

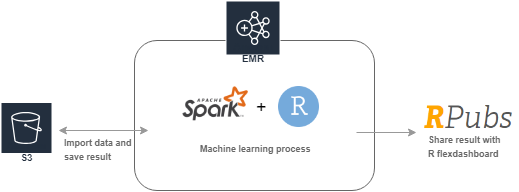
在 AWS EMR 使用 R 與 Spark 進行機器學習
Amazon EMR 是透過 AWS 雲端虛擬機器集群的分散式運算服務,可用於分析和處理海量資料。EMR 集群利用 Hadoop 的開源框架管理,使用戶可以專注於資料處理和分析,不用花時間煩惱 Hadoop 集群的配置、管理和優化,也無需擔心所需要的計算能力。
當研究人員訓練機器學習或深度學習模型時,大量的數據和多層演算法使得模型的訓練變得緩慢。 這時候可以透過 AWS EMR 服務與基於 Spark 的內存處理架構相結合,透過分散式運算,讓用戶可以在很短的時間內完成資料分析。
情境
今天主要介紹如何在 AWS EMR 服務中使用 R studio 控制 Spark 來訓練多個機器學習模型,以分析影響白酒評級的重要因素,在這個資料集中白酒的評級為1到10分,而可能影響這個評級的原因可能為糖分、PH值、酒精含量以及各種白酒內的酸性成分等等一共12個原因,令人感興趣的是,要如何在這麼多的成分中,找到那些重要或者不重要的成分,讓事前判斷變得更清晰簡單。
在機器學習的各種應用場景裡,要在眾多雜訊中找到重要特徵是常被企業所重視的,特別是在節省成本以及提升決策效率上。在這個實驗裡,我們在 Rstudio 中建立決策樹、線性模型、隨機森林以及樸素Bayes四種監督式學習模型,用來尋找會影響白酒評分的重要特徵。其中 Rstudio 是一個資料分析師相當熟悉的運算環境,很常被用在統計分析,在這個環境中即使資料分析師沒有資訊工程背景也能很快的體驗在雲端上的分析資料。實驗的最後,我們通過 R 的 flexdachboard 套件呈現機器學習分析的結果,並將這個結果上傳到 Rpubs 開源社群以分享你的成果。
 * *
* *
步驟
首先,我們建立一個可以開啟 R 軟體的安全連線環境。
-
在 EC2 服務中創建 安全組 ,依循下述資訊配置安全組:
-
安全組名稱:
EMR Security Group -
描述:
Security for the EMR -
VPC:
No VPC
-
-
設定安全組規則, 選擇 入站 並點選 添加規則。 使用下圖的值,設定以下規則:
-
可以讓管理員 SSH 訪問 Master EC2。
-
可以讓任何人存取的 8787 Port。
-

在默認情況下,RStudio Server在 8787 port 上執行,並接受遠端連線。因此資料科學家也可以利用管理者所設定的使用者權限一起參與分析工作。
創建 EMR 集群
在這部分我們將在AWS console上創建EMR集群,並部署所需要的軟體版本以及安全設定。
-
在 AWS 管理控制台 中,開啟 服務 並點選 EMR 服務。
-
點選 創建集群 並點選 轉到高級選項。
-
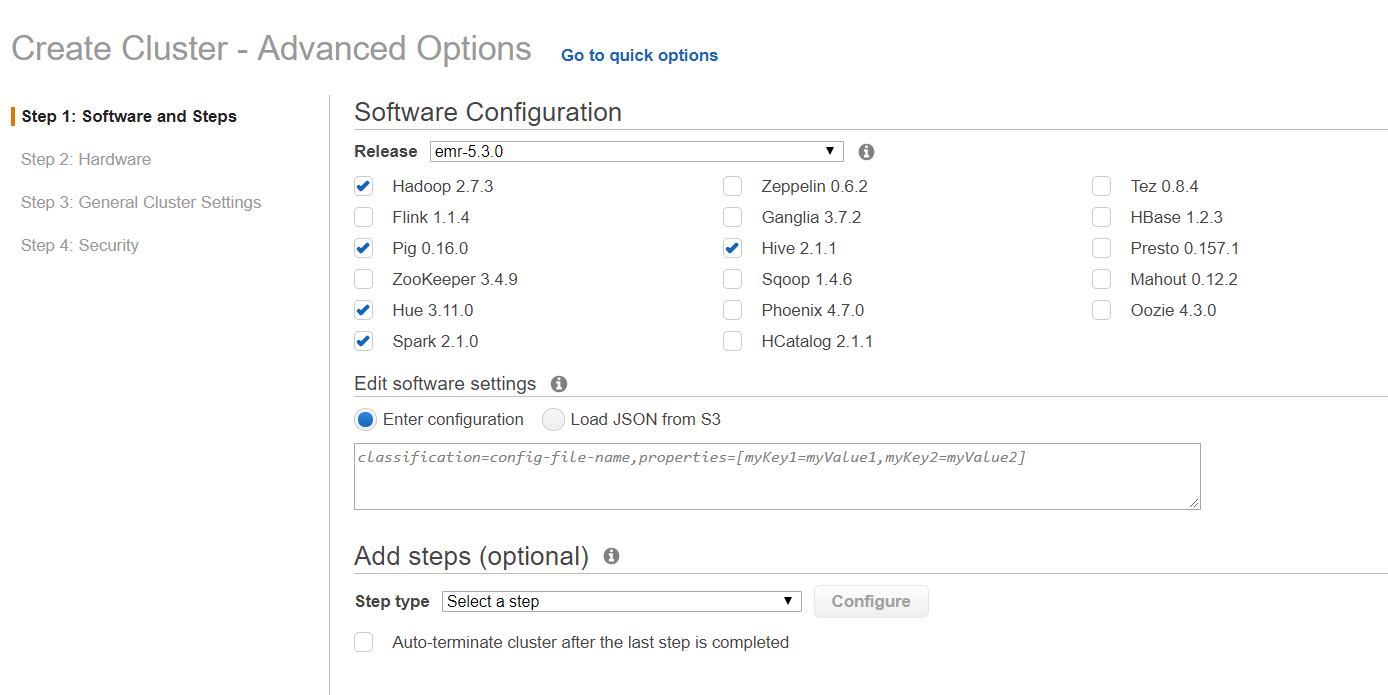
在步驟1: 軟件與步驟: 從發行版選單選擇 EMR 5.3.0 並勾選下圖所示之方框。
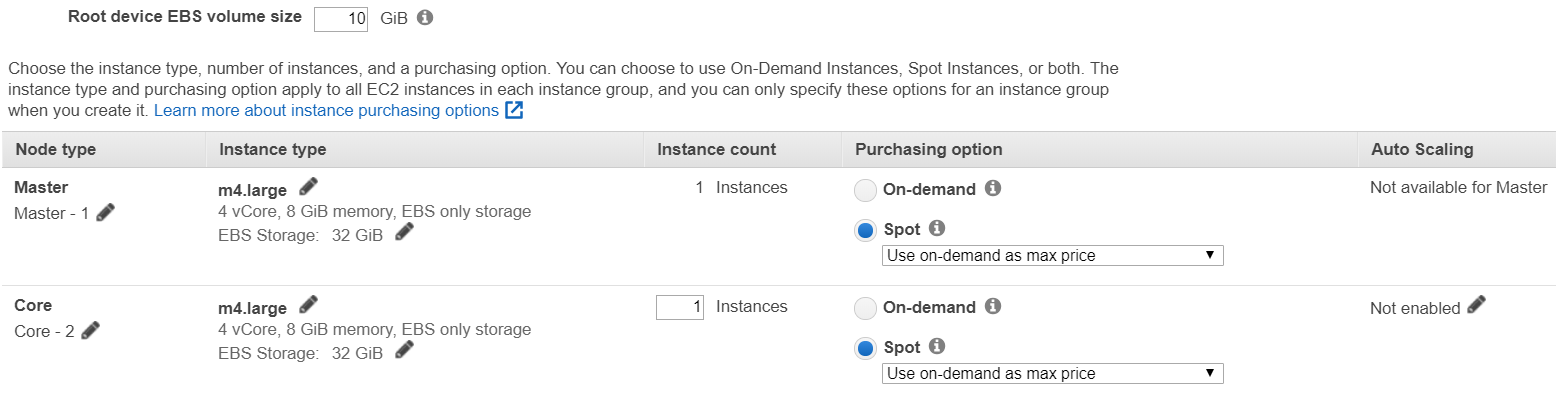
- 選擇 m4.large 實例並點擊方框 Spot。 >選擇 Spot Instance 可以讓您的 EMR 成本大幅降低,建議設定在僅用於暫時參與運算的機器。
-
在一般選項的頁面,集群名稱輸入 My cluster,並選擇一個你想儲存資訊的S3儲存桶。
在這之前,請先建立一個S3儲存桶。
-
在安全選項的頁面, 選擇先前已經建立好的 EC2 key pair 以及 EC2安全組。 在權限的部分,選擇 自定義 並更改 EC2 實例配置文件為 mylab_EMR_role。
由於default role的權限不足,我們必須自己創建一個role,在這個role裡我們attach了:
AmazonEC2FullAccessAmazonElasticMapReduceFullAccessAmazonS3FullAccess
詳細的創建role流程請參閱: AWS Documentation: Creating IAM Roles.
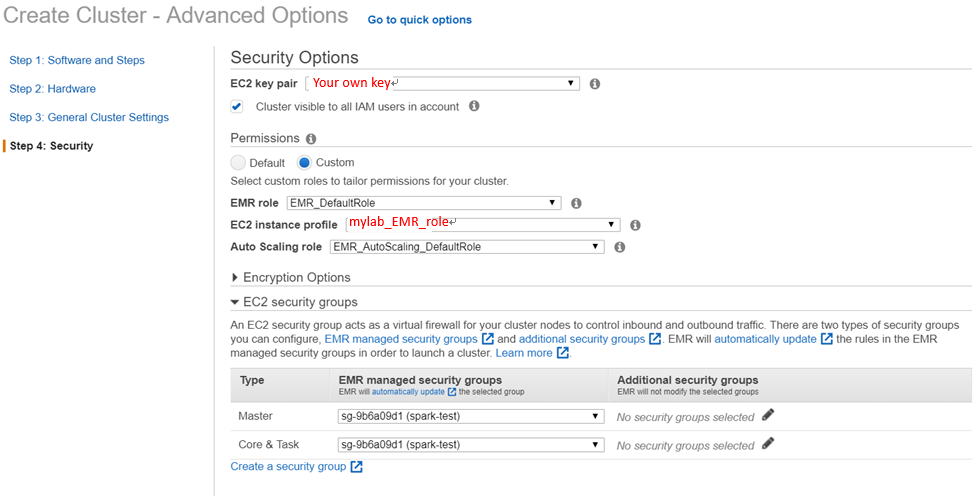
- 確認設定都完成後,點選 創建集群。
建立EMR集群可能會花你幾分鐘的時間,如果狀態顯示 等待中,這表示你已經成功建立了EMR集群。
設定 Rstudio 環境
首先先選擇剛剛建好的 EMR 集群,用指定的安全組金鑰 (.pem key) 用 SSH 的方式連結 Master public DNS EMR 集群。接著在主實例 EC2 的操作介面貼上以下代碼:
-
系統更新
sudo yum update sudo yum install libcurl-devel openssl-devel -
安裝 RStudio Server > 在這裡我們不必擔心rstudio的版本問題,直接從以下網址下載並安裝就行了
wget -P /tmp https://s3.amazonaws.com/rstudio-dailybuilds/rstudio-server-rhel-0.99.1266-x86_64.rpm sudo yum install --nogpgcheck /tmp/rstudio-server-rhel-0.99.1266-x86_64.rpm -
創建 Rstudio 使用者並設定密碼 >我們將用這個使用者登入,請記得自己所設定的密碼。
sudo useradd -m rstudio-user sudo passwd rstudio-user su rstudio-user -
給定 yarn 使用者 Hadoop 的權限
export HADOOP_USER_NAME=yarn -
建立新的 HDF directory
HDF (Hierarchical Data Format) 是一種分布式儲存檔案格式,Spark 可以用 HDF 存儲和處理不同類型的大量科學數據。
hadoop fs -mkdir /user/rstudio-user
hadoop fs -chmod 777 /user/rstudio-user
R 腳本
在這之前,請先透過瀏覽器,連接 master EC2 的 Public DNS ec2-XXXXXX.compute-1.amazonaws.com:8787,並使用剛剛創建的 Rstudio user 登錄至 RStudio Server。
-
在 R 中設定 spark 的系統環境
Sys.setenv(SPARK_HOME="/usr/lib/spark") config <- list() -
安裝並讀取所需的 R 套件
install.packages("dplyr") install.packages("sparklyr") install.packages("data.table") install.packages("ggplot2") library(dplyr) library(sparklyr) library(data.table) library(ggplot2) -
將 Spark 與 R 連接
sc <- spark_connect(master = "yarn-client", config = config, version = '2.1.0')
由於 Spark 版本必須搭配 sparklyr 套件的版本才能順利執行,在這之前請先確認 EMR 集群的 Spark 版本是 2.1.0。
-
從 S3 儲存桶讀取資料,並寫入 csv 檔案到 HDF
Wine <- fread('https://s3.amazonaws.com/ecv-training-jj-v/wineQualityWhites.csv') Wine`$`quality<-as.factor(Wine`$`quality) Wine<-Wine[,-1] Wine_tbl <- copy_to(sc, Wine) spark_write_parquet(Wine_tbl, path="/user/rstudio-user", mode="overwrite", partition_by = "dt") -
準備訓練及測試資料集
#Transform our dataset, and then partition into 'training' and 'test'. Wine_partitions <- Wine_tbl %>% sdf_partition(training = 0.7, test = 0.3, seed = 10997)
開始使用機器學習進行分析
在以下例子,我們採用白酒資料集,在 R 語言利用機器學習的方法分析影響白酒等級的重要成分。
-
建立機器學習模型
#設定依變數及自變數 ml_formula <- formula(quality ~ fixed_acidity + volatile_acidity + citric_acid + residual_sugar + chlorides + free_sulfur_dioxide+total_sulfur_dioxide+ density + pH + sulphates + alcohol) #Linear Model ml_lm <- Wine_partitions$train %>% ml_linear_regression(ml_formula) #Random Forest ml_rf <- Wine_partitions$train %>% ml_random_forest_classifier(ml_formula) #Naive Bayes ml_nb <- Wine_partitions$train %>% ml_naive_bayes(ml_formula) #Desision Tree ml_dt <- Wine_partitions$train %>% ml_decision_tree(ml_formula) -
捕捉重要特徵
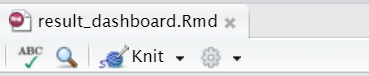
ml_models <- list( "Linear" = ml_lm, "Decision Tree" = ml_dt, "Random Forest" = ml_rf, "Naive Bayes" = ml_nb ) feature_importance <- data_frame() for(i in c("Decision Tree", "Random Forest")){ feature_importance <- ml_tree_feature_importance(ml_models[[i]]) %>% mutate(Model = i) %>% rbind(feature_importance, .) } feature_importance %>% ggplot(aes(reorder(feature, importance), importance, fill = Model)) + facet_wrap(~Model) + geom_bar(stat = "identity") + coord_flip() + labs(title = "Feature importance", x = NULL) + theme(legend.position = "none") -
比較模型
n <- 10 format_as_character <- function(x){ x <- paste(deparse(x), collapse = "") x <- gsub("\\s+", " ", paste(x, collapse = "")) x } format_statements <- function(y){ y <- format_as_character(y[[".call"]]) y <- gsub('ml_formula', ml_formula_char, y) y <- paste0("system.time(", y, ")") y } ml_formula_char <- format_as_character(ml_formula) all_statements <- map_chr(ml_models, format_statements) %>% rep(., n) %>% parse(text = .) res <- map(all_statements, eval) result <- data_frame(model = rep(names(ml_models), n), time = map_dbl(res, function(x){as.numeric(x["elapsed"])})) result %>% ggplot(aes(time, reorder(model, time))) + geom_boxplot() + geom_jitter(width = 0.4, aes(color = model)) + scale_color_discrete(guide = FALSE) + labs(title = "Model training times", x = "Seconds", y = NULL)
儲存 R.data
為了將結果呈現給 R flexdashboard,我們直接保存分析結果為 R.data。R.data 不限定資料形式,能儲存函數以及分析結果並且快速地被 R 讀取。
首先,執行下面的 R code:
save(feature_importance,Wine,Wine_tbl,ml_dt, ml_nb, ml_rf, ml_lm, file = '/home/rstudio-user/result.Rdata')
利用 CLI 從主實例複製這個結果到 S3
aws s3 cp /home/rstudio-user/result.Rdata s3://[your bucket name]
在線上儀錶板呈現分析結果
為了節省一些成本,您無需在主實例上進行以下步驟。您可以在地端運行下述 R 腳本,並且在開源的 R 社群-RPubs 共享這個分析結果。
安裝所需的 R 套件:
install.packages("flexdashboard")
install.packages("markdown")
在 Rstudio 運行 R Markdown:
- 建立一個新的 R Markdown 腳本:
-
貼上下面連結中的 R markdown 腳本: https://github.com/JellalYu/Sparkling-water-machine-learning-with-R-AWS-EMR/blob/master/flexdashboard_sparkonly.txt
-
在 Rstudio 中點擊 knit。
- 在右上角點擊 publish。
- 發布到 Rpubs。 Rpubs 是一個完全開源的 R 社群,您可以在其中分享分析結果。
< * * *
* * *
結論
現在您已經學會如何使用 EMR 與 R 腳本建立一個分析影響白酒的重要因素的機器學習模型,並將這個結果發布到開源的社群,和其他研究人員分享您對於重要特徵選取的分析洞見。和這個例子不同的是,當有些資料很龐大,或是機器學習模型的訓練很費時,就可以很明顯地感受到EMR集群帶來的優勢,建議您可以嘗試使用更大的訓練數據集。 而 EMR 亦可很好地應用在資料處理流程上,當企業要處裡大量數據時,結合 HDF 以及 Spark 的分散式的運算,將會是個很適合節省成本的工具。
參考資料
You may also like

【焦點新聞|Microsoft Build 2022】

【焦點新聞】0428-0511 AWS 服務更新

1 Comment
好實用的一篇文 !