

【每周快报】0423-0428 AWS 服务更新
前言
继上周非洲区域启动后,这周欧洲- 米兰区域也正式启动了!目前为止欧洲已经有 6 个区域,其中意大利有高达 5 个 edgelocation,意大利终端用户也获得了更好的服务体验。
从去年七月开始,AWS 陆续为多项服务推出 Preview 版本,这些服务在这周都正式 GA 了!包含让用户更方便监控应用端点的 Amazon CloudWatch Synthetics、方便用户将多个 AWS 服务与 Slack 频道或 Amazon Chime 聊天室整合的 AWS Chatbot,以及全托管 Apache Cassandra 兼容数据库服务- Amazon Keyspaces!
这周我们还会介绍AWS新推出的Amazon AppFlow,这项服务让用户快速整合散布在各平台的数据,且为了确保数据的安全性,数据会先加密再利用AppFlow传输。 新服务的推出外,AWS也对许多其他服务做了改善,像是大数据方面,AmazonRedshift、、Amazon Kinesis Data Firehose 及 AWS Glue 这周新增了些支持。 上述服务外,文中也将提及 AWS Storage Gateway、AWS Config、AmazonEKS 等多项服务。
一、焦点新聞
AWS 添加 Europe (Milan) Region
现在欧洲 – 米兰区域正式启动!正式名称为 Europe (Milan),缩写为 eu-south-1 ,为 AWS 第 24 个区域,由三个 AZ 所组成,全球可用区的数量也来到 76 个!
目前欧洲 – 米兰区域支持大部分的服务,详细请见 Region Table – Europe。
至今 AWS 在欧洲已经有 6 个区域,在意大利更是有 5 个 edgelocations,随着米兰区域的开放,可帮助更多位于意大利的终端用户获得更好的使用体验!
新推出 Amazon AppFlow 服务
Amazon AppFlow 是一个能够帮助整合第三方 SaaS 平台上数据的服务,例如:Slack、DataDog、GoogleSlack、DataDog、Analytics 等 13 个第三方应用程序。
近年来,有越来越多用户开始使用 SaaS 的服务,但可能会因为需要不同类型的服务而选择不同家供应商,使得数据散布在多个平台上。当团队企图搜集这些资料,放到 AWS 以做后续分析时,用户需要花费不少的时间及人力把资料整并在一起,甚至在数据传输的过程中,可能发生资料窃取的情况,造成损失。还有一种常见的情况是数据格式不一致,就会需要另外经过 ETL 的过程来清除转换成能够直接分析的形式。
现在使用 AppFlow,可以在 AWS 与第三方应用(例如:Salesforce、Zendesk、ServiceNow 等等)之间串接起 data flows,快速的整合散布在各处的资料。同时,为确保数据的安全性,数据会优先加密再利用 AppFlow 传输。另外,如果第三方应用程式有支持 AWS PrivateLink,,AppFlow 会自动使用 AWS 内网传输,减少资料因暴露在公有互联网而遭受到网络攻击的机会。
此外,AppFlow 现在支持 On Demand、Event-based、Scheduled(排程)的方式触发,用户可设定针对临时的需求或是定期的日常工作来进行数据整合的工作;也可以使用 CloudTrail 监控 AppFlow API 呼叫的相关讯息。
- AppFlow 默认启用加密的服务,用户可设置使用 Default KMS Key 或是自行创建一把 Key。

- AppFlow 目前支持的 source 有 13 种,未来可能会继续新增。

- 假设用户希望取用 Slack Workspace 里聊天信息,需要先链接 Slack 帐户信息至 AppFlow。

- 将数据放置 S3 后,可再利用 Athena 分析,并结合 QuickSight 做图表分析。
- 当前 AppFlow 支持的 Destination 仅有 Amazon Redshift、Amazon S3、Salesforce、Snowflake。

使用 AppFlow,会根据使用的 data flow 数量收费,以及目的地的储存费用。
参考来源至:Introducing Amazon AppFlow 图片来源至:New – Announcing Amazon AppFlow
正式推出 Amazon CloudWatch Synthetics
CloudWatch Synthetics 功能在去年的 11 月推出 Preview 版本,这是一款让使用者更方便监控应用程序端点的功能,你可以透过它每分钟去监控你的 RESTAPI、URLURL 和网站内容,侦测是否有遭到恶意攻击,例如:网络钓鱼、SQL Injection和 XSS 攻击,一旦有不正常的状况发生时会实时发出提醒,以便快速修复。
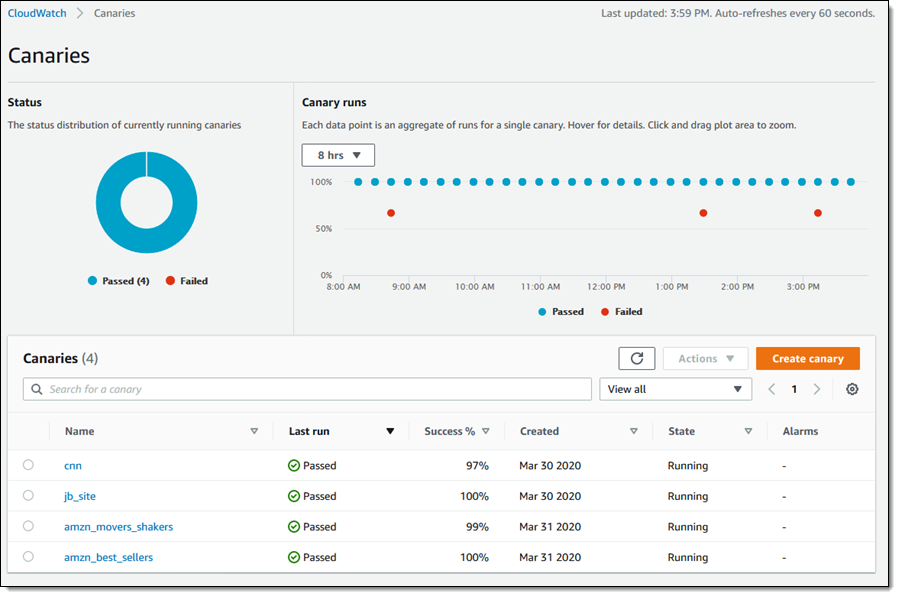
在这个功能底下,有一个核心组件– Canaries,如果你想要监控网站,必须要先建置 Canaries 才能运行,当你成功建置完成后,你可以从 Console 上看到你所建置的 Canaries 所运行的状况:
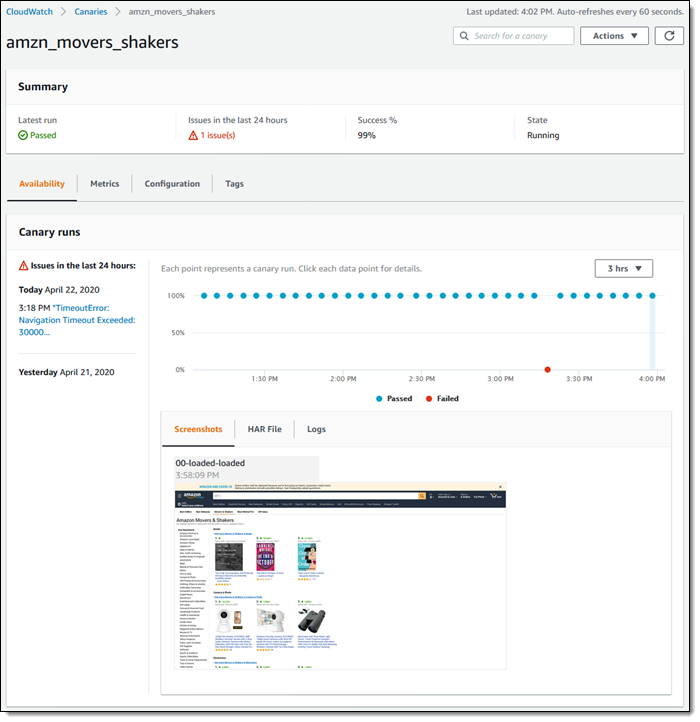
点击其中一个 Canaries,你可以看到更详细的讯息,像是在每个时间点测试成功或失败的图表、上一次测试的结果、在 24 小时内是否有任何问题、已经测试成功的比例:
现在 Free Tier 提供每个月前 100 个 Canaries 使用,而付费模式每个 Canaries 为 $ 0.0012 (以 Virginia 为例)。
参考来源至:Amazon CloudWatch Synthetics is now generally available
正式推出 AWS Chatbot
AWS Chatbot 已于 2019年 7 月推出,但一直处于 Preview 的阶段,现在终于正式推出了!
AWS Chatbot 是一个能够让用户将多个 AWS 服务与 Slack 频道或 Amazon Chime 聊天室整合的服务,以利在 ChatOps 的情境下使用。用户可以把 CloudWatch Alarm 及 CloudWatch Event 推送至 Slack 频道或 Amazon Chime 聊天室,以接收各种通知。
以往用户若是想接收到 AWS 服务相关的通知,经常会使用 Amazon SNS 服务寄送通知到 Email 信箱或是手机简讯,虽然方便,却难免会与其他信件混杂,造成日后搜寻及管理上的不方便;又或是用户可以利用 CloudWatch Log Group 来存放不同资源运作的运作日志,以人工方式查验状态。
现在运用 Chatbot,不仅可以接收通知、随时查询帐户内资源的状态,也可以直接在 Slack 频道或 Amazon Chime 聊天室中下指令,触发 Lambda 或发起 AWS Support Cases,以对突发状况采取应变措施。
此外,使用 AWS Chatbot不需收费,用户只需要针对 Chatbot 所触发的服务收费,例如:Amazon SNS、Amazon Lambda 等等。
正式推出 Amazon Keyspaces
Amazon Keyspaces 先前的正式名称为 Amazon Managed Apache Cassandra Service(MCS),一款于 2019 年 12 月推出的全托管的 Apache Cassandra 兼容数据库服务。
使用 Keyspaces,用户可以将自身现有的 Cassandra Query Language (CQL) 搬迁至 AWS,同时不再需要管理底层 Server 或是担心软件版本的问题,且只需要对使用的资源数量付费,便可享受 99.99% 可用性及无上限的 throughput 和 storage 空间。
使用例:使用 Keyspaces 保存数据;Lambda 执行应用程序的逻辑;APIGateway 作为触发的 Endpoints。
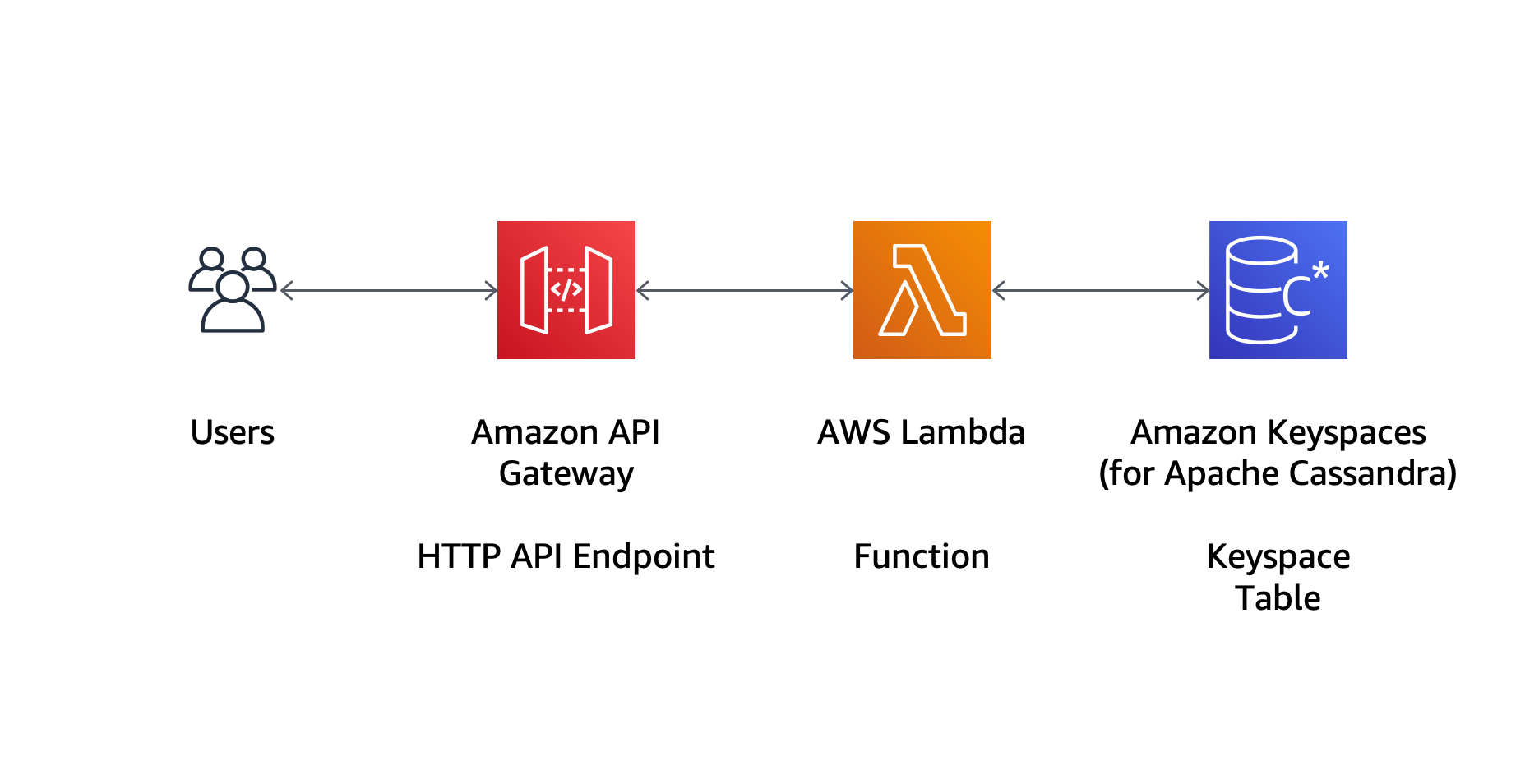
情境参考 AWS Blog: New – Amazon Keyspaces (for Apache Cassandra) is Now Generally Available
原先用户只能使用 Console 创建 Keyspaces,现在也可以利用 CloudFormation 部署。在此案例中,用户期望将书本的相关信息放置在 Keyspaces 之中。首先,用户须先创建一个 Keyspace 作为 database,再创建用于存储数据的 Table。接着,每当有 request 触发添加数据或是查询资料,会由 Lambda 确认是否具有访问的权限,如果通过认证,便会将数据放入 Keyspaces Table。
架构配置完成后,我们利用 curl 或 Postman 工具来触发 API Gateway,分别创建数据并查询目前 Table 里的状态。
- 创建数据:
## request
$ curl -i -d '{ "isbn": "978-0201896831", "title": "The Art of Computer Programming, Vol. 1: Fundamental Algorithms (3rd Edition)", "author": "Donald E. Knuth", "pages": 672, "year_of_publication": 1997 }' -H "Content-Type: application/json" -X POST https://a1b2c3d4e5.execute-api.eu-west-1.amazonaws.com/books
## response
HTTP/1.1 201 Created
{ "isbn": "978-0201896831", "title": "The Art of Computer Programming, Vol. 1: Fundamental Algorithms (3rd Edition)", "author": "Donald E. Knuth", "pages": 672, "year_of_publication": 1997 }
- 查询数据:
## request
$ curl -i https://a1b2c3d4e5-api.eu-west-1.amazonaws.com/books
## response
HTTP/1.1 200 OK
[ { "isbn": "978-0201896831", "title": "The Art of Computer Programming, Vol. 1: Fundamental Algorithms (3rd Edition)", "author": "Donald E. Knuth", "pages": 672, "year_of_publication": 1997 } ]
- 也可以针对
Key来搜索:isbn为 partition key
## request
$ curl -i https://a1b2c3d4e5.execute-api.eu-west-1.amazonaws.com/books/978-0201896831
## response
HTTP/1.1 200 OK
{ "isbn": "978-0201896831", "title": "The Art of Computer Programming, Vol. 1: Fundamental Algorithms (3rd Edition)", "author": "Donald E. Knuth", "pages": 672, "year_of_publication": 1997 }
## 若数据不存在,则会得到以下 response
HTTP/1.1 404 Not Found
{"message": "not found"}
参考来源至:Amazon Keyspaces (for Apache Cassandra) is now generally available
二、其他服务更新
Amazon EKS managed node groups 现在支持私有的网络环境
以往用户在建立 EKS node group 时,不论 node 是在 private 或 public subnets,都会覆盖 subnet 的 auto-assign IP 设置,自动配置一个 public IP。但按照 subnet 的设定,如果是在 private subnet 中的资源,是不需要 public IP 来与 VPC 以外的 endpoints 沟通,而是通过 NAT Gateway / NAT Instance 转指出去 VPC。因此用户经常在创立 EKS node group 时,无端消耗 VPC 内的 publicIP 数量。
此次更新之后,创立 node instance 时,会遵照 subnet 的 auto-assign IP 设定,在 private subnet 里的 node instance,就不会配置 public IP。不过此项更新只会影响往后新创立的 node group。
用户可利用以下命令检查 subnet 的 auto-assign IP 设置:
$ aws ec2 describe-subnets --filters "Name=vpc-id,Values=vpc-0a78a1eac2c6f1c97" | grep 'MapPublicIpOnLaunch\|SubnetId\|VpcId\|State'
参考来源至:Upcoming Changes to IP Assignment for EKS Managed Node Groups
IAM Access Analyzer 现在可以分析通过 S3 Access Points 访问的 Bucket
为了帮助用户更准确知道 S3 Bucket 可以被谁访问,IAM Access Analyzer 现在除了能分析 Bucket Policies 和 Access Control Lists,也能分析 S3 Access Point Policies,用户可以随时利用 IAM Access Analyzer 快速检查每个 Bucket 的权限,也能实时修改,遵循最小权限的最佳实践。
以下图为例:可以从 Console 中看到这个 Bucket 是受哪种 Policy 控制权限,可以做什么事情。

参考来源至:Discover, review, and remediate unintended access to S3 buckets shared through S3 Access Points
Amazon Redshift 现在支持针对 Redshift Spectrum 及 Concurrency Scaling 功能设置使用上限
在 Amazon Redshift 的收费方式中,用户需付费的项目有 node instance 使用数量与时间、Redshift Spectrum、Concurrency Scaling、备份资料的储存费,以及传输数据的传输费。
Redshift Spectrum 及 Concurrency Scaling 是两个经常使用的功能。当用户将原始数据放置在 S3 中,可以使用 Redshift Spectrum 有效率地查询其中的文件并抓取结构化与半结构化的资料,并针对查询的数据量大小进行收费;而使用 Concurrency Scaling 能够加速 Cluster 查询的速度,如果 Cluster 现有的容量不足以支持读取的速度,Redshift 将会自动扩展容量。由此可知,使用这两个功能需花费不少的成本。
此次更新后,用户可为每个 Cluster 设置 Redshift Spectrum 及 Concurrency Scaling 每日 / 每周 / 每月的使用上限,帮助用户控制 Redshift 的使用成本。当使用量接近于上限值,用户也可以设定需采取的动作,例如:触发 CloudWatch Alarm 并寄送 SNS 通知至管理者的 email 信箱,最后强制 Cluster 无法再继续使用该功能。
参考来源至:Announcing cost controls for Amazon Redshift Spectrum and Concurrency Scaling
AWS Storage Gateway 功能优化
当你需要把地端的数据存储在 AWS 上,可以通过 Storage Gateway 连接地端设备及云端,快速安全地将数据传上云端,不管是档案、磁带或是磁盘存储皆有支持。
Tape Gateway 支持自动添加虚拟磁带
用户创建好 Tape Gateway 后,还需要创建 virtual tapes 作为 on-premise 应用程序备份的地点。用户可先预估备份档案需要多少的容量,并分配不同容量给每个 virtual tapes 以满足容量的需求,但不必担心闲置空间的费用,使用多少的空间再付多少费用即可。
然而,随着备份数据的数量增加,最终可能超过当初创立 virtual tapes 的总容量,此时用户便需要手动创建额外的 virtual tapes,再挂载到备份用的应用程序之中。上述的手动过程,也容易因储存容量不足而造成备份中断,需等待新的 virtual tapes 挂载完成,才能重新执行。
此次更新后,当容量不足时,Tape Gateway 可自动新增足以满足需求的 virtual tapes,不需要再手动操作或是撰写脚本执行创建的动作,甚至新增完成后,也会直接挂载至应用程序中,让管理备份更加轻松。
參考來源至:AWS Storage Gateway automates creating new virtual tapes on Tape Gateway
Tape Gateway 支持更加快速的读取速度
除了上述的更新之外,Tape Gateway 也支持比过去快 2 倍的读取及写入速度,使存储的效率更佳。on-premise 应用程式最高写入速度可达 5.2 Gbps(读取速度最高则可达 8.2 Gbps,取决于地端与 AWS 之间的频宽速度。
参考来源至:AWS Storage Gateway increases Tape Gateway write and read performance by 2x
AWS Config 添加两种合规性模板
用户可以通过启用 AWS Config 合规性模板,直接对资源控制做侦测及修复,一旦不合规的事情发生,除了实时发现,也能快速地修复,此次更新后,新增了 2 个模板:
- AWS Control Tower 检测护栏合规性模板
- CIS 合规性模板
AWS Glue 支持流数据 ETL
以前要做串流资料的 ETL 时,只能通过手动建置才能处理,此次更新后,可以将 Amazon Kinesis Data Streams 或 Apache Kafka 等串流资料,执行 ETL 作业,可将结果连续存到 Amazon S3 数据湖、JDBC 数据存储中,用户可以利用这个功能来处理点击数据、IoT 串流数据和 log。
假设今天想要对存放在 Kinesis 里的流数据进行 ETL,首先你需要从 AWS Glue Console 中建立 ‘Data Store’,选择你的数据源、URL 及流媒体的数据的名称:

再来就是定义你的数据架构为何:
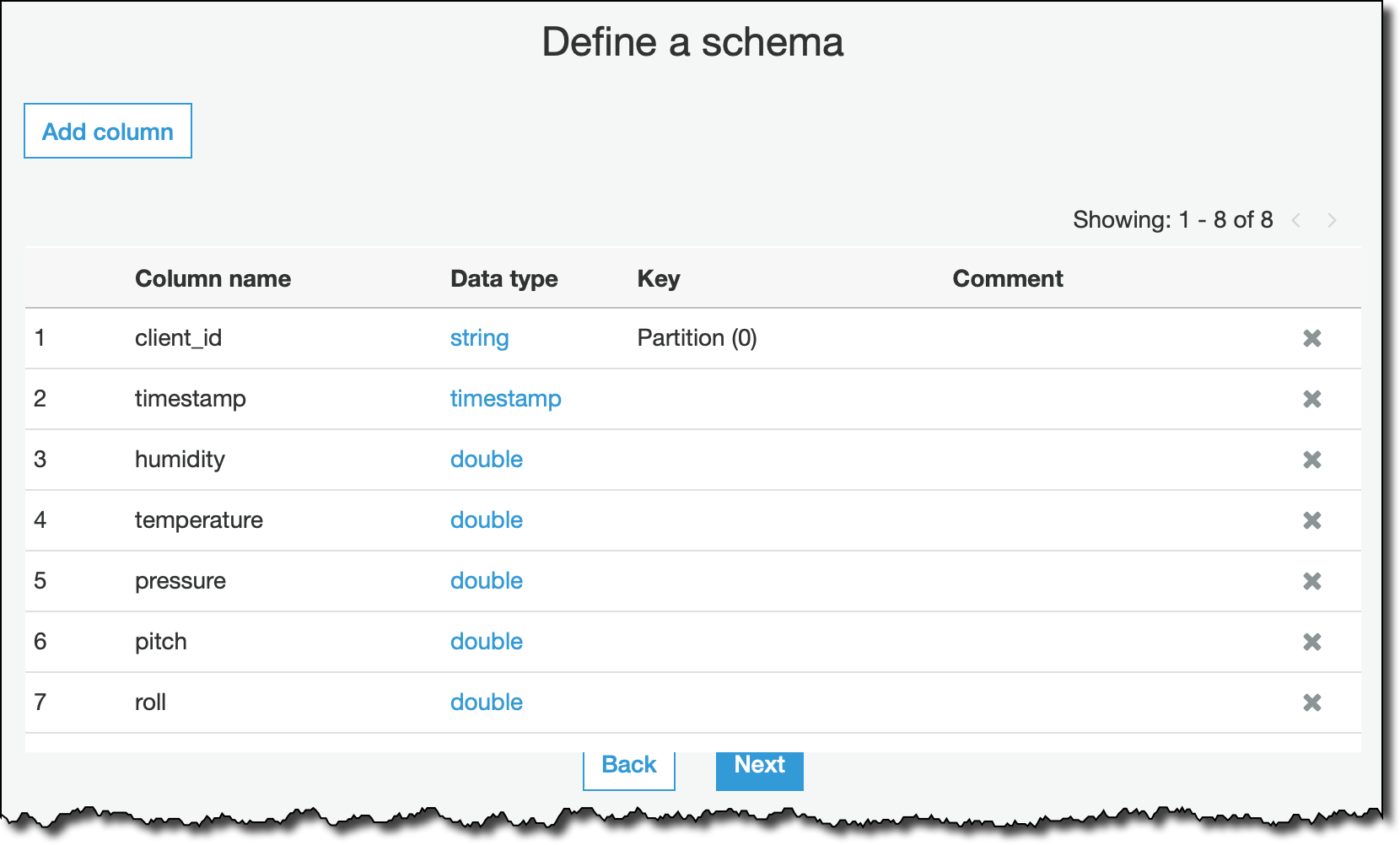
Data Store 完成之后,我们要开始创建 Glue Job 执行 ETL,输入名称、给它这个 Job 所需要的 Role:
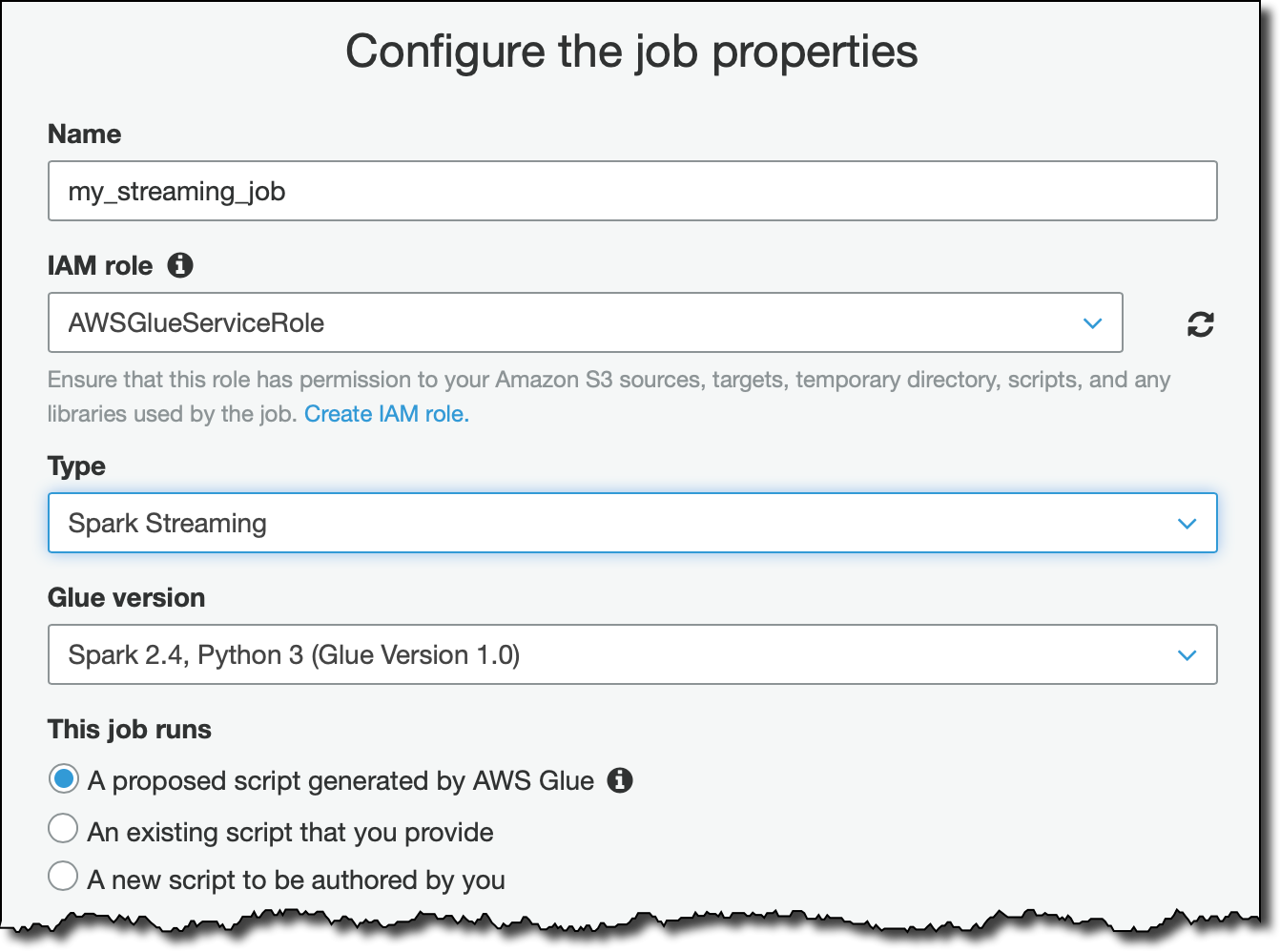
再选择我们刚刚建立好的 Data Store 为 Data Source,设置执行 ETL 后的资料要存放在哪里,及执行 ETL 的细节,这样就完成串流资料 ETL 处理。
参考来源至:AWS Glue now supports serverless streaming ETL 图片来源至:New – Serverless Streaming ETL with AWS Glue
Amazon Kinesis Data Firehose 现在支持 Amazon Elasticsearch 在 VPC 里的 domain
原先当用户设置将 Kinesis Data Firehose 的 Destination 设为 Amazon Elasticsearch 时,并不支持在 VPC 里的 domain。因此用户必须将 Amazon Elasticsearch domain 放在 Public 的环境之中,透过 access policy 管理存取 Elasticsearch 的权限,可限定特定 IP 地址的请求才可对 Elasticsearch 采取任何动作。但仍存在安全疑虑,因为直接接触 Internet,较容易受到网络攻击。
此次更新后,Kinesis Data Firehose 支持 Amazon Elasticsearch 在 VPC 里的 domain。用户可通过 VPC 内的网络设置,让 Elasticsearch 多一层防护,例如:将 Elasticsearch domain 放在 private subnet 中、运用 NACL 及 Security Group 作为防火墙…等等不同的方式以防止他人轻易地窃取资料,提升安全性。
Tag:Amazon AppFlow, Amazon CloudWatch Synthetics, Amazon EKS, Amazon EKS managed node groups, Amazon Elasticsearch, Amazon Keyspaces, Amazon Kinesis Data Firehose, Amazon Redshift, AWS, AWS Chatbot, AWS Config, AWS Glue, AWS Storage Gateway, AZ, Bucket, Canaries, Concurrency Scaling, domain, edge locations, ETL, Europe, GA, IAM Access Analyzer, Milan, Private network, Redshift Spectrum, S3 Access Points, SaaS, Slack, VPC
You may also like

【焦點新聞|Microsoft Build 2022】

【焦點新聞】0428-0511 AWS 服務更新
