在支援 Regions,可以立即尝鲜看看效果。
参考来源至:Introducing AWS Compute Optimizer
AWS Outposts
在去年引起热烈讨论的 Outposts 终于正式发布!
机房管理员往往在维护、安装、更新实体伺服器花费许多心思、时间,现在只需要透过 AWS Console 选定规格、发送请求,AWS 便会到府安装并接手处理这些维运行为;若后续有要更新升级,也能透过 Console 提出申请。
使用须知如下:
-
支援服务:
- Nitro-basd EC2 Instance Type – C5, C5d, M5, M5d, R5, R5d, G4, I3en
- EBS – gp2
- ECS
- EKS
- EMR
- Amazon RDS for PostgreSQL (Preview)
- Amazon RDS for MySQL (Preview)
-
支援地区:
- North America (United States)
- Europe (All EU countries, Switzerland, Norway)
- Asia Pacific (Japan, South Korea, Australia)
-
Support Plan 须为 Enterprise
-
Billing & Payment Options – 须购买三年长度,付费方式有 All Upfront, Partial Upfront, and No Upfront,细节请参考 AWS Outposts pricing
参考来源至:AWS Outposts Now Available – Order Yours Today!
Container
Fargate for EKS !!
从 re:Invent 2017 发布 Fargate 时,便提及会同时支援 ECS & EKS 两大 Container 服务;等了两年的时间,终于正式 GA 支援 EKS!
在目前广为使用部署 EKS Cluster 的工具 eksctl 也及时发布版本更新,支援以 Fargate 作为 pods 的部署单位:
eksctl create cluster --name demo-newsblog --region us-west-2 --fargate
在 EKS Cluster Console 中也可以透过 Fargate Profile 宣告当 pods 部属时所需要的 Fargate 资源。
参考来源至:Amazon EKS on AWS Fargate Now Generally Available
Fargate Spot
AWS 现在正式推出 Fargate Spot,可节省高达 70% 的费用!
如同 EC2 Spot 的原理,AWS 运用可用的备用运算资源,当 Spot 的价格符合出价,可在 Fargate Spot Instance 上运行允许可被中断的任务,然而,当 AWS 将要收回该 Spot Instance 时,会有 2 分钟的警示时间。虽然 Spot Instance 随时有可能被收回,但 Fargate 仍会确保每个 Service 有最少常规数量的 Task 仍然运行中,以维持应用程式的高度可用性。
此外也可以搭配先前推出的 Savings Plans,作为成本估算的策略之一。
-
建议搭配 Fargate 来运行最低的常规使用量,其余可能额外、Scale 出来的用量使用 Fargate Spot 来填补,搭配两者使用以节省更多费用。
-
设定好 Cluster 內的 capacity provider strategy 后,执行 Run Task / Service,运行后可以在 Details 确认 Task Capacity Provider。
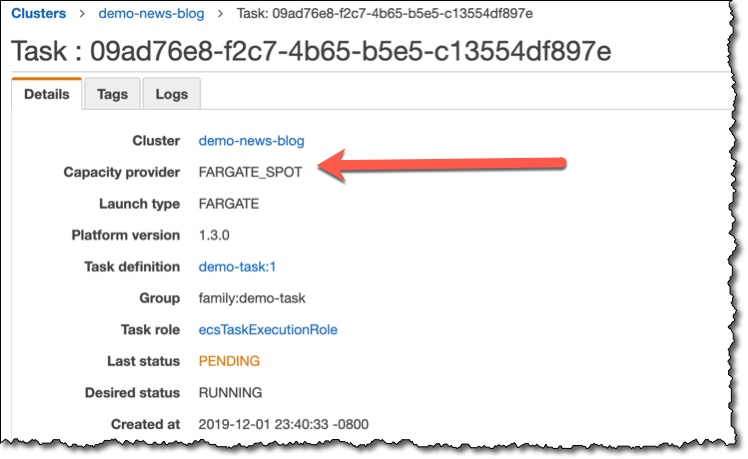
参考来源至:AWS Fargate Spot Now Generally Available
ECS Capacity Providers
以往可以使用 Launch Type 来控制 Task 是否使用 EC2 或Fargate,并且可以使用位置限制(placement constraints)和放置策略(placement strategies)来控制Task 的位置,但是,只有已经可用的容量,例如:已经运行的 EC2 Instance)才能用来执行Task,而且位置限制和策略也只会考虑已经可用的容量。
随着 Capacity Providers 的推出,可让应用程式定义容量使用方式的需求,并针对容器化工作负载如何在不同类型的运算容量上执行,定义弹性规则,以及管理容量扩展。
Capacity Providers 支援 EC2 及 Fargate 型态。若用使用 EC2 类型,可指定 Auto Scaling Group 作为 Capacity Providers,确保即使尚未可用,仍需要执行工作所需的容量;若使用 Fargate 类型,则可指定 Fargate 和 Fargate Spot。此外,也可以预先定义执行 Task 的分割百分比,或确保服务在多个可用区域中执行相同数量的任务
- 在 Cluster 中可以从 Capacity Provider 看到 Cluster 内能使用的类型,并点击右上角的 Update Cluster 来设定 Capacity Provider strategy。若使用的是 EC2 类型,则可点击 Create,用特定 ASG 来创建 Capacity Provider。
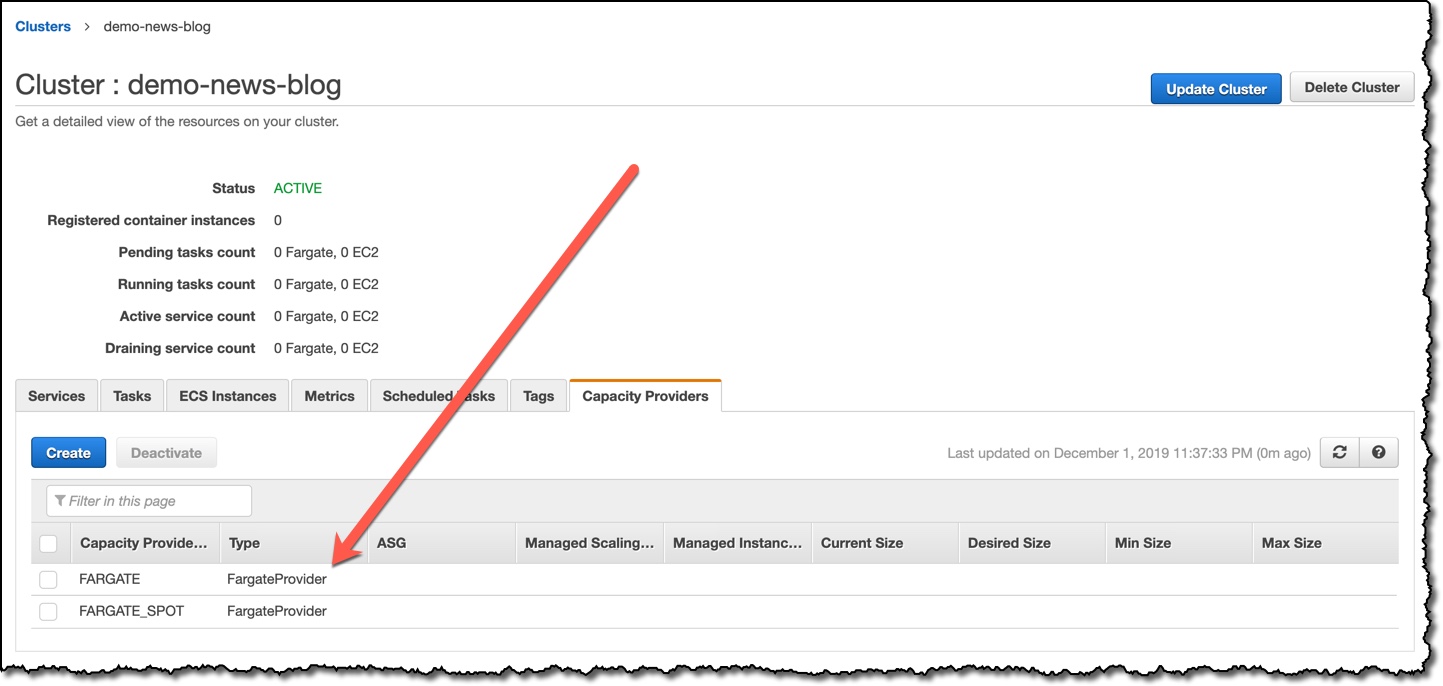
- 若使用的是 Fargate 类型,可在同一个 Cluster 内,同时使用 Fargate 或 Fargate Spot,并可设定 weight 来指定运行时的比例;或是设定 base 来指定该种 Capacity Provider 最低运行的数量,但一个 Cluster 中,只有一个 Capacity Provider 的 base 可设定大于 0。

-
如为现有 Cluster,须先透过
aws ecs put-cluster-capacity-providers更新 Default Capacity Provider,再透过aws ecs update-service --force-new-deploymeny强制重新部署既有 ECS Service## Update cluster capacity providers with Fargate and Fargate Spot aws ecs put-cluster-capacity-providers \ --cluster cluster_name \ --capacity-providers FARGATE FARGATE_SPOT \ --default-capacity-provider-strategy capacityProvider=FARGATE_SPOT,weight=1 \ --region us-west-2 ## Update services run with Fargate and Fargate Spot aws ecs update-service --capacity-provider-ttrategy capacityProvider=FARGATE_SPOT,weight=1 --force-new-deploymeny
参考来源至:Amazon ECS Capacity Providers Now Available
参考来源至:Documentation – Amazon ECS Cluster Capacity Providers
ECS Cluster Auto Scaling
以往,ECS 无法直接管理 ASG 的扩展,使用者必须在 ECS 之外手动设定 ASG 的扩展原则,而可用于缩放的数量并未考虑所需的工作计数,只考虑正在执行的工作。透过 ECS Cluster Auto Scaling,使用者可以设定 Capacity Providers 以启用 ASG 的管理扩展、保留 ASG 中的多余容量,以及管理 ASG 中执行个体的终止。
参考来源至:Amazon ECS Cluster Auto Scaling Now Available
Serverless
Step Functions Express Workflows
Express Workflows 是一种新型的 AWS Step Functions 工作流类型,它以符合成本效益的方式协调 AWS 运算、资料库和讯息服务,每秒超过 100,000 个事件。Express Workflows 自动启动以响应事件,例如通过 Amazon API Gateway 发出的 HTTP 请求,AWS Lambda 请求,AWS IoT 规则引擎操作以及 Amazon EventBridge 中的 100 多个其他 AWS 和 SaaS 事件源。Express Workflows适用于大批量事件处理工作负载,例如 IoT 数据提取,串流数据处理和转换以及大量微服务协调流程。
参考来源至:Introducing AWS Step Functions Express Workflows
Lambda Provisioned Concurrency
当 Lambda Function 一段时间未使用,需要处理并发 Request 或更新 Function 时,Lambda 会重新布建执行环境。执行环境的布建时间会根据 Lambda Function Package 大小、不同的 Runtime 而影响,导致 Request 路由到执行环境时产生「Latency」,这种等待时间通常称为「Cold Start」,对于大部分使用场景可能会进而影响到使用者体验。
在 Lambda Console 针对 Lambda Function Version/Alias 指定 Provisioned Concurrency 数量,Provisioned Concurrency 可以使 Function 保持 initial 状态,并且可以随时响应,大幅度地降低 Provision Latency,减少原先结构会有的 Cold Start 问题发生。

比较设置 Provisioned Concurrency 前后的回应时间如下图:

参考来源至:AWS Lambda announces Provisioned Concurrency
图片来源至:New – Provisioned Concurrency for Lambda Functionst
Storage
EBS direct APIs
透过适用于 snapshot 的 EBS direct APIs,可以直接读取 snapshot 的状态并取得两个 snapshots 之间的差异,而无需另外建立 EBS volumes 和 EC2 Instamces 来看两者的不同。
当使用者运用 EBS snapshot 来备份 EBS volumes 时为 Incremental Backup,每一次的备份都只会储存相较于前一份 EBS snapshot 有变更的 Blocks。然而当需要使用 snapshot 来复原 volumes 时,会自动侦测较旧的版本,并将较新变更的 Blocks 覆盖上去,概念如下图:
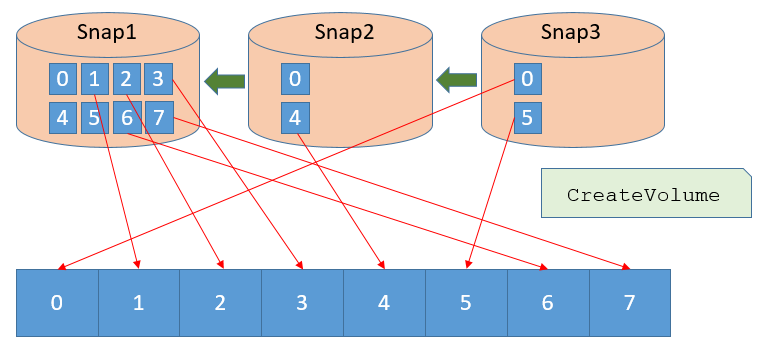
有了 EBS direct APIs 后,可以透过 ListSnapshotBlocks 来了解 snapshots 的变更纪录。以上图为例,若对 Snap1 做呼叫,会回传 [T0, T1, T2, T3, T4, T5, T6, T7],若对 Snap2 呼叫,则会回传 [T0, T4]。
此功能可让使用者轻松取得 EBS volumes 的变更资讯,并使其能够实现更快(缩短高达 70% 的备份时间)、更精细(达到更准确的 recovery point objectives)且更低成本的备份。
图片来源至:New – EBS Direct APIs – Programmatic Access to EBS Snapshot Content
S3 Access Points
当使用者的同一个 S3 Bucket 拥有许多的权限控制的 Bucket policy 时,对维运人员来说是一件非常头痛的事情,当我们只想修改其中一项存取权限时,深怕会动到其他项目,因此 S3 Access Points 便是一个很好的解决方案,我们可以针对不同对象或应用程式新增 access point,并个别设定针对这些对象的使用权限,以做到个别控管。
任何 S3 Access Points 都可以限制在 VPC 中,以在私有网路中保护 S3 的资料,而 AWS Service Control Policies 可以用来确保组织中的所有存取点都受到 VPC 限制。
参考来源至:Easily Manage Shared Data Sets with Amazon S3 Access Points
UltraWarm(Preview)
Elasticsearch 作为 ELK 代表性服务,针对各种不同的 Logs 做视觉化处理加以分析效能、安全性、察觉是否有潜在危害的发生。使用者却在 Logs 的存储策略上遇到容量的限制、成本的考量、保存期限…等问题,进而影响到使用 Elasticsearch 的成效。
UltraWarm 作为专为 Elasticsearch 存放 Logs 的存储服务,相比现行架构,最高可以节省至 90% 的存储成本。
在 Elasticsearch Cluster 中,把”Hot” Data 存放至 Cluster Data Node 的层级,其余 Data 转存至 S3 中并透过 UltraWarm Node 存取,大幅度地降低 Data Node 的存储空间,也同时解决了 Storage Scale 的需求且能对应上 S3 优越的 Durability 能力。
参考来源至:UltraWarm Storage for Amazon Elasticsearch Service (Preview)
AI
Amazon Kendra
Amazon Kendra 是由机器学习且易于使用的企业搜索服务,开发人员可以在应用程式中添加搜索功能,以便发现存储在整个公司的大量内容中的信息。这包括来自手册,研究报告,常见问题解答,HR 文档,客户服务指南的数据,可在各种系统中找到,例如:文件系统、网站、Box、DropBox、Salesforce、SharePoint、Amazon S3 等。输入问题时,该服务将使用机器学习来了解上下文并回传最相关的结果,无论是精确答案还是整个文档。例如:使用者可以问:『公司信用卡上的现金奖励是多少? 』,Amazon Kendra 将搜索到相关文档并回传像是『2%』之类的特定答案。
Amazon Kendra 经过最佳化,可从特定领域(例如:IT、制药、保险、能源、工业、金融服务等)找到准确的答案。Kendra 的机器学习模式会透过撷取最终使用者搜寻模式和回馈来定期更新,让 Kendra 的相关性能与企业的资讯趋势保持一致。
参考来源至:Amazon Kendra
Amazon Rekognition 新增客制化标签训练
Amazon Rekognition 客制化标签训练提供训练特定的影像分析模型,用以辨识特殊物件与场景。此功能可以训练带有少量标签图像的模型,以检测机器零件的需求为例,在原先 Amazon Rekognition 所提供的辨识物件功能,对于所有这些图像,Amazon Rekognition 将标签为 “机器零件”。 
而透过 Amazon Rekognition 自定义标签,使用者可以训练自己的自定义模型来识别特定的机器零件,例如涡轮增压器,变矩器等,但须先收集并上传各个零件 10 张图片作为训练模型辨识的资料,并在 Console 中为每个物件进行标签。

图片上传方式:
- 汇入已由 SageMaker Ground Truth 标签完成之资料
- 使用 S3 储存桶之图片
- 使用先前使用客制化标签训练的资料集副本
- 从本机上传
当资料集上传并标记完成后,便可执行自定义标签动作,Amazon Rekognition 会针对每个用例自动选择最有效的机器学习技术。使用者可以查看每个模型的性能,并获得有关如何进一步改进其模型的建议。

以下为使用 Amazon Rekognition 物件辨识与 Amazon Rekognition 自定义标签之结果比较。

文章參考至:AWS launches Amazon Rekognition Custom Labels to enable customers find objects and scenes unique to their business in images 参考来源至:Announcing Amazon Rekognition Custom Labels
Amazon Fraud Detector
此次 AI 更新的服务 Fraud Detector 是一个全托管,可识别潜在的诈欺性在线活动的服务,例如在线支付的诈骗和创建假账户。利用机器学习和来自 AWS 和 Amazon.com 的 20 年欺诈检测专业知识,以毫秒为单位自动识别潜在的欺诈活动。
参考来源至:Amazon Fraud Detector FAQs
Amazon CodeGuru
Amazon CodeGuru 为新的 AI 服务,是一个全托管的代码检测服务,可识别程式码的严重缺陷(例如:敏感数据的不当处理和资源泄漏)和基于 Java 的 AWS 最佳实践偏差,同时标记可能导致生产问题的常见问题(例如:侦测缺少分页或批次操作的错误处理),并提供如何修正或改善程式码的智慧建议,目前支援 GitHub 与 CodeCommit。
参考来源至:Amazon CodeGuru FAQs
Machine Learning
Sagemaker Studio
此次最重大的更新莫过于在机器学习领域中的 Sagemaker 有了重大的改变。
宣布了一个整合式的机器学习 IDE,里面包含: 用于机器学习(ML)的网页整合式开发环境(IDE),使用前须先拥有 IAM 权限才能够使用此服务。此服务拥有 AWS 自己的 Notebooks 名为 Sagemaker Notebooks(预览阶段),可以轻松地创建和共享 Jupyter Notebooks。
第二个是 SageMaker Experiments,可以针对每次的训练作业进行一次性的比较,以评估哪一次的训练最为有效,并可以迅速的部署此模型。当我们在训练模型时难免会遇到问题,SageMaker Debugger 会自动检查训练的模型,并收集数据进行分析,以提供实时通知和建议,SageMaker Model Monitor 可以检视已部署模型的质量偏差(部署结果)并接收警报,最后则是在机器学习中,选择算法是一个非常困难的问题。特别是要选择和掌握可以解决问题的最佳模型。机器学习算法通常需要大量的训练参数,这些参数需要设置通常经过多次修正与训练才能得知最适合的值,以缩小模型的准确性。
使用者需要呼叫一次 API 或在 Amazon SageMaker Studio 中点击几下,SageMaker Autopilot 首先检查数据集并创建许多数据预处理步骤,机器学习算法和超参数运行测试。然后,可以使用这种组合来训练管道,并将其部署到实时端点或批次处理。

此图为此次更新后于 Sagemaker 服务中的功能对应简图。
参考来源至:ついにSageMekerの統合環境が登場!「SageMaker Studio」が発表されました #reinvent
Amazon Augmented AI (Preview)
多数机器学习应用程序要求人工审核员检查具有较低可信度的预测以确保结果正确。例如,在某些情况下,由于扫描质量低或笔迹较差,从人工扫描的申请表中提取信息可能需要人工审核。但是建立人工审核系统往往耗时又昂贵,因为涉及复杂的工作流程、编写自定义软件来管理审核任务和结果,以及在许多情况下管理大量人工审核员。
Amazon A2I 为常见的机器学习应用提供了内建的人工审查工作流程,例如内容审核和从文档中提取文本,从而可以轻松地审查来自 Amazon Rekognition 和Amazon Textract 的预测,还可以为基于 Amazon SageMaker 或任何其他工具的 ML 模型创建自己的工作流程。使用 A2I,使用者可以允许人工审核员在模型无法做出高可信度预测时进行干预,也可以持续审核其预测。

参考来源至:Announcing Amazon Augmented AI: Easily Implement Human Review for ML Predictions
Database
Amazon Managed Apache Cassandra Service (MCS)
除了 Amazon DynamoDB 及去年 re:Invent 发布的 Amazon DocumentDB (with MongoDB compatibility) 的 NoSQL Database Solutions,今年又发布以 Apache Cassandra 为托管对象的 Amazon Managed Apache Cassandra Service (MCS)。
跟 DynamoDB 一样为 Serverless 服务,使用者仅需为实际使用量付费、依据负载状况做自动化扩展 AutoScaling 以确保 Tables 的运作效能,在使用上也是透过 Cassandra Query Language (CQL) 和 Tables 互动。
对于使用场景不易搬迁至 DynamoDB / MongoDB 的使用者是一大福音!
现正以 Open Preview Regions:
- US East (N. Virginia)
- US East (Ohio)
- Europe (Stockholm)
- Asia Pacific (Singapore)
- Asia Pacific (Tokyo)
参考来源至:Amazon Managed Apache Cassandra Service (MCS)
RDS Proxy (Preview)
以往应用程式会与资料库建立 Connections 以传输并取得资料,这些 Connections 会消耗资料库 Memory 和 CPU 资源。许多应用程式包括现代无伺服器架构上的应用程式,都开启大量资料库 Connections、对资料库造成压力,从而导致资料库性能降低和应用程序可伸缩性受限。
RDS Proxy 建立并管理与资料库的必要 Connections Pools,以便应用程序创建较少的数据库 Connections。RDS Proxy 支援 Auto Scaling,使 DB Instances 不需要耗费额外资源来进行 Connections 管理,同时透过 Connections Pools 来提高性能。发生故障时,RDS Proxy 会自动连线至 RDS Standby Instance、同时保留应用程式的连线,并将 RDS 和 Aurora 异地同步备份资料库的容错移转时间降低高达 66%。

使用 RDS Proxy,可以透过 AWS Secret Manager 和 AWS IAM 管理资料库登入资料和存取,无需在应用程式程式码中嵌入资料库登入资料。

参考来源至:Introducing Amazon RDS Proxy (Preview)
图片来源至:Using Amazon RDS Proxy with AWS Lambda
Amazon Redshift Federated Quering (Preview)
此功能推出后使用者便能跨资料库、数据仓库(Data warehouse)、资料湖(Data lake)快速的查询资料,目前使用者可以实时查询 Amazon RDS for PostgreSQL、Amazon Aurora PostgreSQL 中的资料,也可以和现有 S3 当中的表进行联合查询并汇整成新的一张 Data Table。
CREATE EXTERNAL SCHEMA IF NOT EXISTS online_system
FROM POSTGRES
DATABASE 'sales_db' SCHEMA 'system'
URI 'my-hostname' port 5432
IAM_ROLE 'iam-role-arn'
SECRET_ARN 'ssm-secret-arn';
可以使用此语法将 RDS 或 Aurora PostgreSQL 资料库添加到 Redshift 丛集。
通过 Redshift Federated Quering 便可以直接从 Redshift 连接到 RDS、S3 中并执行处理 ETL / ELT 的查询。
参考来源至:Amazon Redshift introduces support for federated querying (preview)
Amazon Redshift RA3 instance nodes
RA3 执行个体建立在 AWS Nitro 系统上,具有高频宽网络、高性能 SSD 作为本地缓存,同时可自动储存到 S3,与大多数使用者用的 Dense Storage(DS2)执行个体相比,可以用相同的成本获得 2 倍的性能提升和 2 倍的储存容量。 另外 RA3 和现行架构、用法完全一致,使用者可以直接 透过快照方式将工作负载无痛移植到 RA3 节点上。

Announcing Amazon Redshift data lake export: share data in Apache Parquet format
现在可以将 Amazon Redshift 查询的结果作为 Apache Parquet 卸载到 Amazon S3 数据湖,Apache Parquet 是一种高效的开放式列式存储格式,用于分析。与文本格式相比,Parquet 格式的卸载速度提高了 2 倍,并且在 Amazon S3 中消耗的存储量减少了 6 倍。这让使用者能够以 Parquet 开放格式将在Amazon Redshift 中完成的数据转换和充实保存到 Amazon S3 数据湖中,再透过 Redshift Spectrum 和其他 AWS 服务(例如 Amazon Athena、Amazon EMR 和 Amazon SageMaker)分析数据。

使用者可以指定一或多个分割区栏,以便自动将卸载的资料分割到 Amazon S3 Bucket 中。例如可以选择卸载行销资料,并按年、月和日资料行进行分割。这可让您的查询利用磁碟分割修剪和略过扫描非相关的磁碟分割,改善查询效能并将成本降至最低。
参考来源至:New for Amazon Redshift – Data Lake Export and Federated Query
Networking & Content Delivery
AWS Wavelength
AWS Wavelength 可将 AWS 服务与 5G 网路连结,让开发人员以不到 10 毫秒的超低延迟效能交付应用程式到各种移动装置和终端使用者们,对于未来运用在游戏、直播串流或 AR/ VR将会达到更好的成效。
目前支援的电信商与区域: * Verizon in North America * Vodafone in Europe * SK Telecom in South Korea * NTT Docomo, and KDDI in Japan
参考来源至:AWS Wavelength
Transit Gateway Network Manager
大多数全球网络都包含位于 Cloud 以及一个或多个 On-Premise 组成混合资源。若要监控整个全球网路,通常必须将云端资料和内部部署整合在一起,这会导致不一致的管理与监控体验。
Transit Gateway Network Manager 集中管理和监视整个AWS和本地的全球网络,降低了跨 Regions 和远程位置管理网络的操作复杂性
在 Network Manager Console 中,可以从 VPC Transit Gateways 部分中看到全球网路的概观,为所搭建的 AWS Transit Gateways、通过 Site-to-Site VPN Connection 连接到 Transit Gateways 的实体设备和网站以及连接到 Transit Gateways 的 AWS Direct Connect 位置提供了集中管理点。
![]()
并且可以选择地图上的任何节点以获取详细资讯,包括所有 VPN Connection、VPC 和所选 Transit Gateway 处理的 VPN 的状态。
![]()
在 Topology 面板中,可以查看网络中所有资源的逻辑关系,选择图中的任何节点都会显示特定于资源类型的详细资讯,如Transit Gateways、VPC、Customer Gateway…等。 ![]()
Network Manager 使用 Amazon CloudWatch 收集原始数据并将数据输入/输出、丢包和 VPN 连接状态处理成可读、即时的指标。
这些统计资讯将保留 15 个月,以便访问历史纪录并更好地了解 Web 应用程序或服务的性能,亦可设置警报,以监视某些阈值,并在达到这些阈值时发送通知或采取措施。 ![]()
参考来源至:New for AWS Transit Gateway – Build Global Networks and Centralize Monitoring Using Network Manager
VPC Ingress Routing
以往若使用者想要让 Cloud 环境套用与地端 On-Premise 相同的资安政策,如:IPS/IDS 或其他防火墙的设置,需要先将流量导回 On-Premise 做检查,再路由回到 Cloud 环境,这不仅增加延迟时间,也让过程变得更加复杂。
VPC Ingress Routing 有助于整合第三方的 IPS / IDS 或其他防火墙解决方案,以帮助针对网路七层中 应用层 的防护。
EC2 上的 Security Group 是针对网路层、传输层的防护。
VPC Ingress Routing 透过创建一台 Appliance Instance 作为流量检查角色,将经由 IGW 或是 VGW 进来的流量,优先导流到 Appliance Instance 上做检查,再转到终端的 Application Instance。如此一来相较于使用 AWS WAF,已经习惯使用某一种第三方防火墙软体,可以在 Cloud 使用与 On-Premise 一样的解决方案。
以前不支援将 Route Table 套用至 IGW,所有进入 IGW 的请求,会直接进入到 VPC Subnets 或是直接到 ELB,而无法路由到特定的目的地。现在可为 IGW 客制化路由表,将进入到 VPC 的请求路由到特地目的地。
如下图,搭建好 Cloud 环境后,可开始设定各个 Route Table:

-
为了让流量先导至 Appliance Instance,需做以下设定:
- 将路由表附加到 IGW(10.0.1.0 子网的 CIDR 路由到 Appliance Instance 的 ENI)
- 更改公共 10.0.0.0/24 子网的路由表(将 0.0.0.0/0 路由更改为 IGW)
- 更改公共 10.0.1.0/24 子网的路由表(将 0.0.0.0/0 路由更改为 Appliance Instance ENI)
- Disable Appliance Instance Source/Destination Check,Appliance Instance 才会将封包转到 Application Instance。
-
完成设定即可变成以下架构,即使放置了防火墙,IDP / IPS 等,也可以通过简单的通信路径进行设置。

参考来源至:IGWとVGWにルートテーブルをアタッチ!全ての通信をEC2経由へ。サードパーティIDS製品などの通信をシンプルに #reinvent, New – VPC Ingress Routing – Simplifying Integration of Third-Party Appliances
Accelerated Site-to-Site VPN Connections
现在可以自由选择是否在 Site-to-Site VPN connection 启用 Accelerate,加速 VPN connection 的存取速度。
Accelerated VPN connection使用了去年发布的 AWS Global Accelerator,让 On-Premises 装置点路由至 AWS edge location (PoPs) 进而取代掉相对较远的 VPC VGW 端点,获得较低的连线 Latency,加速整体的连线速度。缩短之间连线的距离,也能降低因 Public Internet 会有的网路顺断导致 VPN Connection 断开的可能性发生。
参考来源至:Accelerated Site-to-Site VPN Connections
Multicast on Transit Gateways
在 AWS 上原先不支援 Broadcast 和 Multicast 的通讯方式,以往使用者若有相关需求,需要自行在 VPC 上以 EC2 做覆盖网路 (Overlay network) solution 虚拟出 Multicast。
现在可以透过 Transit Gateways 支援串接 VPC Subnets 之间以 Multicast 作联系。
Multicast domain:
- 建立 Multicast 网路环境
- 选择要作为 Multicast Router 的 Transit Gateway
- Assocaiate VPC Subnets 至 Multicast domain
Multicast group
- 建立 Source 作为 Multicast Sender、或是作为 Multicast Receiver
- Multicast group IP 为 IPv4 class D:224.0.0.0/4 * Group 成员为 EC2 Instance ENIs
Multicast source
- 发送 Multicast 的 EC2 Instance ENI
Multicast group member
- 接收 Multicast 的 EC2 Instance ENIs 集群
参考来源至:Amazon Transit Gateway
Transit Gateway Inter-Region Peering
AWS Transit Gateway 现在支援在不同 AWS Region 中的 Transit Gateways 之间建立 Peering Connection。使用 Inter-Region Transit Gateway 对等传输的流量始终停留在 AWS 全球网络上,并且永远不会遍历至 Public Internet,从而减少了威胁媒介,例如常见漏洞利用和 DDoS 攻击
参考来源至:AWS Transit Gateway now supports Inter-Region Peering
Security
Amazon Detective
Amazon Detective 是一项新服务,协助使者用轻松分析,调查和快速确定潜在安全问题或可疑活动的根本原因。Amazon Detective 会自动从 Accounts 中收集日志数据,并使用机器学习,统计分析和图论来构建一组连结的资料,使能够轻松地进行更快,更有效的安全调查。
Amazon Detective 可以分析来自多个资料来源的数兆个事件,如 VPC Flow Log、AWS CloudTrail 和 Amazon GuardDuty,并自动建立资源、使用者和它们之间随着时间的互动检视。有了这个统一的检视,在一个地方视觉化所有的详细资料和内容,以找出结果的根本原因,向下钻研相关的历史活动,并快速确定根本原因。
参考来源至:Introducing Amazon Detective
Business Applications
Contact Lens for Amazon Connect
是一个通过机器学习并支援 Amazon Connect 的服务,使客服中心主管和分析人员能够了解其客户对话的内容,情感和趋势,从而确定关键客户反馈并改善客户体验,客服中心每天都会接收到大量的客户讯息,从而导致数百万小时的通话记录。公司希望能够在所有电话中进行搜索,以识别问题,共同主题和代理商指导的机会。他们可以使用现有的联络中心分析产品,但是这些工具价格昂贵,提供通话记录的速度很慢,并且缺乏所需的记录准确性。这使得难以快速检测到客户问题并向其代理商提供可操作的性能反馈。现有工具无法提供实时分析,也就是客服人员无法在挂断电话之前识别和帮助这些沮丧的客户。而现在可以透过 Contact Lens for Amazon Connect 来实时判断客户当下情绪,并快速搜索客户常建主题以及多项有利于客服人员之功能。
Tag:Accelerated VPN connection, AI, Amazon Augmented AI, Amazon CodeGuru, Amazon Detective, Amazon Fraud Detector, Amazon Kendra, Amazon Redshift Federated Quering, Amazon Rekognition, API, AWS, AWS Compute Optimizer, AWS Local Zone, AWS Outposts, AWS Wavelength, Contact Lens for Amazon Connect, Container, Database, Dense Storage, EBS, ECS, ECS Cluster Auto Scaling, EKS, Fargate, Fargate Spot, Instance Computing, Lambda, Machine Learning, Multicast on Transit Gateways, RA3, reinvent, S3 Access Points, SageMaker Ground Truth, Sagemaker Studio, Security, serverless, Storage, Transit Gateway, UltraWarm, VPC Ingress Routing
You may also like

【焦點新聞|Microsoft Build 2022】

【焦點新聞】0428-0511 AWS 服務更新
