

【每周快报】1121-1127 AWS 服务更新
一、服务的新功能
Amazon CloudWatch 新增功能
Amazon CloudWatch 是一个监控 AWS 资源状况的服务,可让用户或维运人员了解目前此服务的运作状况。
Amazon CloudWatch Synthetics(预览阶段)
此次更新后,用户可以使用此功能来监控应用程序端点,CloudWatch Synthetics 会监控用户的 REST API,URL 或网站内容,用户可以自定义脚本来检查网络钓鱼、代码注入或跨站点脚本等未经授权的更改,并在应用程序端点运行不正常时提醒用户。
我们甚至可以对这些测试进行定义,例如检查可用性、延迟、无效链接、页面加载错误等流程在应用程序当中。

用户可以使用模板或是自定义脚本来测试应用程序。
并在此输入应用程序端点。
并定义测试排程。
并会看到自动测试时自己应用程序的截图和 log 纪录。
参考资源至:Introducing Amazon CloudWatch Synthetics – Now in Preview
Amazon CloudWatch Contributor Insights(预览阶段)
此功能可以会以时间序列分析数据,以预测对系统影响的可能性,当用户设定完成后,Contributor Insights 会持续运行,无须后续的人为设置。此功能针对 CloudWatch 设置规则(Rule)。
正式推出 Amazon CloudWatch ServiceLens
Amazon CloudWatch ServiceLens 可让用户在单一位置可视化和分析应用程序的健康状况、效能和可用性。CloudWatch ServiceLens 会将 CloudWatch 指针和日志以及来自 AWS X-Ray 的追踪结合在一起,以完整检视应用程序及其相依性,帮助快速找出效能瓶颈、隔离应用程序问题的根本原因,以及判断受影响的用户。
使用情境:同时在两个主要领域获得应用程序的可见性
- 基础设施监控可使用指针和日志来了解支持应用程序的资源,而交易监控则使用追踪来了解资源之间的相依性。CloudWatch ServiceLens 提供的 Service Map 可视化用户所有资源的上下文链接,以及直觉式接口,更深入了解相关的监控数据。
AWS IoT Core 新功能
以下功能皆于 Beta 测试中,仅于 US-EAST-1 区域中可使用(功能可能也会有些许变动)。
IoT 安全信道(Beta)
IoT Secure Tunneling 让客户可以使用 TLS 1.2 加密 443 port 上设置安全隧道,然后使用本地代理在隧道中移动命令和数据。 主要有三大功能:
-
API
- 可以打开(OpenTunnel),关闭(CloseTunnel),列出(ListTunnels)和描述(DescribeTunnels)安全隧道。
-
Local Proxy(本地代理)
- 已注册 IoT 的设备,客户端透过 Access Token 透过 MQTT 与设备沟通,该设备在每个设备上启动本地代理以启动与隧道服务的连接。
-
Tunneling Service(信道服务)



设定完成后就会拿到该信道的 Access Token。
IoT 自定义域名(Beta)
IoT Custom Domains for Configurable Endpoints 让用户可以自定义 IoT Core endpoint 名称,并且拥有自己的 DNS CNAME 与凭证。
IoT 可配置的端点(Beta)
IoT Configurable Endpoints 可以创建多个终端节点,以将设备连接到 AWS IoT,还可以使用域配置来配置某些详细信息(例如域名)。主要可以使用域配置来简化诸如以下的任务:
-
将设备迁移到 AWS IoT
-
通过为不同的设备类型维护单独的域名配置来分类管理不同的设备群
-
在将应用程序基础设施迁移到 AWS IoT 时保持品牌识别度(例如:域名)
IoT 舰队模式(Beta)
IoT Fleet Provisioning 能让用户将大量 IoT 设备舰队一次注册到 AWS IoT Core 上,而不需要花时间一个一个配置。
IoT 与 AVS 整合(Beta)
Alexa Voice Service (AVS) Integration 提供新的内建 MQTT Topic,以便 IoT Core 上的硬件能够和已注册 AVS 的硬件沟通。

AWS Config 新功能
AWS Config 是可让用户评量、稽核和评估 AWS 资源组态的服务。Config 持续不断地监控和记录用户的 AWS 资源组态,并可依据所需的组态自动评估记录的组态。
介紹 AWS Config 合规性套件(Conformance Packs)
AWS Config 宣布推出合规性套件。合規性套件可协助用户使用通用架构和封装模型,大规模管理 AWS 资源的组态合规性,从政策定义到稽核和汇总报告。 合规性套件已与 AWS Organizations 整合。此整合可让用户封装 AWS Config 规则和补救动作的集合,将整个组织中当成单一实体部署,而可扩充且有效率的方式,建立组织中多个账号的资源组态原则和最佳作法的通用基准。
用戶也可编写 YAML template 来建立符合性套件,其中包含 AWS Config 规则 (受管理或自定义) 和补救动作列表。
AWS Config 启用对第三方资源的支持
AWS Config 宣布推出新功能,让用户可对第三方资源执行组态稽核和合规验证。现在可使用 AWs 新的 API,将第三方资源的组态 (例如 GitHub 存放库、Microsoft Active Directory 资源或任何现场部署服务器) 发布到 AWS Config 中。
AWS Glue 新增支持自己的 JDBC driver 引入 ETL 作业
AWS Glue 是一个全托管的 ETL 服务,客户可以准备数据,并加载分析。
此次更新后,客户可以将自己的 JDBC 驱动程序引入 Glue Spark ETL 作业。AWS Glue 具备本机连接器,可使用 JDBC 驱动程序连接到 AWS。
参考资源至:AWS Glue now enables you to bring your own JDBC drivers to your Glue Spark ETL jobs
Amazon RDS 适用于 Oracle 现在支持允许 ALLOWED_LOGON_VERSION_SERVER 和 ALLOWED_LOGON_VERSION_CLIEN 的 sqlnet.ora 参数
Amazon Relational Database Service(Amazon RDS)让用户能够在云端中轻松设定、操作和扩展关系数据库。
用戶可使用 SQLNET.ALLOWED_LOGON_VERSION_SERVER 参数来设定联机到 Amazon RDS for Oracle 数据库实例,允许的最小身份验证协议.或可设定 SQLNET.ALLOWED_LOGON_VERSION_CLIENT 参数,当服务器作为客户端与连接到 Amazon RDS for Oracle DB 实例时,允许的最小身份验证协议。
AWS Storage Gateway 在 VMware 上新增 HA 和新的效能监控指针
AWS Storage Gateway 是一种混合云端储存服务,可让内部部署存取近乎无限的云端储存空间。客户可以利用 Storage Gateway 简化储存管理并降低关键混合云端储存使用案例的成本。其中包括将磁带备份移至云端、利用云端支持的档案共享减少内部部署的储存、为内部部署应用程序提供低延迟的 AWS 数据存取,以及各种移转、存盘、处理和灾难复原使用案例。
储存网关现在透过与 VMware vSphere 高可用性 (VMware HA) 整合的一组健全状况检查,在 VMware 上提供高可用性。透过此增强功能,部署在 VMware 环境或 AWS 上的 VMware 云端部署的 Storage Gateway 将在 60 秒内从大部分的服务中断中断中复原。此更新可保护储存工作负载免于硬件、Hypervisor 或网络故障,或软件错误,例如联机逾时和档案共享或磁盘区无法使用。
此外,透过 Amazon CloudWatch 报表内嵌至 AWS Storage Gateway 主控台上,客户可持续掌握快取使用率、网关存取模式、吞吐量和 I/O 指针,能够更轻松地将分配的储存、运算和网络资源优化随着工作负载的演变而扩展到其网关。
参考资源至:AWS Storage Gateway adds HA on VMware and new performance monitoring metrics
Amazon EBS 快速快照还原(FSR)不需要将数据预先加热(pre-warming)到从快照建立的磁盘区
Amazon Elastic Block Store (EBS) 是易于使用的高效能区块储存服务,专为与 Amazon Elastic Compute Cloud (EC2) 搭配使用而设计,能以任何规模同时用于吞吐量和交易密集型工作负载。
用户现在可在Amazon EBS 快照上启用快速快照还原(Fast Snapshot Restore)。此新功能可让用户从快照还原多个磁盘区,而无需自行初始化磁盘区。以往,EBS 快照的数据延迟加载 EBS 磁盘区如果存取未加载数据的磁盘区,存取磁盘区的应用程序会在加载数据时遇到比正常更高的延迟。为了避免这种影响延迟敏感应用程序,客户将数据从快照预热到 EBS 磁盘区。 现在,从启用 FSR-的快照建立的磁盘区会在建立时完全初始化,并立即提供所有布建的效能。
Amazon Transcribe 现在支持替代转录(Alternative Transcriptions)
Amazon Transcribe 使用进阶机器学习技术以辨识音频档案中的语音,然后转录为文字。用户可以使用 Amazon Transcribe 将音频转换为文字,并建立并入音频档案内容的应用程序。
从今天开始,用户可指定 Amazon Transcribe 返回额外的转录为好。用户可使用这些替代转录来查看转录音频的不同诠释,让用户增加选用性和弹性,以便为用户的应用选择最合适的文字结果。 例如,在可让用户检阅和拼接在一起字幕的媒体资产管理 (MAM) 应用程序中,用户现在可以从最多十个替代转译中选择。Amazon 转译器支持的所有语言均提供替代成绩单。
参考资源至:Amazon Transcribe now Supports Alternative Transcriptions
Amazon S3 复写时间控制(Replication Time Control),提供可预测的复写时间,由 SLA 支持
Amazon Simple Storage Service (Amazon S3) 对象储存服务提供领先业界的可扩展性、数据可用性、安全性及效能。 这表示所有规模和产业的客户在种使用案例中,都可利用此服务来存放和保护任意数量的数据,例如网站、行动应用程序、备份和还原、存盘、企业应用程序、IoT 装置及大数据分析。
Amazon S3 复制时间控制(S3 RTC) 是 S3 复制的一项新功能,可提供由服务等级协议 (SLA) 支持的可预测复制时间。 S3 RTC 可协助客户符合数据复制的合规性或业务需求,并使用新的 Amazon CloudWatch 指针提供复制程序的可见性。
客户使用 S3 复写将数十亿个储存贮体中的对象复写到相同或不同的区域。S3 复制时间控制的设计是在上传后 15 分钟内复制 99.99% 的对象,大部分的新对象都在几秒钟内复制。S3 RTC 由 SLA 提供支持,承诺在任何计费月份内在 15 分钟内复制 99.9% 的对象。 S3 RTC 也提供 S3 复写指针,让客户监控完成复写所需的时间,以及搁置复写的对象总数和大小。
参考资源至:Amazon S3 Replication Time Control for predictable replication time, backed by an SLA
AWS CloudTrail 推出 CloudTrail Insights
AWS CloudTrail 是可启用 AWS 帐户管控、合规、操作稽核和风险稽核的服务。
CloudTrail Insights 可协助用户识别 AWS 帐户中不寻常的操作活动,例如:资源布建尖峰、AWS 身分识别和存取管理 (IAM) 动作,或定期维护活动的差距。

- CloudTrail Insights 旨在自动分析 CloudTrail 追踪中的管理事件,以建立正常行为的基准,并在侦测到不寻常的模式时产生深入解析事件以引发问题。
-
当 CloudTrail Insights 侦测到异常活动时,它会透过 CloudTrail 控制台中的仪表板检视引发事件、将事件传送到您的 Amazon S3 储存贮体,并将事件传送到 Amazon CloudWatch 事件,用户也可以选择将事件传送到 Amazon CloudWatch Logs,以建立警示。
-
使用情境:监测
RunInstances事件,可在图表中看到超出平均值的时间点及使用资源的数值

若想知道高峰值的详细说明,可点选高峰值,得到更多信息。

参考来源至:AWS CloudTrail announces CloudTrail Insights 图片来源至:Announcing CloudTrail Insights: Identify and Respond to Unusual API Activity
Amazon EC2 Auto Scaling 新增功能
AWS Auto Scaling 可监控应用程序并自动调整容量,尽可能以最低成本维持稳定、可预测的效能。使用 AWS Auto Scaling,几分钟内即可为多项服务的多种资源轻松设定应用程序扩展功能。
Amazon EC2 Auto Scaling 现在支持最长实例寿命
Amazon EC2 Auto Scaling 现在可让用户以定期节奏安全且安全的方式回收 Auto Scaling Group (ASG) 中的实例。 Maximum Instance Lifetime 参数可协助用户确保实例在达到指定的生命周期之前回收,让用户以自动方式遵守安全性、合规性和效能需求。其最大实例生存时间值 : 7 到 365 天之间。
参考资源至 : Amazon EC2 Auto Scaling Now Supports Maximum Instance Lifetime
Amazon EC2 Auto Scaling 现在支持实例权重
Amazon EC2 Auto Scaling 现在可让用户在 Auto Scaling groups (ASG) 中包含实例权重,这些权重配置为跨多个实例类型布建和扩展。实例权重定义每个实例类型将有助于应用程序效能的容量单位,为可包含在 ASG 中的实例类型选取提供更大的弹性。当使用实例加权时,可选择的单位来设定 ASG 所需的容量,例如实例类型的虚拟 CPU、内存、存储器、吞吐量或相对效能。
参考资源至:Amazon EC2 Auto Scaling Now Supports Instance Weighting
AWS AppSync 为图形 API 新增服务器端快取(built-in server-side caching)和 DynamoDB 交易支持
AWS AppSync 是一种受管 GraphQL 服务,可让用户建立弹性的 API,以安全地存取、操作和合并来自一或多个数据源的数据。
此次更新之后,AppSync 现在为任何支持的数据源提供内建的服务器端快取功能,改善延迟性和高吞吐量应用程序的效能,开发人员能够从高速缓存内的撷取数据,加快传递数据的速度。同时,AWS AppSync 支持快取从一或多个数据源撷取的整个 API 数据集,并提供选择性快取变更频率较低的特定数据字段。
- 使用新的缓存功能,您可以为您的GraphQL API 定义不同的缓存行为:
- 无(None):没有服务器端快取,而这是的默认值。
- 完整请求缓存(Full request caching):如果数据不在缓存中,它将从数据库中搜寻并填入缓存,直到 TTL 到期。 之后,对 API 的所有请求将从缓存返回,这意味着数据源不会被直接联系。
- 每解析器缓存(Per-resolver caching):只有 API 调用从解析器中定义的特定操作或字段请求数据将从缓存响应。
可选择符合需要的 caching 方式,并指定需要的 instance type 以符合效能及内存的需求

此外,AppSync 现在也支持 Amazon DynamoDB 数据源和解析程序的 TransactGetItems 及 TransactWriteItems 作业。
参考来源至:AWS AppSync adds server-side Caching and DynamoDB transactions support for GraphQL APIs 图片来源至:Improving GraphQL API performance and consistency with AWS AppSync Caching and DynamoDB Transactions support
Amazon FSx for Windows File Server 新增功能
Amazon FSx for Windows File Server 提供完全受管的 Windows 文件服务器,由完全原生的 Windows 文件系统支持,具有功能、效能和兼容性,可轻松将企业应用程序随即转移到 AWS。
Amazon FSx for Windows File Server 现在支持跨越多个可用区域的文件系统
现在用户可跨 AWS 可用区域 (AZ) 建立适用于 Windows File Server 的 Amazon FSx,以便在多个 AZs 之间部署 Windows 档案储存,并具有高可用性和冗余功能。异地同步备份文件系统旨在为数据提供持续可用性,即使在无法使用的情况下,支持业务关键工作负载,例如商务应用程序、网站服务环境和 Microsoft SQL Server。
参考资源至:Amazon FSx for Windows File Server now supports file systems that span multiple Availability Zones
Amazon FSx for Windows File Server 将文件系统的最小大小从 300 GB 降低至 32 GB
现在用户可在 Amazon FSx for Windows File Server 建立最小 32 GB 的文件系统。对小型文件系统的新支持可让用户以符合成本效益的方式使用 Amazon FSx,例如 Web 服务、SQL Server 见证和共享应用程序组态等少量数据的使用案例。
参考资源至:Amazon FSx for Windows File Server reduces the minimum size for file systems from 300 GBs to 32 GBs
Amazon FSx for Windows File Server 新增对高可用性 Microsoft SQL Server 部署的支持
Amazon FSx 宣布两项新功能,让用户更容易部署高可用性 (HA) Microsoft SQL Server 部署的共享 Windows 存储器:
-
支持持续可用 (CA) 档案共享:让档案储存空间以优化为 Microsoft SQL Server 的方式提供,用户能够将微软 SQL Server 数据储存在 AWS 的全受管 Windows 文件系统上。
-
支持较小型文件系统:见证档案 (Witness file 维护丛集资源)的仲裁共享只需要少量的储存空间以供仲裁信息使用,让使用 FSx 作为档案共享见证的完全受管文件系统更具成本效益。
Amazon FSx for Windows File Server 现在支持通过 PowerShell 管理文件共享
现在支持透过 PowerShell 管理档案共享,储存管理员能够自动化 Amazon FSx 文件系统上档案共享的迁移、同步和持续管理。 这种建立共享方式在建立大量共享的情况下非常有用,例如建立大量共享的移转和同步处理,以及用户经常建立共享的进行中管理工作流程等案例。
参考资源至:Amazon FSx for Windows File Server now supports managing file shares via PowerShell
Amazon FSx for Windows File Server现在可强制执行传输中加密
现今,Amazon FSx 支持使用 SMB 3 加密对传输中的数据进行加密,并允许来自不支持 SMB 3 的运算实例的未加密联机。用户现在可以选择强制执行只允许透过加密联机存取,以符合用户的规范需求。
参考资源至:Amazon FSx for Windows File Server now enables enforcement of in-transit encryption
Amazon FSx for Windows File Server 现在支持用户储存配额,可监控和控制用户层级的储存使用量
现在 Amazon FSx for Windows File Server 支持用户储存配额,让储存管理员能够监控和控制文件系统上的用户层级储存使用量。当同时有多个用户使用档案储存时,例如主目录和用户共享,储存管理员通常需要将储存成本分配给个别团队,并在用户层级上施加限制,以防止任何一位用户储存大量数据。透过新的 Windows 用户储存配额支持,可设定储存使用量的个别用户层级配额,并透过拒绝给超出配额的用户进一步储存空间来监控使用量、追踪违规和强制执行配额。
Amazon FSx for Windows File Server 现在支持数据删除,在一般档案共享的储存成本可降低 50-60%
现在 Amazon FSx for Windows File Server 支持数据删除,一般档案共享的储存成本降低 50-60%。大型数据集通常会有冗余的数据。如:对于用户档案共享,多个用户通常会有类似或相同的档案。Amazon FSx for Windows File Server 的一项功能,可藉由储存盘案的重复部分,降低与冗余数据相关联的成本,并节省 Amazon FSx 文件系统的储存成本。在一般用途档案共享的典型节省 50-60%,用户文件节省 30-50%,软件开发数据集则为 70-80%。
AWS System Manager 新增 AppConfig 功能
AWS System Manager 是一个能让用户查看及控制 AWS 的基础设施的服务,提供统一的用户界面,方便查看多项 AWS 服务的运作数据,并允许将各种 AWS 资源上的操作任务设为自动化执行。
此次更新后,用户可以使用此功能在 EC2、Lambda、Container、IoT 设备、行动应用程序、本地服务器上迅速新增与修改应用程序设定,就如同开发者部署程序代码一般。
用户可以使用 Lambda 来验证应用程序的设定是否有误,有助于确保配置数据在语法和语义上正确无误,然后再将其提供给应用程序,当验证成功时,部署才会继续。
AWS Toolkit for Visual Studio Code 新增 CDK Explorer 功能预览
CDK Explorer 的新预览功能,可让开发人员可视化 CDK 应用程序。AWS CDK 于今年 7 月推出 GA,是一个开放原始码软件开发架构,可使用熟悉的程序设计语言建模和布建云端应用程序资源。CDK 应用程序是由称为建构的建置区块所组成,其中包括云端堆栈和内部资源的定义。
CDK Explorer 侧边栏与 Visual Studio 程序代码编辑器的接口无缝整合。您可以透过点击 Visual Studio 代码资源管理器找到 CDK Explorer。CDK 资源管理器列出所有 CDK 项目,并提供应用程序、基础架构堆栈、资源及其属性和政策的架构图。 当您执行 cdk synth 时,您可以重新整理 CDK Explorer 页面以更新显示树,并反映您在基础结构中所做的变更。

参考资源至:AWS Toolkit for Visual Studio Code Adds New CDK Explorer in Preview 图片来源至:Working with AWS CDK Applications
提升使用 AWS Managed Microsoft AD 时,AWS 应用程序与 Self-Managed Active Directory with Secure LDAP 之间的安全
AWS Directory Service for Microsoft Active Directory(AWS Managed Microsoft AD),现在可以加密 AWS 应用程序之间的 Lightweight Directory Access Protocol (LDAP),例如 Amazon Workspaces和 Amazon Chime,以及您的自我管理 AD。这可让您透过启用 AWS Managed Microsoft AD 做为安全 LDAP (LDAPS) 客户端,更好地保护组织的身分数据并符合安全要求。
若要启用客户端 LDAPS,您只需将 certificate authority (CA) 凭证汇入 AWS Managed Microsoft AD,然后在目录上启用LDAPS 即可。启用后,AWS 应用程序和自我管理 AD 之间的所有 LDAP 流量都会以安全套接字层 (SSL) 信道加密流动。
Amazon DynamoDB 新增功能
Amazon DynamoDB 是一个完全受管的非关系数据库,可在任何规模提供可靠的效能。
现在用户可透过新增全局副本(global replicas)来增强现有 Amazon DynamoDB 表格的可用性
用户现在可将现有的单一区域表格,随时新增至全局表格复本,以获得 99.999% DynamoDB 的高可用性,可帮助进行灾难复原及支持延迟敏感的应用程序,而无需在桌面上停机。 此外,用户还可以从效率改善中受益,减少多达 50% 的复写写入。

- 当使用全局副本时,用户需选择复制的目的区域,例如:在日本、维吉尼雅、奥勒冈需要存取这张数据表,则选择这三个区域,DynamoDB 便会开始使用现有表格的快照来填入新复本。

- 当 DynamoDB 建置新复本时,用户仍可以继续写入原始区域,DynamoDB 会自动将内容更新到复本中,因此可以随时在现有的全局数据表中新增或删除复本。
参考来源至:You now can enhance availability of your existing Amazon DynamoDB tables by adding global replicas
图片来源至:New – Convert Your Single-Region Amazon DynamoDB Tables to Global Tables
使用用户自己的加密金要来加密 Amazon DynamoDB 的数据
DynamoDB 默认会使用 AWS 拥有的 customer master key(CMK)加密所有静态数据,除非您选择使用 AWS 受管 CMK。从今天开始,您也可以使用客户管理的 CMK,这表示您可以完全控制如何加密和管理 DynamoDB 数据安全性。
当您使用客户管理的 CMK 时,您可以将自己的加密密钥带到 DynamoDB,并在多个 AWS 服务中使用这些密钥。您现在可以建立、使用、轮替和销毁加密密钥,以协助保护敏感应用程序、遵守组织政策、符合合规和法规要求,以及在 AWS 之外维护额外的加密密钥复本。您也可以使用 AWS CloudTrail 来监控关于密钥建立、使用和删除的详细稽核信息。
DynamoDB 以透明方式处理数据的加密和解密,并继续提供与您预期相同的单数毫秒延迟。所有 DynamoDB 加密密钥选项都使用 256 位进阶加密标准 (AES-256),协助保护您的数据,避免未经授权存取基础储存装置。您不需要修改程序代码或应用程序,即可使用和更新加密密钥。
您可以使用客户管理的 CMK,在 AWS 管理控制台中单击或简单的 API 呼叫,或使用 AWS 命令行接口(CLI)来加密数据。使用 AWS 拥有的 CMK 对静态数据进行加密无需额外费用。AWS 密钥管理服务和 AWS CloudTrail 费用适用于使用客户受管的 CMK 和 AWS 受管的 CMK。

参考资源至:Encrypt your Amazon DynamoDB data by using your own encryption keys
Amazon Aurora MySQL 5.7 当前启动支持 Aurora Global Database
Amazon Aurora Global Database会在主要区域中复写写入,其延迟一般小于1 秒至次要区域,用于低延迟全局读取。在严重损坏修复的情况下,您可以升级次要区域,在一分钟内完整的读写责任。
Amazon Aurora Global Database 是跨越多个 AWS 区域的单一数据库,可实现低延迟全球读取和全区域中断的灾难复原。随着今天的推出,这项功能在 MySQL 5.7 兼容版本的 Aurora 上获得支持。您可以将区域新增至现有 MySQL 5.7 丛集,以建立新的全局数据库丛集。
参考资源至:Aurora Global Database is Now Supported on Amazon Aurora MySQL 5.7
宣布 Cloud Debugging (beta) 可以在各种 JetBrains IDE 除错云端运行的应用程序
适用于 IntelliJ、PyCharm、Rider和 WebStorm 的 AWS 工具包现在支持 Cloud Debugging (beta),可让您透过直接存取在云端执行的程序代码来侦错云端应用程序。 以前,当您想要在整合开发环境 (IDE) 中逐步执行侦错应用程序时,必须依赖诸如本机仿真等功能,这些功能会尝试在本机机器上复制复杂的云端架构。仿真环境无法一致地维持云端环境的真实度,导致在部署时发现更多错误和较长的开发周期。
云端除错目前支持使用 AWS Fargate 在 Amazon ECS 上执行的容器化应用程序除错。您可以查看日志,设置breakpoint,并将终端机放入正在运行的容器中。您可以在 JetBrains IDE 中开始使用 Cloud Debugging (beta),方法是下载并安装适用于 IntelliJ,PyCharm,Webstorm 或Rider 的 AWS 工具包。
Amazon Neptune 提供使用 Elasticsearch clusters进行全文搜索
Amazon Neptune是快速、可靠、全受管的图形数据库服务,可让您轻松建立与执行搭配高度联机数据集使用的应用程序。
Amazon Neptune现在支持使用 Elasticsearch clusters进行全文搜索。这允许客户在 Elasticsearch clusters 中使用搜寻索引功能(例如使用 Amazon Elasticsearch Service)并将其图形数据储存在 Amazon Neptune 中。
客户要求一种简单的方法来执行图形数据的全文搜寻。虽然图形查询语言支持基本文字搜寻,但客户现在可以从 Neptune 存取 Elasticsearch 的内建文字索引和查询功能。 客户可以使用现有的 Elasticsearch cluster,或建立新 cluster 以搭配全文搜索查询使用。海王星使用统一的 JSON 文档结构来存储 SPARQL 和 Gremlin 数据在Elasticsearch 之中。使用 Elasticsearch 客户可以使用 Gremlin 和 SPARQL 查询的扩充功能,执行全文搜索查询类型,例如比对查询、间隔查询和查询字符串。 Gremlin 用户可以使用 withSideEffect 步骤并传递 Elasticsearch 端点、搜寻模式和字段信息。 同样地,SPARQL 用户可以使用 SERVICE 关键词来查询 Elasticsearch。
参考资源至:Amazon Neptune offers full-text search integration with Elasticsearch clusters
Amazon Athena 新增功能
Amazon Athena 是交互式查询服务,可让您使用标准 SQL 轻松地在 Amazon Simple Storage Service (Amazon S3) 中直接分析数据。只要在 AWS 管理控制台执行几个动作,您就能将 Athena 指向您存放在 Amazon S3 的数据,并开始使用标准 SQL 来执行临机操作查询,在几秒钟内就能获得结果。
参考资源至:什么是 Amazon Athena?
Amazon Athena 增加了四个新的查询相关指针(metrics)
Amazon Athena 发布额外的查询指针以协助客户了解 Amazon Athena 效能。Athena发布与查询相关的指针至 Amazon CloudWatch。在此版本中,Athena 将发布四个额外的查询指针。它们是:
- 查询计划时间(Query Planning Time):计划查询所花费的时间。这包括从数据源撷取数据表分割区所花费的时间、
- 查询队列时间(Query Queuing Time):即查询在队列中等待资源的时间,
- 服务处理时间(Service Processing Time):查询引擎完成其执行之后写入结果所花的时间,
- 总运行时间(Total Execution Time):Athena 执行查询所花费的时间。
您可以在 CloudWatch 中建立自定义仪表板、在量度上设定警示和触发程序,或直接从 Athena 控制台使用预先填入的仪表板来取用这些新的查询量度。
Amazon Athena 增加了在SQL 查询中调用机器学习模型的支持
Amazon Athena 发布了一项新功能,可让用户直接从其 SQL 查询呼叫机器学习模型。在 SQL 查询中使用机器学习模型的能力,可让复杂的工作如异常侦测、客户群组分析和销售预测如同在 SQL 查询中呼叫函数一样简单。
客户可以使用 Amazon SageMaker 提供的十多种内建机器学习算法、训练自己的模型,或从 AWS 市场寻找和订阅模型套件,亦或是从部署在 Amazon SageMaker 主机服务上。 从这些资源取用服务室不需要额外的设定。用户可以从 Athena 控制台、Athena API 和 Athena 的预览 JDBC 驱动程序呼叫这些 ML 模型。
Amazon Athena 的 ML 功能目前在 us-east-1 (N. Virginia) 区域预览中提供。
参考资源至:Amazon Athena adds support for invoking machine learning models in SQL queries
使用 Apache Hive Metastore 作为 Amazon Athena 的metadata catalog (Preview)
Amazon Athena 现在允许您将Athena 连接到 Apache Hive Metastore。
客户使用 Hive Metastore 做为其巨量数据环境的通用 metadata catalog。这样的客户在 Amazon EC2 和Amazon EMR clusters 上运行 Apache Spark、Presto 和 Apache Hive 并自托管 Hive Metastore 作为一个通用目录。AWS 还提供 AWS Glue Data Catalog – 一个完全受管的目录和 Hive Metastore 的立即取代品。在目前的版本中,可以用 Athena 的Glue Data Catalog,连接多个 Hive Metastores。
此功能可在 US-East-1 (N. Virginia)区域预览中使用。
参考资源至:Use Apache Hive Metastore as a metadata catalog with Amazon Athena (Preview)
Amazon Athena 增加了对用户定义的函数(UDF)的支持
Amazon Athena 现在支持用户定义函数 (UDF),这项功能可让客户撰写自定义标量函数并在 SQL 查询中呼叫它们。虽然 Athena 提供 built-in functions,UDF 使客户能够执行自定义处理,如压缩和解压缩数据,压缩敏感数据,或应用自定义解密。
客户可以使用 Athena Query Federation SDK 在 Java 中编写他们的 UDF。在提交给 Athena 的 SQL 查询中使用 UDF 时,会在 AWS Lambda 上呼叫并执行该 UDF。 UDF 可以在 SQL 查询的 SELECT 和 FILTER 子句中使用。用户可以在同一个查询中呼叫多个 UDF。
此功能可在 US-East-1 (N. Virginia)区域预览中使用。
参考资源至:Amazon Athena Adds support for User Defined Functions (UDF)
Amazon Athena 增加了关系型、非关系型、对象和自定义数据源执行SQL 查询的支持
Amazon Athena 现在可让用户跨储存在关系型、非关系型、对象和自定义数据源中的数据执行 SQL 查询。客户现在可以透过提交单一 SQL 查询扫描来自执行内部部署或云端中装载的多个来源的数据。
针对跨应用程序分散的数据执行分析可能会很复杂且耗时。分析所需的数据通常分布在关系,键值,文档,内存中,搜索,图形,对象,时间序列和分类账数据存储。为了分析这些来源的数据,分析师建立复杂的管道来提取,转换和加载到数据仓库,以便数据可以被查询。从各种来源访问数据需要学习新的编程语言和数据访问结构。以 Athena 查询可让用户从任何位置就地查询数据,以消除此复杂性。分析师可以使用熟悉的 SQL 结构,跨多个数据源连接数据以便快速分析,并将结果存放在 Amazon S3 中以供后续使用。
Athena 使用在 AWS Lambda 上执行的 Athena Data Source Connectors 执行查询。AWS 为 Amazon DynamoDB、Apache HBase、Amazon Document DB、Amazon Redshift、AWS CloudWatch、AWS CloudWatch Metrics 和符合 JDBC 标准的关联式数据库提供了开放原始码的数据源连接器,以及 Apache 2.0 许可证下的 PostgreSQL。客户可以使用这些连接器,在 Athena 跨这些数据源执行同盟 SQL 查询。此外,使用 Athena Query Federation SDK,开发人员可以建置连接器到任何数据源,以让 Athena 对该数据源执行 SQL 查询。Athena Query Federation Connector 将查询的好处扩展到 AWS 提供的连接器之外。由于连接器在 AWS Lambda 上执行,因此客户不需要管理基础设施或规划扩展到尖峰需求。
此功能可在 US-East-1 (N. Virginia)区域预览中使用。
Amazon EMR 6.0(Beta 2)增加了 Hive 3 与 LLAP 支持,Scala 2.12 与 Spark 2.4.4
Amazon EMR 采用 Web 规模的 Amazon Elastic Compute Cloud (Amazon EC2) 和 Amazon Simple Storage Service (Amazon S3) 基础设施上执行的托管 Hadoop 架构,使用户能处理大量数据的 Web 服务
Amazon EMR 版本 6.0.0(Beta 2)现在可用于 Hive 3.1.2,Hadoop 3.2.1,Spark 2.4.4 和 Scala 2.12。在此版本中,默认会启用 Hive LAP,让您受益于改善的查询效能和新功能,例如具体化视观表和工作负载管理。此外,Scala 已经升级,允许您开始测试您的 Spark 应用程序与 Scala 2.12。
此 EMR 6.0.0 (Beta 2) 在 US East (N. Virginia)、US West (Oregon)、EU (Ireland) 和Asia Pacific (Seoul) 地区提供。为了获得 Hive LAP 的最佳体验,我们建议使用大于 2xlarge 的实例类型。
参考资源至:Amazon EMR 6.0 (Beta 2) adds Hive 3 with LLAP support, and Scala 2.12 with Spark 2.4.4
Amazon Kinesis Data Firehose 新增了客户提供的服务器端加密密钥的支持
Amazon Kinesis Data Firehose 可以撷取串流数据,并将数据转换和加载 Amazon S3、Amazon Redshift、Amazon Elasticsearch Service 及 Splunk,再使用现有的商业智能工具以及您目前正在使用的仪表板进行近乎实时的分析。它是一项全受管的服务,也是将串流数据加载数据存放区和分析工具最简单的方式。
Amazon Kinesis Data Firehose 现在透过客户提供的服务器端加密 (SSE) 交付串流的密钥,为敏感数据提供额外的保护。此功能与 AWS 密钥管理服务 (KMS) 整合,可让您集中管理保护 Kinesis Data Firehose 交付串流的密钥,以及保护其他 AWS 资源的密钥。
当您将记录摄入加密交付串流时,Amazon Kinesis Data Firehose 会立即对您的讯息进行加密。加密会使用 256 位 AES-GCM 算法和 AWS KMS 发行的客户主密钥 (CMK) 在服务器上进行。 Kinesis 数据 Firehose 现在可与客户提供的 CMK 和 AWS 提供的 CMK 搭配使用。这些记录以加密形式存储在多个可用区域 (AZ) 中,只有当它们交付到像 Amazon S3、Amazon Elasticsearch Service、Amazon Redshift 和 Splunk 等目的地时才进行解密。
参考资源至:Amazon Kinesis Data Firehose Adds Support For Customer-Provided Keys for Server-Side Encryption
Statistical Multiplexing (Statmux) 现在可透过AWS 元素媒体上使用
AWS ElenMediaLive 视讯处理现在可让您准备 multi-program transport streams (MPTS),以便透过卫星、有线或地面网络进行广播分发,支持 Statistical Multiplexing (Statmux) 输出。如此一来,便于使用、完全受管的云端服务进行广播分发,让您可以更灵活、更有效率地传递实时内容、降低基础架构和管理成本,以及透过内建可靠性散布高质量视讯。
MediaLive 专用 Statmux 提供了一种替代传统、基于硬件的方法来准备广播视讯以供传递。请造访此页面以进一步了解。
AWS 元素 MediaLive 是广播级的实时视讯处理服务。它可让您建立高质量的实时视讯串流,以传送至广播电视和连接因特网的多屏幕装置,例如连接的电视、平板计算机、智能型手机和机顶盒。
AWS Elpart MediaLive 独立运作或作为 AWS 元素媒体服务的一部分,这是一个组成云端工作流程基础的服务系列,并为您提供传输、建立、包装、营利和交付视讯所需的功能。
参考资源至:Statistical Multiplexing (Statmux) Now Available with AWS Elemental MediaLive
透过 AWS Single Sign-on,为 Azure AD 用户集中管理 AWS 的存取权
客户现在可以将 Azure Active Directory 联机到 AWS Single Sign-on (SSO) 一次、在 AWS SSO 中集中管理 AWS 的许可,以及让用户使用 Azure AD 登入以存取指派的 AWS 帐户和应用程序。如此一来,管理员可以更轻松地将存取权授与其现有用户和群组,并为用户提供从 Office 365 获得的登入体验,方便用户从指派的 AWS 帐户。
使用 AWS SSO,您可以建立与角色或项目一致的弹性许可,以便在所有 AWS 组织帐户中集中指派用户和群组存取权。AWS SSO 会自动集中设定和维护帐户中的所有权限,无需在个别帐户中进行额外的设定。在新版本中,您可以使用安全宣告标记语言 (SAML) 2.0 标准来连接 Azure AD、使用 AWS SSO 来集中管理 AWS 帐户的存取权,而且用户可以使用 Office 365 登入体验登入。 客户也可以使用标准的跨网域身分识别管理 (SCIM) 通讯协议系统,将 Azure AD 用户和群组自动布建至 AWS SSO。例如,如果您授与 Azure AD 群组管理 EC2 实例的权限,稍后将某人从群组中移除,则该人员会自动失去管理 EC2 实例的权限。我们正积极与 AWS 合作伙伴网络成员合作,包括 Okta、OneLogin 和 Ping 身分识别,为其身分提供者启用互操作性。
您可以轻松开始使用 AWS SSO。只要在 AWS SSO 管理控制台中按几下鼠标,就可以选择 AWS SSO、Active Directory 或外部身分识别提供者做为身分来源。然后,您可以集中管理用户对 AWS 组织帐户和数百个预先设定的云端应用程序 (例如 Salesforce、Box 和 Office 365) 的存取权。您的用户可以方便地登入他们熟悉的登入体验,并从 AWS SSO 用户入口网站单单击存取他们指派的所有帐户和应用程序。
参考资源至:Manage access to AWS centrally for Azure AD users with AWS Single Sign-on
Amazon QuickSight 新增功能
Amazon QuickSight 是一种快速、采用云端技术的商业情报服务,可让用户将见解提供给组织中的每个人。
Amazon QuickSight 推出主题、条件格式化等等
Amazon QuickSight 现在可让用户新增主题和自定义项目,以符合您的企业品牌或应用程序外观和风格。主题可让 QuickSight 仪表板的作者自定义偏好的背景、文字、数据和渐层色彩,以及视觉效果的间距和边框。
Amazon QuickSight 现在也支持表格、数据透视表和 KPI 图表中的条件格式化。用户可以使用纯色或渐层色,根据数据集中的域值自定义文字和背景色彩。用户也可以根据套用的条件,使用图标来显示数据值。
其他自定义项目包括同步组合图上的轴,以对齐线条和长条维度的缩放、新的色彩选择器以在仪表板中选取客户色彩、重新命名已发布的仪表板,以及自定义轴卷标、表格和 KPI 图表的字号。
可在左边字段选择主题
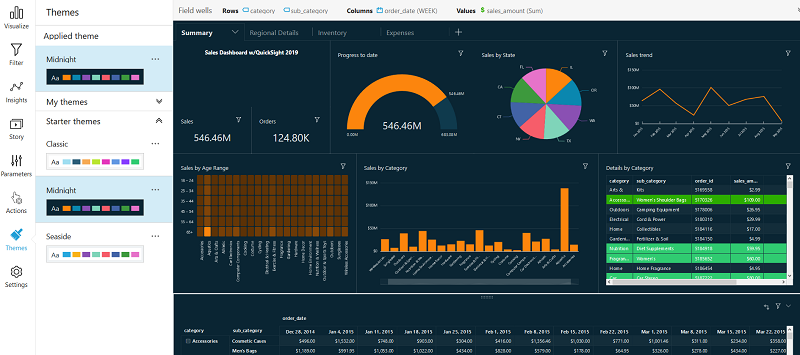
有以下的选项可以控制呈现的模样
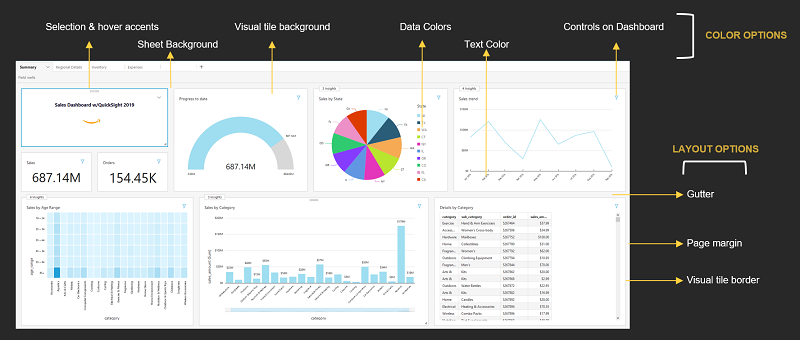
参考资源至:AWS Toolkit for Visual Studio Code Adds New CDK Explorer in Preview 图片来源至:Evolve your analytics with Amazon QuickSight’s new APIs and theming capabilities
Amazon QuickSight 新增对数据、仪表板、SPICE 和权限的 API 支持
此次更新之后,用户现在可以在 Amazon QuickSight 中以程序设计的方式建立、管理、部署和稽核资源。
- Dashboard API:可启用预先设定好的模板,并建立仪表板与现有的仪表板一同管理,例如:从这些模板来为用户或群组以程序设计的方式建立个人化的仪表板。
- Data API:提供与数据源和数据集有关的功能,例如:量身订做的筛选数据集。
用户可以将仪表板和数据集预先填入个别的作者帐户以更轻松快速上线,而不再需要将个别的登入数据分配至数据源,且可以轻松布建与所有用户共享的集中管理型数据源。
- SPICE API:可促进数据撷取的触发和监控,例如:在数据加载或 ETL 任务完成时,透过 API 来重新整理 SPICE 上的数据集。
- Permissions API:可让用户新增和管理 AWS IAM 政策对应,这些对应可控制 Amazon QuickSight 中特定用户或群组对 Amazon S3 和 Amazon Athena 等 AWS 资源的存取权。
此外,用户也可以使用这些新的 API,在不同的 AWS 帐户之间移动资产,在 AWS 帐户中或跨 AWS 帐户将资产移至生产的自定义检阅或核准流程,而启用 dev、QA 和生产环境隔离。
参考资源至:Amazon QuickSight adds API support for data, dashboard, SPICE, and permissions
Amazon SES 新增帐户级别的黑名单
Amazon SES 是一个电子邮件发送服务。
此功能可以帮助客户避免将电子邮件发送到以前有遭到退信或投诉事件的地址。客户可以使用此功能来保护其发件人的信誉并提高其邮件的传递速度。
附注:在电子邮件提供商(例如Gmail,Yahoo或Hotmail)中保持健康的发件人信誉可以增加电子邮件到达收件人收件箱而不是垃圾邮件活页夹的可能性。维持积极的发件人信誉的一种方法是不将电子邮件发送到无效的电子邮件地址和不感兴趣的收件人。
Application Load Balancer 针对导流新增算法
Application Load Balancer 是 ELB 当中的其中一种附载平衡器,能够针对 OSI 第七层进行导流。
在此之前,ALB 使用循环(Round-robin)算法将传入的请求分发到后端目标,这些请求会以循环的方式在 Target Group 中所有目标之间分配,而 不考虑目标的使用率与效率,所以当请求具有不同的处理时间或频繁添加或删除目标时,会导致 Target Group 中目标的过度利用或利用不足。 此次更新后,最小未完成请求(LOR)算法 可让用户选择,之后 会将其以最少的未完成请求数发送到目标,处理长期请求或具有较低处理能力的目标就不会负担更多请求。
將 Apache Flink 应用程序完全托管于 Apache Kafka
用户现在可以使用在 AWS 的全托管服务一起运行 Apache Flink 和 Apache Kafka。AWS 透过 Amazon Data Analytics 为 Apache Flink 提供全受管服务,让用户能够快速建置并轻松执行复杂的串流应用程序。用户可以使用这些完全托管的 Apache Flink 应用程序来处理存储在 Amazon VPC 内或 Amazon MSK,Amazon MSK 是一项全受管服务,可让用户轻松建立和执行使用 Apache Kafka 处理串流数据的应用程序。
Apache Flink 是用于处理数据流的分布式框架和引擎。透过 Amazon Kinesis 数据分析,开发人员使用 Apache Flink 建置串流应用程序,以实时转换和分析数据。
Apache Kafka 是构建实时串流数据管道和应用程序的开源平台。使用 Amazon MSK,用户可以使用 Apache Kafka API 来填入数据湖、出入数据库的串流变更,并且供应机器学习和分析应用程序。
参考资源至 : You can now run fully managed Apache Flink applications with Apache Kafka
取得使用AutoML 算法的详细信息与度量指针
以往在 Amazon Forecast 中使用 AutoML 时,客户只能决定使用较好的算法。虽然有用,但缺乏所有模型执行的透明度。
随着新功能的推出,客户不仅能够看到较好的算法,还能获得所有成功算法的度量指针,以及未成功算法的错误消息。前者对于可能想要针对与 AutoML 选择的度量指针进行优化的客户非常有用,而后者则更新汇入的数据,以确保在所有算法中顺利执行。这些可以从 GetAccuracyMetrics 和 DescribePredictor API中查看这些内容。
参考资源至 : Now get additional details/metrics around all your algorithm runs with AutoML
适用于 Kubernetes 的 AWS App Mesh 控制器现在可以使用 Helm Chart
客户现在可以使用 Helm Chart 安装 AWS App Mesh 控制器和注入 Webhook,以搭配 Kubernetes 服务使用。
适用于 Kubernetes 的应用程序网状控制器提供 Kubernetes 风格的用户体验来管理应用程序网状资源。Helm 是一种套件管理工具,可简化安装和管理预先配置的 Kubernetes 服务。客户可以使用 App Mesh,为其应用程序服务取得丰富的观察性、流量控制和安全性功能。
参考资源至 : AWS App Mesh controllers for Kubernetes are now available as Helm Charts
AWS Chatbot 现在支持从 Slack (测试版) 执行命令
AWS Chatbot 现在支持从 Slack 执行 AWS 命令和动作。用户可以直接从 Slack 信道撷取诊断信息、呼叫 Lambda 函数以及建立 AWS Support 案例,让用户的团队能够更快地协同合作和响应事件。AWS Chatbot 使用已熟悉的 AWS 命令行接口语法来支持命令,用户可以在桌面或行动装置上从 Slack 使用该语法。除了执行命令之外,用户也可以透过在 Slack 中单击 CloudWatch 警报通知上的「显示日志」 按钮来撷取 Amazon CloudWatch 日志。AWS Chatbot 支持显示 AWS Lambda 和 Amazon API Gateway 的日志的动作。
若要开始使用命令,请使用其中一个预先定义的 IAM 政策模板在 AWS Chatbot 控制台中设定 AWS Chatbot,然后在 Slack 信道中键入「@aws help」。如果用户已经使用 AWS Chatbot 向 Slack 传送通知,则需要建立新的 IAM 角色或使用其他许可更新现有的 IAM 角色,才能启用执行中的命令。

输入
@aws help查看使用说明

触发 Lambda 函式
参考资源至 : AWS Chatbot now supports running commands from Slack (beta) 图片来源至:Running AWS commands from Slack using AWS Chatbot
二、功能的增强或改动
Amazon EC2 T 系列现在可以在 AWS 帐户级别中设定 Unlimited Mode(无限模式)
EC2 Unlimited Mode 可以让 EC2 T 系列的实例长时间维持高效能运作而没有任何限制。
以往只有 T3 以及 T3a 的实例默认启用 Unlimited Mode,T2 系列默认是没有的,用户若想开启需要在启动机器时手动选择,而此次更新后,AWS 提供了一支 API 能够在帐户层级下设定 Unlimited Mode,如此一来就可以让 T2 系列也默认启用 Unlimited Mode,而不用每次都要手动设定。
参考资源至:Amazon EC2 T instances now support Unlimited Mode at AWS account level
AWS Elastic Beanstalk 新增支持竞价实例
AWS Elastic Beanstalk 是一个快速部署应用程序于 AWS 上的服务,支持以 Java、.NET、PHP、Node.js、Python、Ruby、Go 和 Docker 开发的 Web 应用程序和服务。
以往 Elastic Beanstalk 仅支持 RI 与 On-demend 类型的实例,此次更新后,可以将 Amazon EC2 Spot 竞价型实例添加到环境中。

我们可以在Capacity 的设定当中选择竞价型实例。
参考资源至:AWS Elastic Beanstalk Adds Support for Amazon EC2 Spot Instances
AWS SAM CLI 新增单一指令部署
AWS SAM 是一个开源框架,可用于在 AWS 上构建无服务器应用程序。
此次更新后,新增使用单一指令 : sam deploy 來来部署应用程序。以前,通过 SAM CLI 部署应用程序需要多个步骤,并且需要为 Lambda 提供 Amazon S3 存储桶存放程序代码。SAM CLI 现在会替用户创建和管理此 S3 存储桶。
参考资源至:AWS SAM CLI simplifies deploying serverless applications with single-command deploy
AWS Elemental MediaConvert 现在支持8K 影像编码
AWS Elemental MediaConvert 是一个以档案为基础的影片转码服务,内含广播级功能。它能让用户轻松地建立随选视讯 (VOD) 内容,以在广播和多屏幕进行大规模交付。
此次更新后,新增支持对 8K UHD 影像编码,使影片提供商能够为观看者创建优质的体验并从中获利,并支持最新的消费类显示设备。
参考资源至:8K Resolution Encoding Now Available with AWS Elemental MediaConvert
AWS Key Management Service 支持非对称加密密钥
AWS KMS 是一个用来建立和管理加密数据的加密密钥服务。
以往,客户只能创建对称式加密密钥来做静态加密,现在客户能够创建和使用非对称客户主密钥(CMK)和数据密钥对。

Amazon Redshift 新增功能
Amazon Redshift 是快速、全托管的数据仓储,用户可使用标准SQL 及现有的商业智能(BI)工具分析所有数据。
Amazon Redshift 现在支持空间数据
多态数据类型 GEOMETRY 现在支持多种几何造型,例如:点、线串、多边形、多点、多重线串、多边形和几何集合。此次更新之后,用户可以将 GEOMETRY 数据行新增至 Redshift 数据表,并撰写跨空间和非空间数据的 SQL 查询。此外,Redshift 还增加了 40 多个新的空间 SQL 函数来构建几何形状,导入、导出、访问和处理空间数据。 凭借 Redshift 无缝查询数据湖,客户现在可以透过在空间查询中整合外部表格,轻松将空间处理延伸至数据湖。
Amazon Redshift 新增自動表排序功能
此次更新后,客户可以使用此功能来维护 Redshift 表中数据的排序顺序,以不断优化查询性能。新的自动表排序功能不会影响性能。
现在默认情况下,在已指定排序关键字的 Redshift 表上启用了自动表排序功能。
参考资源至 : Amazon Redshift introduces Automatic Table Sort, an automated alternative to Vacuum Sort
AWS Cost Explorer 每月预测现在已包含支持费用
AWS Cost Explorer 具有易于使用的界面,可让用户可视化、了解和管理用户的 AWS 成本以及随时间的用量。可自定义报告 (包含图表和表格式数据),来分析高阶的成本和用量数据 (例如,所有帐户的成本和用量总计),以及高针对性请求的成本和用量数据。
从今天开始,使用 AWS Support 服务 (开发人员、商业和企业层级) 的客户现在在使用 AWS Cost Explorer 和 AWS Budgets 时,可将这些预期成本包含在其每月的成本预测中。透过此增强功能,客户不再需要手动调整预期的每月成本,即可纳入保费支持成本。
参考资源至 : AWS Cost Explorer monthly forecasts now include Support costs
AWS Storage Gateway 提升磁带和档案网关的效能
AWS Storage Gateway 是一种混合云端储存服务,可让内部部署存取近乎无限的云端储存空间。客户可以利用 Storage Gateway 简化储存管理并降低关键混合云端储存使用案例的成本。其中包括将磁带备份移至云端、利用云端支持的档案共享减少内部部署的储存、为内部部署应用程序供低延迟的 AWS 数据存取,以及各种移转、存盘、处理和灾难复原使用案例。
AWS Storage Gateway 可提高对磁带网关(Tape Gateway)读取数据的效能,以及读取数据和列出档案网关(File Gateway)目录的效能,让用户更快速地存取透过这些网关管理的数据。
- 地端读取 AWS 虚拟磁带库中的磁带
- 高达 2 Gbps,比以往快 3 倍的速度,有助于进一步缩短从 AWS 复原磁带的时间
- 從从网关的本机快取读取档案
- 高达 4.8 Gbps 的速度
- 从 AWS 读取档案
- 高达 0.8 Gbps 的速度
- 列出目录
- 比以往快 4 倍,且提供网络文件系统 (NFS) 或服务器消息块 (SMB) 用户和应用程序更快速地存取档案元数据。
参考资源至 : AWS Storage Gateway increases performance for Tape and File Gateway
Amazon Cognito 现在支持使用Apple 登入
Amazon Cognito 可让用户轻松地将用户注册和身份验证新增到行动应用程序与 Web 应用程序。Amazon Cognito 也可让用户透过外部身分供货商验证用户,并提供临时安全登入数据来存取 AWS 中的应用程序后端资源或 Amazon API Gateway 后的任何服务。
Amazon Cognito 现在支持使用 Apple 登入,让使用 Cognito 进行身分和身分验证的客户更容易接触广泛的 Apple 用户。此功能现在可在 Amazon Cognito 用户集区中使用,费用与其他社交身分提供者相同。
AWS CodeCommit 可针对提取请求执行核准规则工作流程
AWS CodeCommit 是一个完全受管源代码控制服务,可托管安全的 Git 储存库。可让团队轻松在安全且高度可扩充的生态系统中透过程序代码协作。
用户现在可封锁 merging pull requests,直到符合指定的规则为止。以前,用户只能透过自定义 IAM 许可封锁 merging pull requests。用户现在可以建立特别针对提取要求的核准规则,或建立要套用至 repository 中,所有未来提取要求的核准规则模板。如:特定用户的核准或核准总数,这些规则需求在合并程序代码之前必须符合。核准规则和核准规则模板有助于确保只有高质量的程序代码变更会合并到用户的程序代码库中。
参考资源至 : AWS CodeCommit Enables Enforcing Approval Rule Workflows For Pull Requests
AWS DataSync 增加了排程数据传输的能力
AWS DataSync 是数据传输服务,可在现场部署的储存系统和 Amazon S3 或 Amazon Elastic File System (Amazon EFS) 之间自动移动数据。DataSync 会自动处理数据传输相关工作中可能导致移转速度缓慢或加重 IT 操作负担的多项任务,包括执行用户自己的实例、加密处理、脚本管理、网络优化和数据完整性验证。
DataSync 工作排程可让用户定期执行传输工作,以侦测来源储存系统的变更,并将变更复制到目的地。客户使用 DataSync 将数据迁移到 AWS、将数据传输到云端进行分析和处理,以及将数据复制到 AWS 以存盘或业务持续性。
用户可使用 DataSync 控制台或 AWS 命令行接口 (CLI) 来排程任务,而不需要编写和执行脚本来管理重复传输。工作排程会依照用户设定的排程自动执行工作,包括每小时、每日或每周选项。这可让用户使用单一工具来管理和监视数据传输,并确保数据集的变更会定期复制到目的地储存装置。
参考资源至 : AWS DataSync adds the ability to schedule data transfers
使用 IAM 与 AWS Organizations 中的 AWS 帐户群组共享用户的 AWS 资源
AWS Identity and Access Management (IAM) 是一种 Web 服务,让用户能够安全地控制对 AWS 资源的存取。可使用 IAM 来控制 (已登入) 的身分验证和授权使用资源的 (许可)。
现在,用户可在政策中使用新的条件密钥 aws: 主体组织路径,以根据 OU 中主体的成员资格来允许或拒绝存取。这使得在 AWS 环境中拥有的帐户之间共享资源比以往更容易,用户可定义组织中 AWS 资源的 IAM 主体 (用户和角色) 存取权,让用户将帐户整理到组织单位 (Organizational Units) 中,以符合其业务或安全目的。
如:用户可能需要与属于特定 OU 成员的帐户的开发人员和应用程序共享 Amazon S3 储存贮体。若要完成此操作,用户可以指定 aws:主要组织路径条件,并将值设定为连接至储存贮体之资源型原则中的呼叫者的组织单位 ID。当主体尝试存取储存贮体时,AWS 会验证其帐户的 OU 是否符合政策中指定的 OU。
参考资源至 : Use IAM to share your AWS resources with groups of AWS accounts in AWS Organizations
Amazon RDS 新增功能
Amazon RDS 绩效详情现在支持适用于Oracle, PostgreSQL 的 RDS 使用 SQL 层级指针
Amazon RDS 绩效详情支持适用于 Oracle, PostgreSQL 的 Amazon RDS 上的 SQL 层级指针,因此您可以在几秒钟内识别高频率、长时间执行和卡住的 SQL 查询。
以前,在数据库上收集效能数据需要设定和维护监视应用程序与相关资源。在没有专业技能的情况下,相关性能数据需要花费数小时。要查找感兴趣的查询,例如卡住或长时间运行的 SQL 查询,意味着每次调查一个查询。
RDS 绩效详情可让非专家和专家在几秒钟内识别最常见的 SQL 负载,以及它们在可视化仪表板上的来源。现在,RDS 绩效详情也会收集 SQL 层级指针,例如平均延迟、每秒呼叫数,以及每次呼叫传回的数据列。您可以判断 SQL 查询是否需要太长时间才能完成,或者是否以不同的速率呼叫特定 SQL 查询,然后对您的应用程序进行改进,例如优化慢速 SQL 查询、新增索引至您的数据库,以及缩放您的数据库。
Amazon RDS 绩效详情是 RDS 的数据库效能调整和监控功能,可让您以视觉方式评估数据库的负载,并判断何时何地采取行动。只要在 Amazon RDS 管理控制台中单击鼠标,就可以将全受管的效能监控解决方案新增到 Amazon RDS 数据库。RDS 绩效详情包含在支持的 Amazon Aurora 丛集和 Amazon RDS 实例中,并将七天的效能历史记录储存在滚动窗口,无需额外费用。如果您需要长期保留,您可以选择支付长达两年的效能历程记录保留费用。
参考资源至 : Amazon RDS Performance Insights Supports SQL-level Metrics on Amazon RDS for Oracle 参考资源至 : Amazon RDS Performance Insights Supports SQL-level Metrics on Amazon Aurora with PostgreSQL Compatibility
Amazon Forecast 新增支持各种百分比生成预测
Amazon Forecast 是一个全托管的时间序列服务,客户透过提供历史数据给 Amazon Forecast,便可以预测未来值。
以往该服务仅以三个默认百分比(10%, 50%, 90%)生成预测。此次更新后,支持预测介于 1% 到 99% 之间的任何百分比的预测(包括平均预测)。
参考资源至 : Amazon Forecast can now support generating predictions in any quantile
AWS Lambda 支持 Kinesis 和 DynamoDB 并行处理
AWS Lambda 是一个无服务器的服务,透过事件触发程序代码,只需为使用的运算时间支付费用,一旦未执行程序代码,就会停止计费。
默认情况下,Lambda 会批量处理分片(Shard)中的数据,在单一事件来源映像(Single event source mapping)的情况下,Lambda 调用的最大数量等于 Kinesis 或 DynamoDB 分片的数量。
以次更新后,新增 Parallelization Factor 功能,可以同时触发多个相同 Lambda 来处理Kinesis 或 DynamoDB 的同一个分片。

从 1(默认)到 10 来指定 Lambda 从同一分片并行处理的数量。

图片来源至:New AWS Lambda scaling controls for Kinesis and DynamoDB event sources
参考资源至:AWS Lambda Supports Parallelization Factor for Kinesis and DynamoDB Event Sources
AWS X-Ray 功能增強
AWS X-Ray 可协助开发人员分析和侦错生产、分布式应用程序,帮助了解应用程序及其基础服务的执行方式,以识别和疑难解答效能问题与错误。
AWS X-Ray 提供改善的追踪分析和识别服务中断
此次更新之后,用户可以使用 trace maps 来快速了解单一呼叫中,触发服务的路径和顺序,并判断个别服务的上游和下游呼叫。此外,也可以直观地识别错误的起源位置,以及它如何影响其他服务。
以往,用户可以使用追踪时间轴来了解个别要求的时间花在哪里,并获取每个远程呼叫的详细数据,现在透过 trace maps 将更容易理解哪个服务导致错误/故障和/或延迟增加。
除了 trace maps 之外,AWS X-Ray 也在 service map 中启动新功能,用户能够快速识别并隔离导致效能下降或错误率增加的服务。例如:用户可以专注于受影响的服务,并藉由只检视上游和下游服务的状态和指针来判断其他服务如何受到影响。
参考资源至:AWS X-Ray offers improved trace analysis and identification of service disruption
AWS X-Ray 推出对 Amazon CloudWatch Synthetics Canaries 的支持
AWS X-Ray 推出 Amazon CloudWatch Synthetics 的支持 (预览) 让开发人员和 DevOps 工程师能够追踪监控 Canaries 对 Web 应用程序端点和 URL 的请求。
Amazon CloudWatch Synthetics 是一项完全托管的综合监控服务,允许开发人员和DevOps工程师使用称为 Canaries 的可配置脚本(运行24×7)查看其应用程序终端节点和 URL 请求。如果脚本定义的某些功能无法正常工作,Canaries 会提醒您。可以自定义 CloudWatch Synthetics Canaries,以检查应用程序中的可用性、延迟、交易、无效链接、分步任务完成、页面加载错误、UI对象加载延迟、复杂需求流向。
AWS X-Ray 的这项功能可让您快速判断 CloudWatch Synthetics 监督中是否有问题、判断问题的根本原因,以及识别受影响的上游和下游服务。用户亦可利用 CloudWatch Synology Canaries 查看效能的瓶颈与趋势,将最终用户的体验与 Canaries 进行比较,并判断端点和 URL 的适当测试涵盖范围。
参考资源至:AWS X-Ray launches support for Amazon CloudWatch Synthetic Canaries
Amazon Lex 当前支持情绪分析
Amazon Lex 是一种服务,用于使用语音和文字在任何应用程序建立交谈界面。
Amazon Lex 现在支持与 Amazon Comprehend 整合情绪分析。以以往,你必须实现使用 Amazon Comprehend API 来评估用户情绪自定义逻辑。此次更新之后,只要在 Amazon Lex console 中启用情绪分析,Amazon Comprehend 便会使用自然语言处理来检测文本中的整体情绪,并以正面、负面、中性或混合方式响应。
AWS ECR Events 现在支持援 EventBridge(Amazon CloudWatch Events)
Amazon Elastic Container Registry (ECR) 是一个全受管的 Docker 容器登录档,可让开发人员轻松存放、管理以及部署 Docker 容器映像。
Amazon EventBridge 是一种无服务器事件联机服务,可将用户的应用程序与来自各种来源的数据连接起来。
此次更新之后,ECR 事件可以在成功推送 images 后触发后续动作,例如:启动 Pipeline 或发布消息之类的操作。用户可以使用 images 推送或删除事件作为触发器,在 EventBridge 帐户中建立 Rule,将推送事件连接到 AWS CodePipeline 等 AWS 服务,例如:启动部署的动作;推送或删除事件也可用来触发 AWS Lambda 函数,将讯息张贴到您的 Slack、Chime 或团队空间等应用方式。
Amazon Kinesis Producer Library(KPL)現在支持 ListShards API,以有效地扩展生产者应用程序
Amazon Kinesis Data Streams 是可大规模扩展且耐用的实时数据串流服务。 Kinesis Producer Library(KPL)简化了生产者应用程序(producer applications)的开发,使开发人员能够达到 Kinesis Data Streams 的高写入吞吐。
生产者应用程序通常需要在数据流放大或缩小之后,去发现新的分片(shard)。此次更新之后,Amazon KPL 0.14.0 版将 DescribeStream 替换成 ListShards API,与支持每个帐户 10TPS 的 DescribeStream 相比,ListShards API 支持每个串流 100TPS。对于具有 10 个串流的帐户,使用 KPL v0.14.0 将为 shard discovery 提供高 100 倍的呼叫速率,因此消除了 DescricribeStream API 的限制。
Amazon Chime Voice Connector 现在支持 SIPREC
Amazon Chime Voice Connector 现在支持通过基于 SIP 的媒体录制(SIPREC)进行音频串流传输。如此一来,用户可以使用内部部署电话系统的实时通话音频,轻松建置机器学习、分析和处理应用程序。在尚未发布此服务前,用户必须整合和部署昂贵的内部部署硬件和软件,或是对企业语音网络进行破坏性的变更。
SIPREC 串流功能会从内部部署专用交换机 (PBX) 和会谈边界控制器 (SBC) 中导入电话通话音频;并自动将它传送到 Amazon Kinesis Video Streams,用户建立的应用程序可以存取该音频。用户可以将此功能搭配 AWS 机器学习服务使用并建置可协助遵循合规和质量保证的应用程序。例如,用户可以将该功能与 Amazon Transcribe 整合并转译和储存涉及金融交易的电话,以支持争议解决;或与 Amazon Comprehen 进行情绪分析整合,为用户提供客户服务电话的实时反馈。
AWS WAF 推出 AWS Managed Rules
AWS WAF 宣布 AWS Managed Rules (AMR),这是由 AWS 威胁研究团队策划和维护的一组 AWS WAF 规则。只需单击几下,AMR 即可帮助保护用户的Web应用程序免受新出现的威胁,因此用户无需花费时间研究和编写自己的规则。 AMR 是以常见的因特网安全威胁为基础,包括 OWASP Top 10出版物中提到的安全风险。AMR 还包括以 Amazon 威胁情报为基础的 IP 信誉列表,有助于减少机器人流量暴露。
除了提供 AMR 之外,AWS 亦更新了 AWS WAF 的 API 和控制台体验,让用户可以将多个 AMR 新增至 Web 访问控制列表 (Web ACL),或撰写数百个自己的规则。新的 API 支持完整逻辑运算符、链结式文字转换,以及以 JSON 格式表示规则的能力。用户也可以设定任何子网掩码,以建立符合弹性 IPv4 和 IPv6 CIDR 范围的条件。最后,AWS WAF 的新 API 可让用户使用 AWS CloudFormation 模板建立 Web ACL 和更新规则。
Amazon Comprehend 推出实时自定义分类
Amazon Comprehend 现在支持实时自定义分类。用户可以使用实时的「自定义分类」基于您自己的业务规则实时了解、标记和路由信息。例如,用户可以立即对支持请求的内容进行分类,并将其分类传送给适当的支持团队。或者,用户亦可以在网站评论流入时自动对其进行审核。在此推出之前,客户将「自定义分类」与其企业特定卷标一起使用,并以异步方式分类文件。现在,客户可以根据使用案例选择实时或异步自定义分类。
建立自定义模型很简单。用户可以为用户要使用的每个卷标提供文字实例,以及在这些卷标上理解列车以建立自定义模型,不需要任何机器学习经验。对于实时分类,用户可以为终端配置符合用户需求的容量。用户也可以使用应用程序自动缩放并动态扩展容量,以将成本降至最低,并以低延迟符合用户需求。Application Auto Scaling 支持排程扩展和目标追踪。排程扩展可让用户根据排程进行扩展,目标追踪可让用户在设定的层级维持容量使用率。
使用自定义分类,用户可以建立自定义模型,而不需使用任何程序代码。SDK 可供用户将用户的客户分类器整合到用户当前的应用程序。使用用户的自定义模型,可以轻松调节网站评论、分类客户意见,以及组织工作组文件。
参考资源至 : Amazon Comprehend launches real time custom classification
AWS Lambda 现在支持异步呼叫的最大事件年龄 (Maximum Event Age) 和最大重试尝试次数 (Maximum Retry Attempts)
AWS Lambda 现在支持两项新功能,为开发人员提供如何处理异步呼叫的其他控制:最大事件时间和最大重试尝试次数。当用户以异步方式叫用函数时,Lambda 会将事件传送至队列。一个单独的进程从队列中读取事件并运行你的函数。这两项新功能提供了控制重试事件的方式,以及它们可以在队列中保留多久的方式。
-
事件年龄上限 (Maximum Event Age) 当函数在执行之前传回错误时,Lambda 会将事件传回队列,并在默认情况下尝试再次执行该函数最多 6 小时。使用「事件保留时间上限」,用户可以设定队列中事件的生存时间,从 60 秒到 6 小时。这可让用户根据事件年龄移除任何不想要的事件。
-
尝试次数上限 (Maximum Retry Attempts) 当函数在执行后传回错误时,Lambda 默认会尝试再执行两次。使用 “重试次数上限”,用户可以自定义从 0 到 2 次的重试次数上限。如此可让用户选择继续处理新事件,但重试次数较少或不重试次数。
有了這兩個功能,當符合以下兩個條件之一時,就會捨棄事件,或傳送至無效字母佇列和/或 Lambda 目的地:「重試嘗試」 達到其最大值,或「事件年齡」 達到其最大值。
参考资源至 : AWS Lambda Now Supports Maximum Event Age and Maximum Retry Attempts for Asynchronous Invocations
共享VPC 现在支持网络负载平衡器
Amazon VPC 现在支持在共享 VPC 中建立和管理网络负载平衡器 (NLB)。使用 NLBs 搭配 VPC 共享,用户现在可以在由同一个 AWS 组织中集中管理帐户所拥有的 VPC 的子网中路由流量。
若要开始使用,VPC 拥有者会使用资源存取管理员与用户的帐户共享子网。然后,用户可以在共享子网中检视、建立、修改和删除 NLBs 或负载平衡目标 (例如 Amazon EC2 和 Amazon ECS )。用户也可以使用 NLBs 建立 AWS PrivateLink 服务,让用户能够从其他 VPC 或现场部署网络私下存取共享子网中的服务,而不需要使用公用 IP 或流量穿越因特网。
AWS Managed Services (AMS) 现在支持 Windows 2019
AWS Managed Services (AMS) 推出适用于 Windows 2019 的支持。用户现在可以在 AMS 管理的登陆区中推出标准和安全性增强的 Windows 2019 AMI。Windows 2019 支持已扩充客户应用程序的可寻址清查,这些应用程序可迁移到 AMS 以进行持续作业,只需最少重构。
支持 Windows 2019 安全增强 AMI 的 AMS 为用户提供了一个托管的基础设施,提供与互联网安全中心(CIS)操作系统安全配置基准 -1.0 一致的额外安全设置。根据默认,增强安全性的 AMI 提供更高的安全性基准,用户可以在其中设定应用程序以达到所需的符合性层级。
参考资源至 : AWS Managed Services (AMS) now supports Windows 2019
Amazon Transcribe 现在支持7 种其他语言的语音转文本
Amazon Transcribe 是一种自动语音识别 (ASR) 服务,可让您轻松地为应用程序新增语音转文字功能。
Amazon Transcribe 现在新增支持以海湾阿拉伯文、瑞士德文、希伯来文、日文、马来文、Telugu 和土耳其语言进行音频和视讯转译。目前为止,Amazon Transcribe 总共支持 31 种语言。
参考资源至:Amazon Transcribe Now Supports Speech-to-text in 7 Additional Languages
Amazon Route 53 现支持私有托管区域的重迭命名空间
Amazon Route 53 是一种可用性高、可扩展性强的云端域名系统 (DNS) Web 服务。
此次更新之后,用户可以将相同的 Virtual Private Cloud 与私有托管区域(private hosted zones)建立关联,即使它们的命名空间是重迭的(例如:如果其中一个托管区域是另一个托管区域的子域:acme.example.com 和 example.com)。
使用情境:此改动可以让用户轻松地管理在整个组织的许可。
- 组织中的中央团队管理主托管区域(例如:example.com),同时允许独立团队管理该主托管区域自己的子域(例如:acme.example.com 和 zenith.example.com)。
参考资源至:Amazon Route 53 Now Supports Overlapping Namespaces For Private Hosted Zones
Tag:Alexa Voice Service (AVS) Integration, Alternative Transcriptions, Amazon Athena, Amazon Aurora MySQL 5.7, Amazon Chime Voice Connector, Amazon CloudWatch, Amazon CloudWatch Contributor Insights, Amazon CloudWatch ServiceLens, Amazon CloudWatch Synthetics, Amazon CloudWatch Synthetics Canaries, Amazon Cognito, Amazon Comprehend, Amazon DynamoDB, Amazon EBS, Amazon EC2 Auto Scaling, Amazon EC2 T, Amazon Elastic Block Store, Amazon Elastic Container Registry, Amazon EMR 6.0, Amazon Forecast, Amazon FSx for Windows File Server, Amazon Kinesis Data Firehose, Amazon Kinesis Producer Library, Amazon Lex, Amazon Neptune, Amazon QuickSight, Amazon RDS, Amazon Redshift, Amazon Route 53, Amazon S3, Amazon SES, Amazon Transcribe, Apache Flink, Apache Hive Metastore, Apache Kafka, API, Apple, Application Load Balancer, Aurora Global Database, Auto Scaling groups, AutoML, AWS App Mesh, AWS AppSync, AWS Chatbot, AWS CloudTrail, AWS CodeCommit, AWS Config, AWS Cost Explorer, AWS DataSync, AWS ECR Events, AWS Elastic Beanstalk, AWS Elemental MediaConvert, AWS Glue, AWS IoT Core, AWS Key Management Service, AWS Lambda, AWS Managed Microsoft AD, AWS Managed Rules, AWS Managed Services, AWS Organizations, AWS SAM CLI, AWS Single Sign-On, AWS Storage Gateway, AWS System Manager, AWS Toolkit for Visual Studio Code, AWS WAF, AWS X-Ray, Azure AD, CDK Explorer, Cloud Debugging, CloudTrail Insights, DynamoDB, Elasticsearch clusters, EventBridge, Helm Chart, Hive 3, IAM, IoT Configurable Endpoints, IoT Custom Domains for Configurable Endpoints, IoT Fleet Provisioning, IoT Secure Tunneling, JetBrains IDE, Kinesis, KPL, Kubernetes, ListShards API, LLAP, LOR, Maximum Event Age, Maximum Retry Attempts, metadata catalog, Microsoft SQL Server, Oracle, Parallelization Factor, Pipeline, PostgreSQL, PowerShell, Replication Time Control, Self-Managed Active Directory with Secure LDAP, SIPREC, Slack, SPICE, SQL, Statistical Multiplexing, UDF, Unlimited Mode, VMware, VPC, Windows
You may also like

【焦點新聞|Microsoft Build 2022】

【焦點新聞】0428-0511 AWS 服務更新
