

SageMaker Ground Truth 建立高度精確資料集
前言
現今機器學習多以 監督式學習 (Supervised learning) 為主流,監督式學習是利用大量的數據使機器學習或建立一個模式,並以此模式對新的資料進行分類或預測。 就像人們看到了一隻兔子,一開始當沒有任何人告訴我們他是兔子時,我們可能會不了解他是什麼。但當有人給我們看了一千次兔子,並告訴我們他是兔子。下一次我們在看到時,便知道他是兔子。
而銀行常面臨的課題是信用卡交易資料,在大量的交易資料中可能包含正常的交易或是欺詐行為,透過機器學習即時預測可以避免欺詐行為所造成的損失。因此我們了解影響監督式學習準確性其一的關鍵是 訓練資料集,確保訓練資料集的正確性十分重要。
在許多公司中,對於特殊訓練集需要花費許多時間進行標籤,像是醫學影像的識別。為上千張圖像或文本加標籤需耗費許多時間與人力成本。
為了解決人力成本過高與人手不足等問題,Amazon 推出了 Amazon SageMaker Groud Truth 加速建構高準確度的資料集,並減少添加標籤所造成的人力成本,最高可將成本下降70%,而這些成本的節省是透過使用機器學習自動標籤資料來達成。
情境
透過這個 Lab,您將使用 Amazon SageMaker Groud Truth 快速為資料集添加標籤,對貓與狗的圖片進行分類與添加標籤,而此 Lab 將使用公共勞動力搭配自動標籤技術進行,並把分類結果儲存在 S3 Bucket 中。
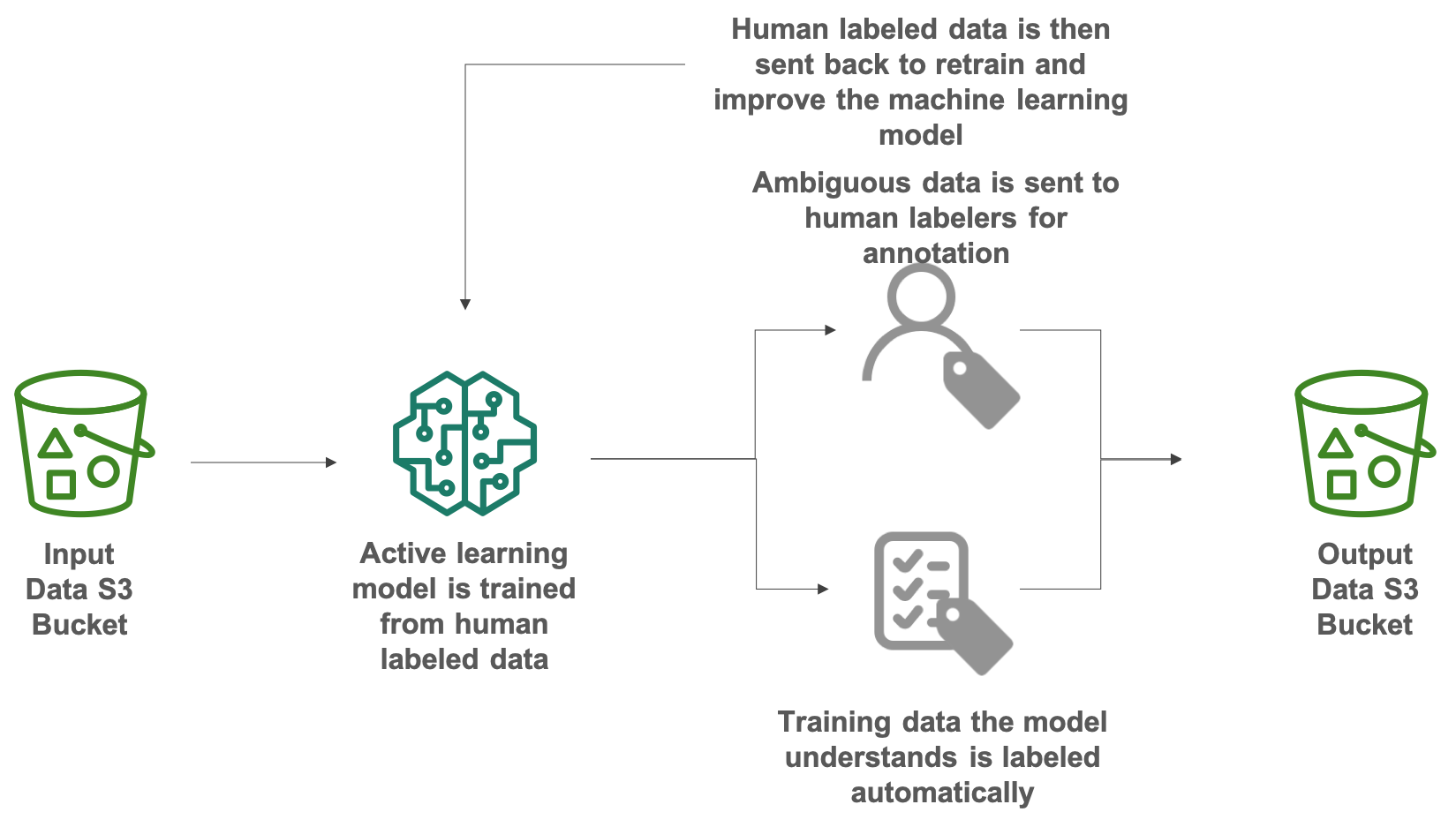
步驟
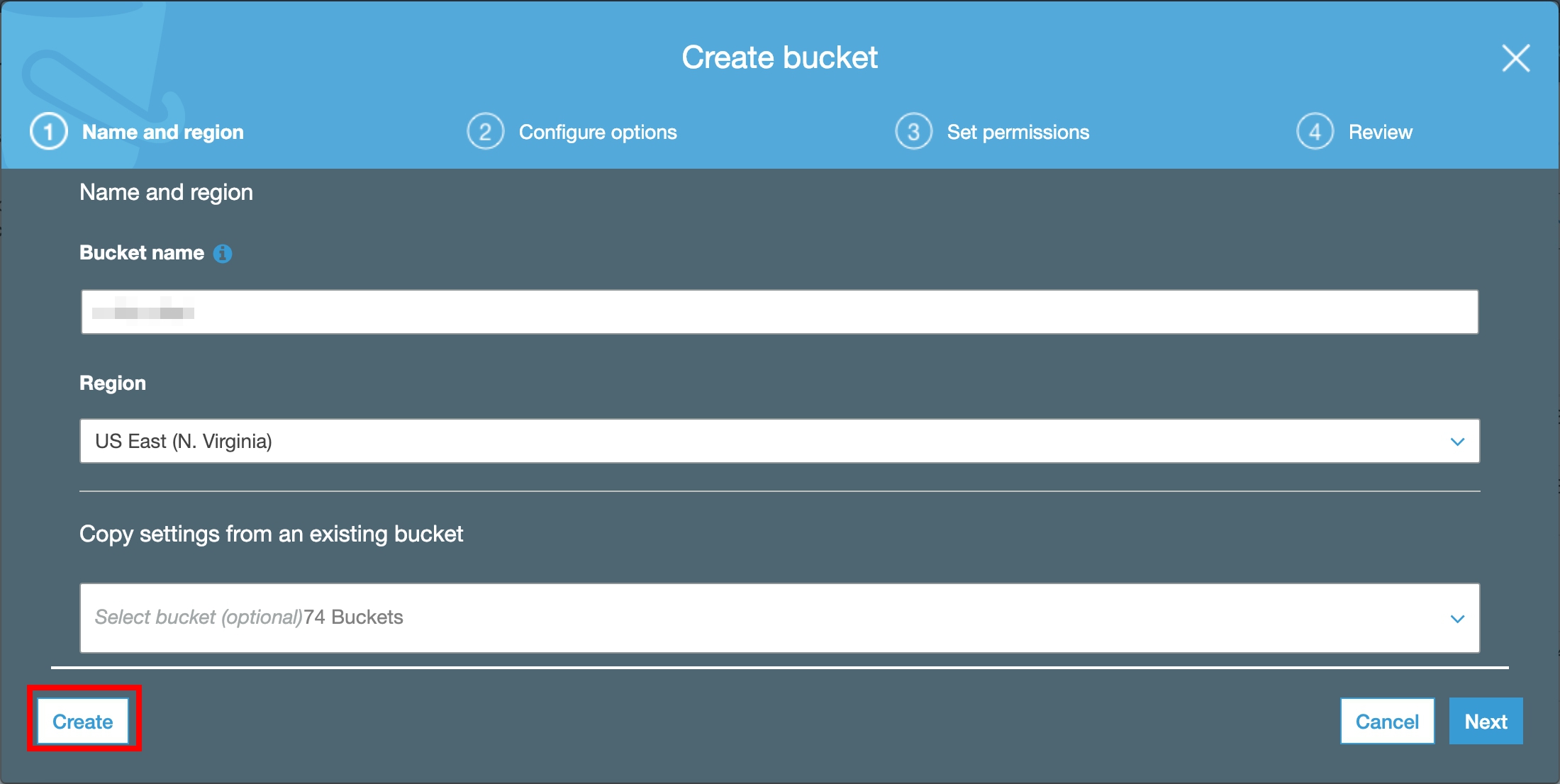
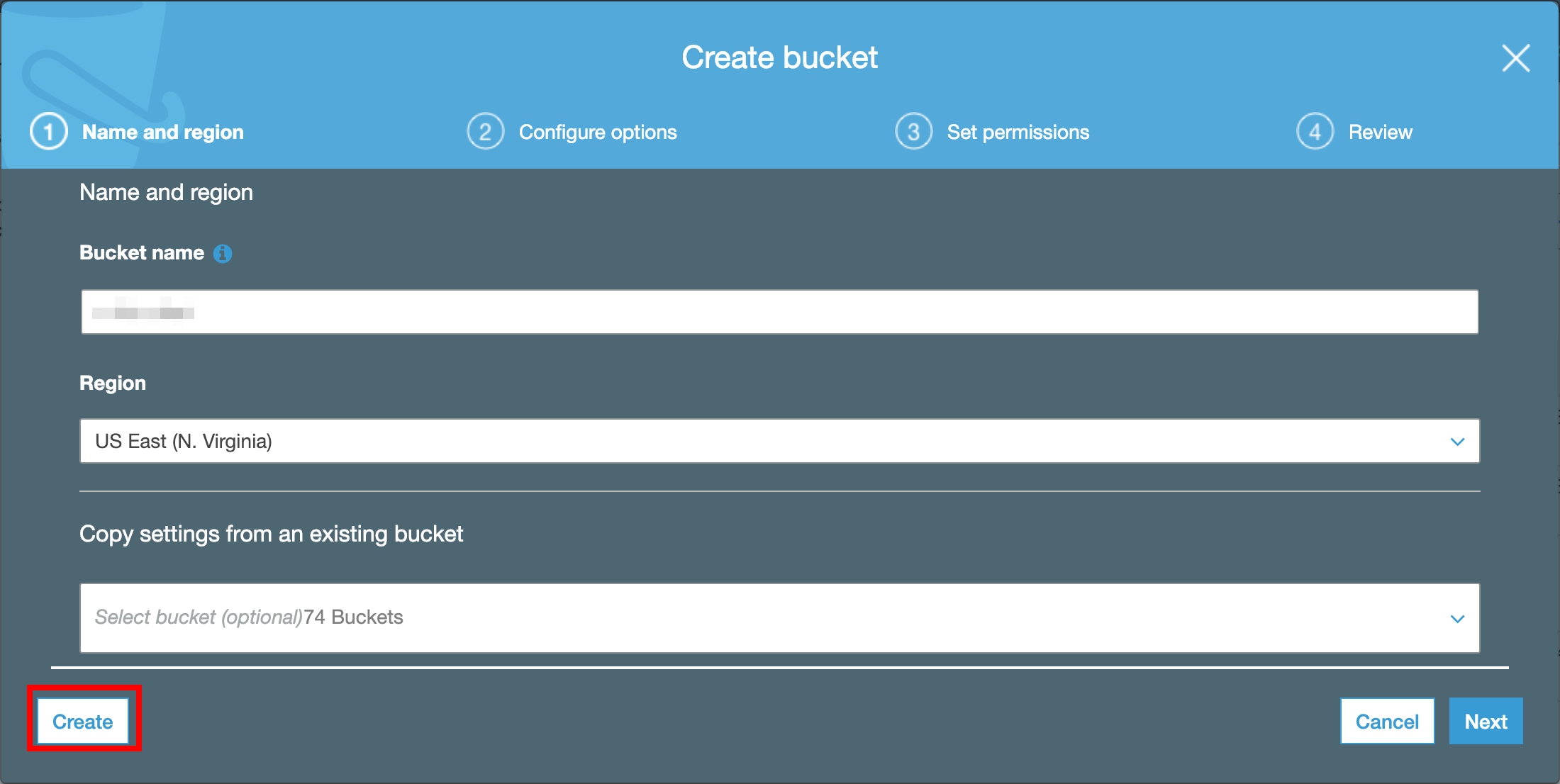
Step 1. 建立 S3 Bucket 儲存輸入資料
在 S3 建立 Bucket 用來儲存要進行分類的圖片。
-
在 Service 選單選擇 S3,點擊 Create Bucket 建立儲存要進行資料標籤化的 Bucket。
-
在 Bucket Name 欄位,輸入獨一無二的名稱。
-
在 Region,選擇 US East (N. Virginia),點選 Create。
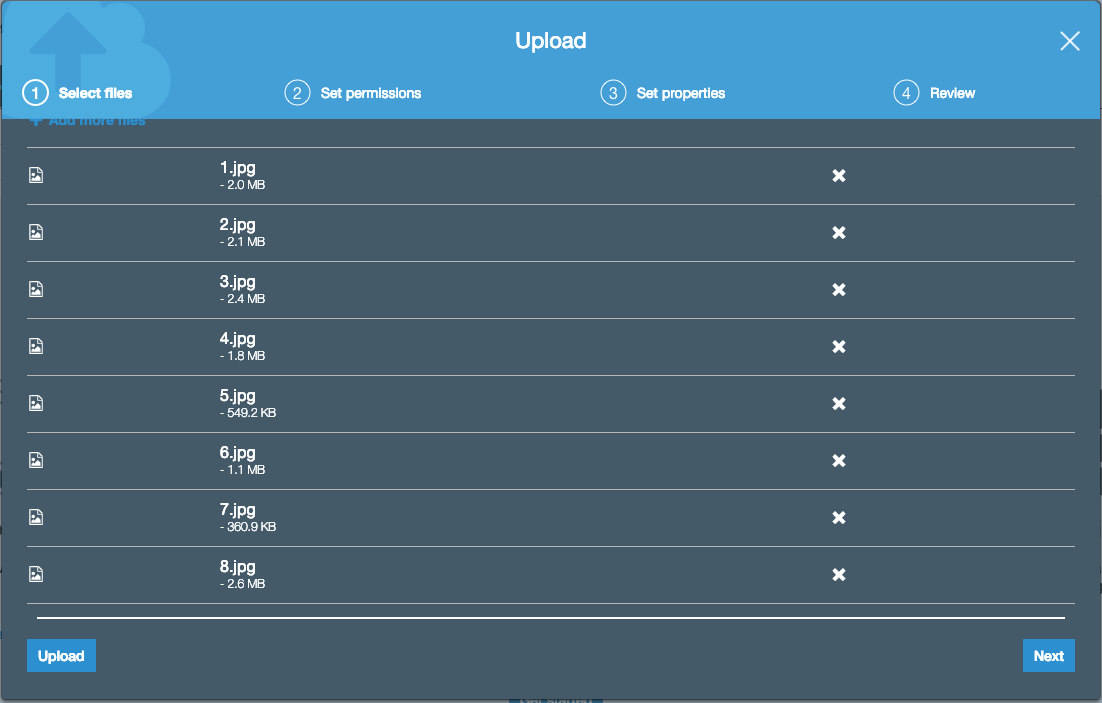
- 選擇剛剛建立的 S3 Bucket,點選 Upload 後將此連結中 labeling images 資料夾中的圖片上傳以作為資料標籤化的資料集。
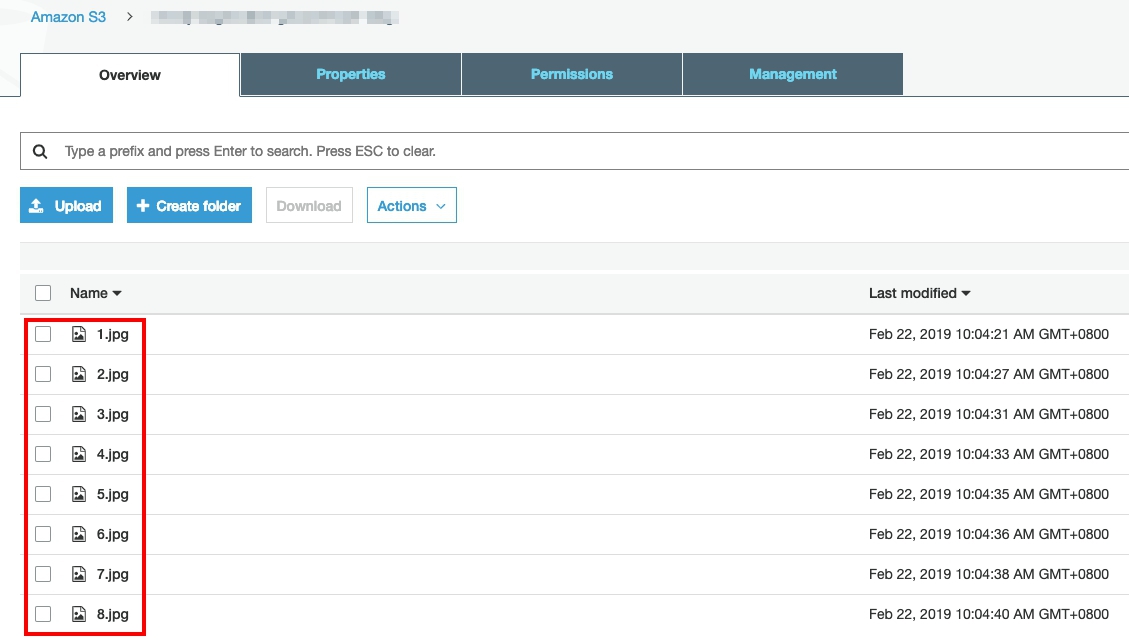
- 上傳後的 Bucket 內容如下。
Step 2. 建立 S3 Bucket 儲存進行標籤後資料
當 SageMaker Ground Truth 結束對資料進行標籤化,會輸出 manifest 的檔案到 S3 Bucket,此檔案會包含被標籤化的資訊。
-
在 Service 選單點選 S3,選擇 Create Bucket 建立儲存要進行資料標籤化的輸入資料。
-
在 Bucket Name 欄位,輸入獨一無二的名稱。
-
在 Region,選擇 US East (N. Virginia),點選 Create。
Step 3. 建立資料標籤化的工作
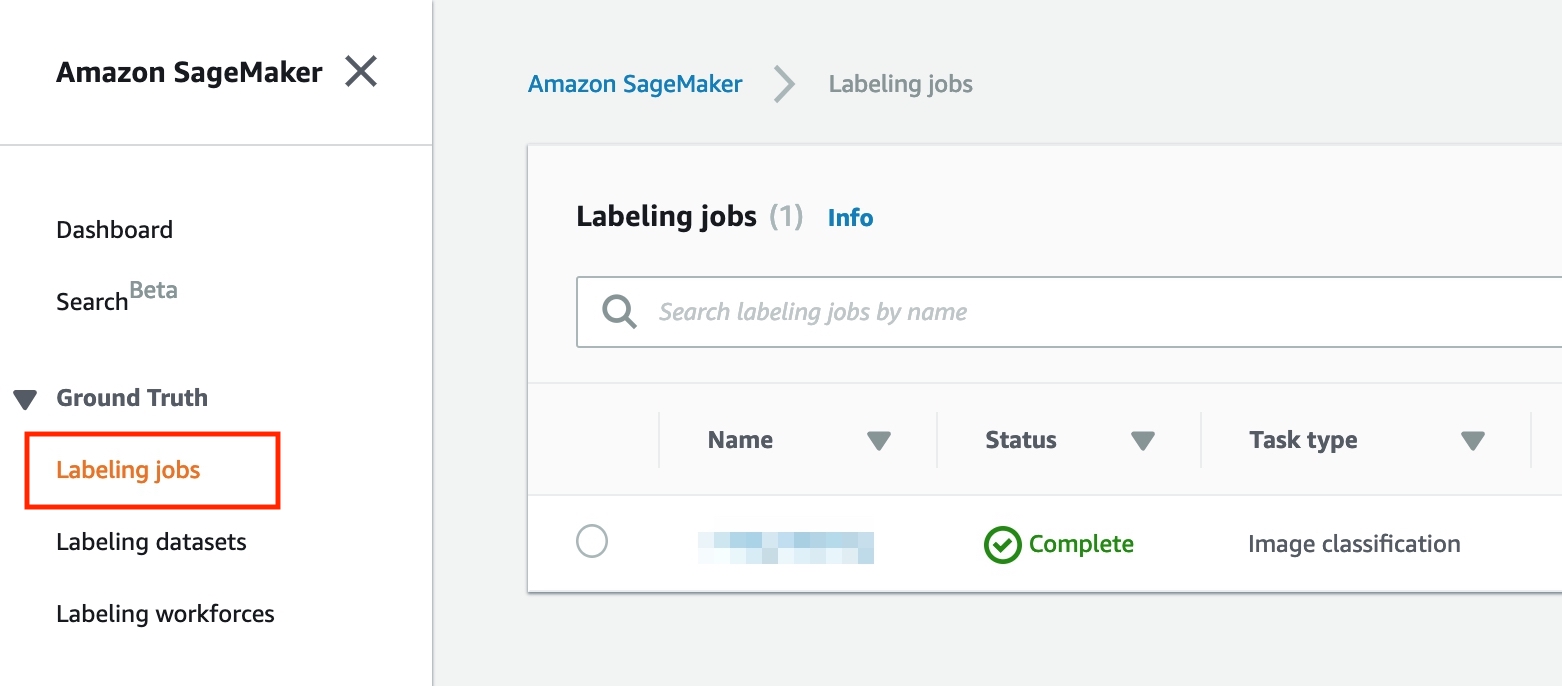
- 在 Service 選單, 選擇 SageMaker 後點選左側面板的 Labeling jobs 準備建立工作。
-
點選 Create labeling job 新增工作以標籤資料。
-
在 Job overview 表單中, 請完成以下設定:
-
Job name :
classify-cat-and-dog० Input dataset location :Bucket 必須建立於 us-east-1 。
-
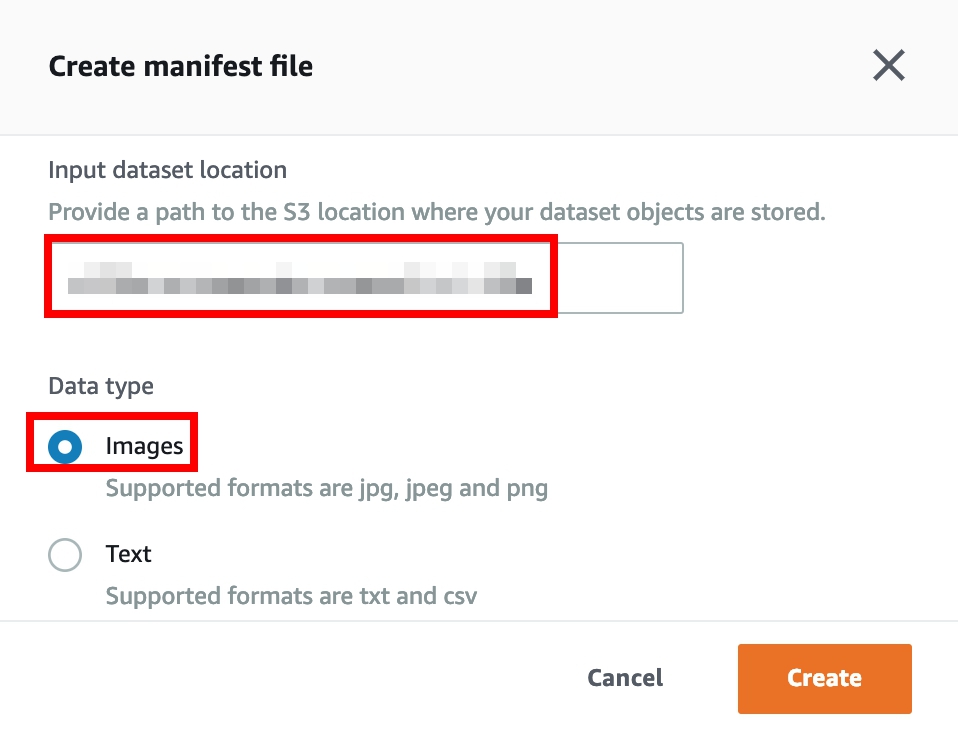
選擇 Create manifest file 建立 manifest 檔案儲存所有需要進行標籤的資料位址。
-
Input dataset location : 輸入儲存輸入資料的 Bucket 名稱
s3://<your input data bucket name>已設定儲存位址。 -
Data type : 選擇 Images 作為資料型態, 然後點選 Create。
-
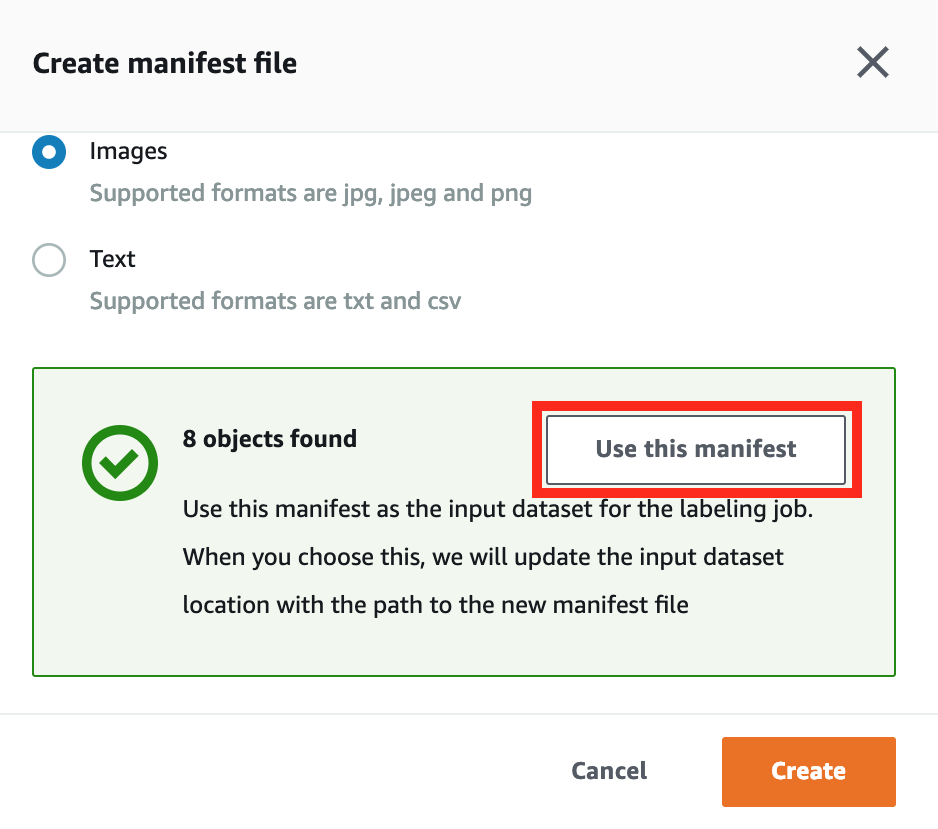
在 Create manifest file 視窗的底部, 將看見成功創建 manifest 檔案的訊息。 之後點選 Use this manifest 使用此檔案作為輸入資料。
-
-
Output dataset location : 輸入儲存輸出資料的 Bucket 名稱
s3://<your output data bucket name>已設定輸出資料位址。Bucket 必須建立於 us-east-1 。
-
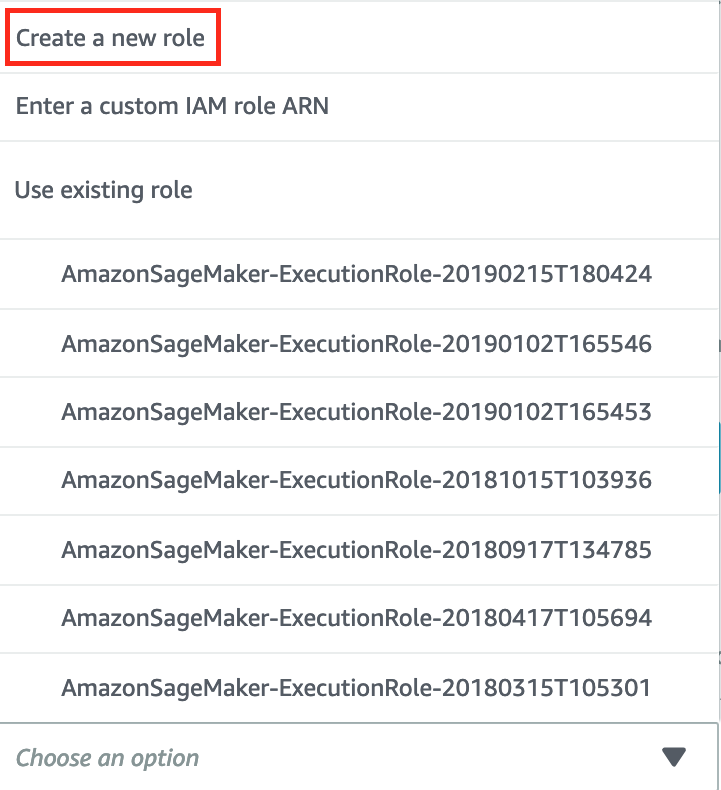
IAM Role : 當使用 SageMaker Ground Truth 進行資料標籤化,需要建立一個 Role 以存取 S3 bucket。
- 選擇 Create a new role 建立新使用者。
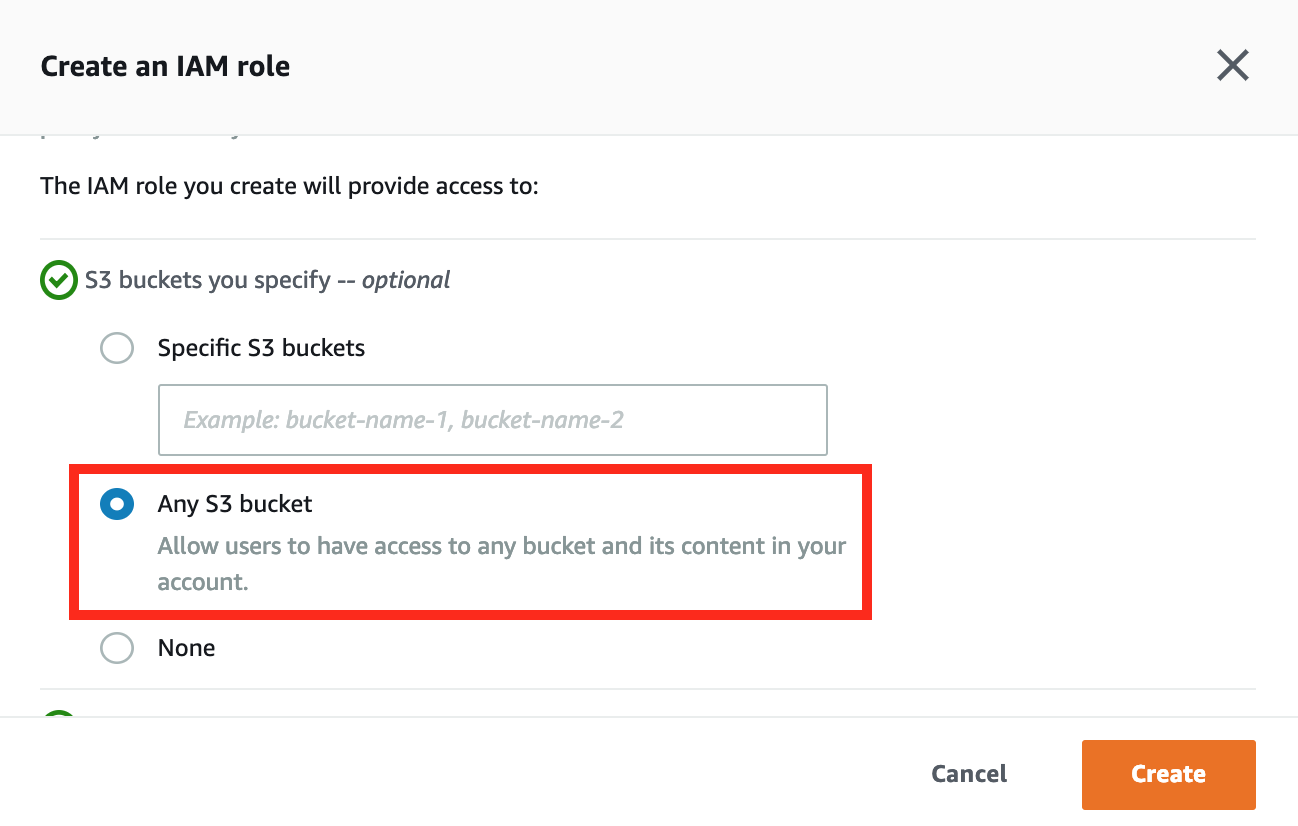
- 在 Create an IAM role 視窗,選擇 Any S3 bucket 讓使用者可以存取所有 S3 Bucket,之後點擊 Create 建立使用者。
-
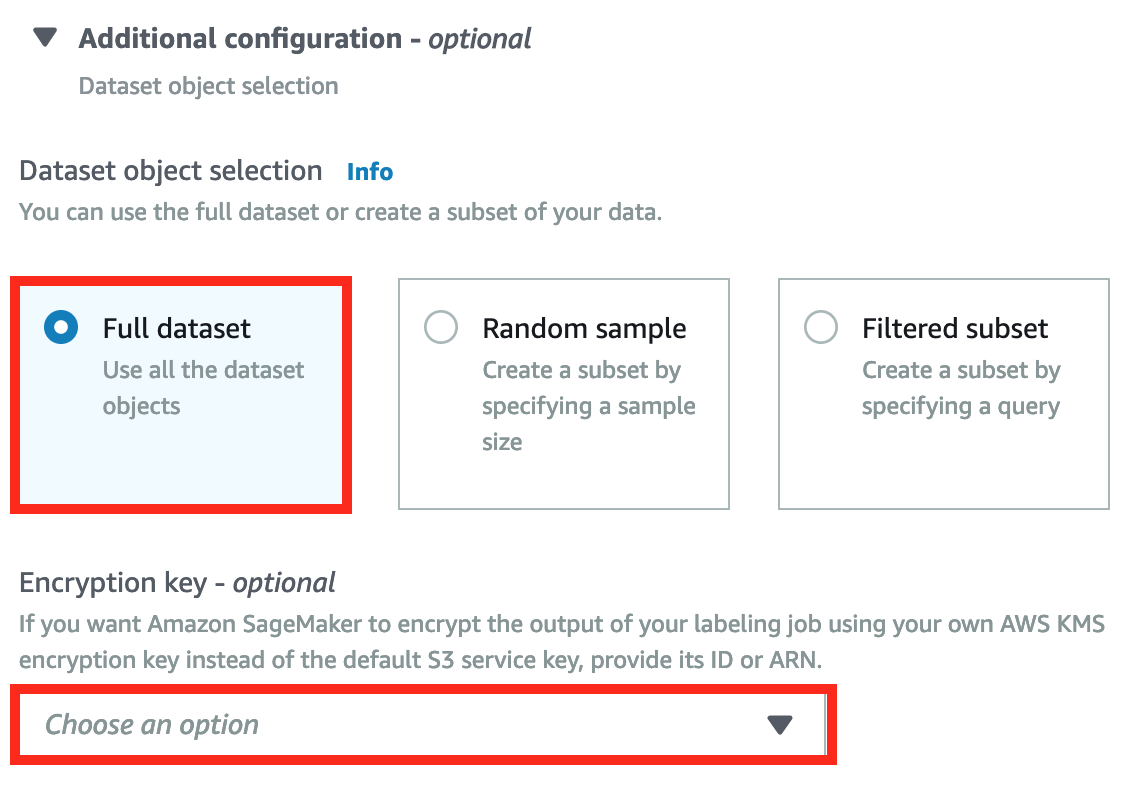
展開 Additional configuration :
-
Datasets object selection : 選擇 Full dataset 使用全部資料集。
其他選擇 : 如果你只想用部分的資料作為輸入資料,選擇 Random sample 並設定 sample size 進行隨機取樣。 或是使用 SQL 語法選取特定資料及作為輸入資料。
-
Encryption key : 使用預設設定 S3 的金鑰加密輸出資料。
-
-
所有設定如下。
-

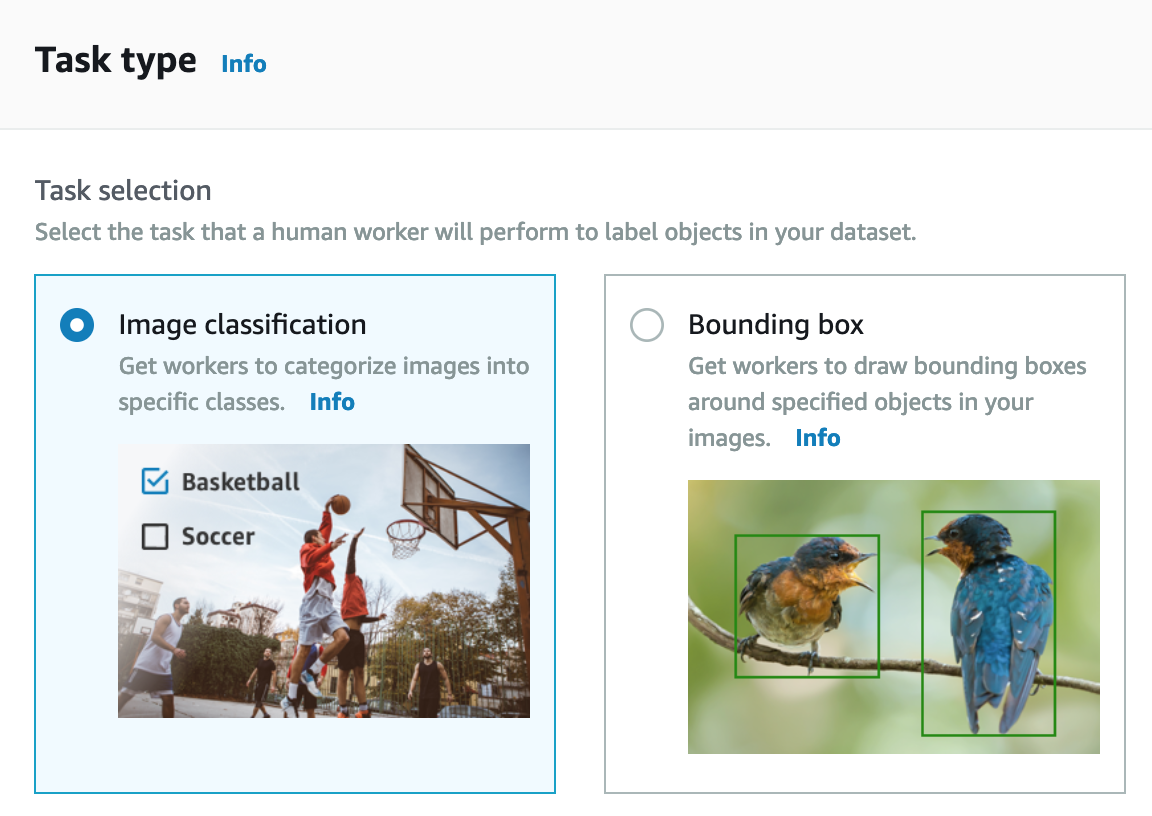
- 在 Task type 部分 : 選擇 Image classification 來分類貓與狗的圖片,點選 Next 進行下一步。
-
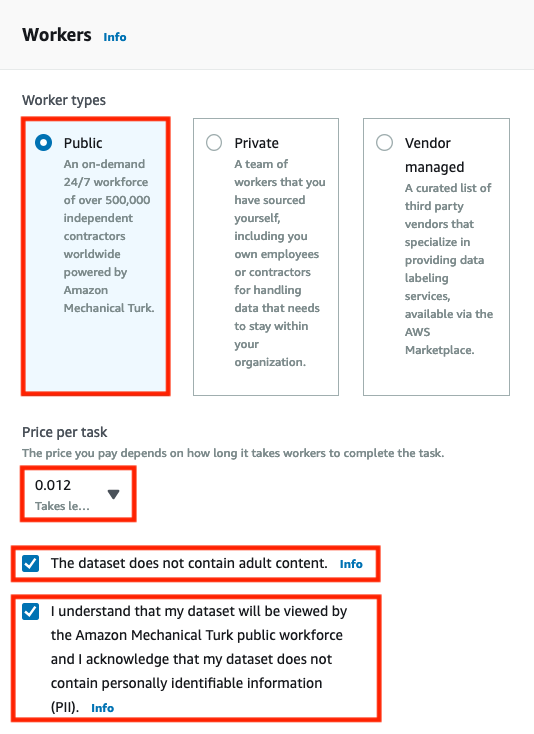
在 Workers 部分 :
-
Worker types : 選擇 Pubilc 使用 Amazon Mechanical Turk 所提供的人力進行資料標籤化。
-
Price per task : 選擇 0.012 的價格支付給標籤人員。
價格請依照每位作業人員在標籤所需的時間選擇。
-
選取 The dataset does not contain adult content 確認資料未包含不雅內容。
-
選取 I understand that my dataset will be viewed by the Amazon Mechanical Turk public workforce and I acknowledge that my dataset does not contain personally identifiable information (PII) 確認資料未包含隱私內容並了解 Amazon Mechanical Turk 公用人力進行查看。
-
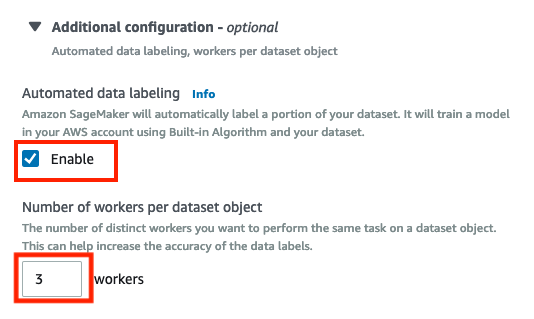
展開 Additional configuration :
-
選擇 Enable 允許 Automated data labeling 使用 AWS 所提供的機器學習模型進行自動標籤資料,它會自動標籤資料以節省成本。
-
輸入 3 在 Number of workers per dataset object 欄位已指定資料集需要幾位人力進行交叉比對,藉由增加人力可以提高準確率。
-
-
-
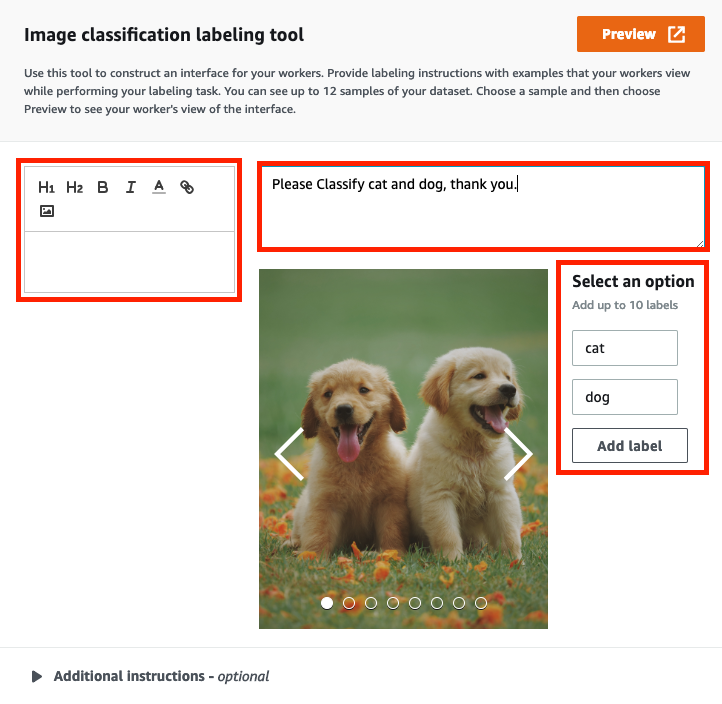
在 Image classification labeling tool 部分設定預覽頁面 :
-
刪除預覽頁面左側文字。
-
輸入以下說明文字描述此工作需求。
Please Classify cat and dog, thank you. -
在 Select an option 部分,新增
cat和dog作為標籤分類。
-
-
點選 Submit 提交此任務給公用人力。
-
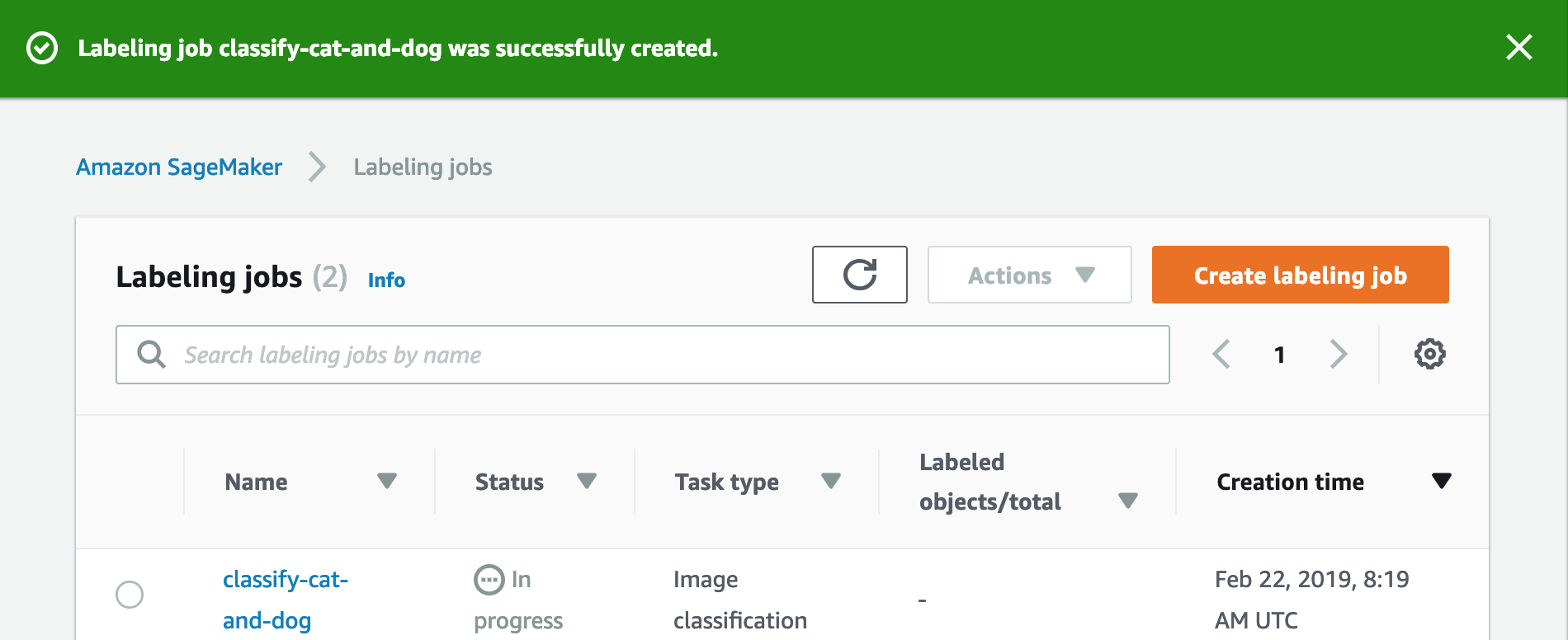
返回 SageMaker 控制台,你將會看資料標籤化的工作正在處理中。
-
請等待工作狀態轉變成 Complete 及代表資料標籤化的工作已完成。
Here may take few time to complete.
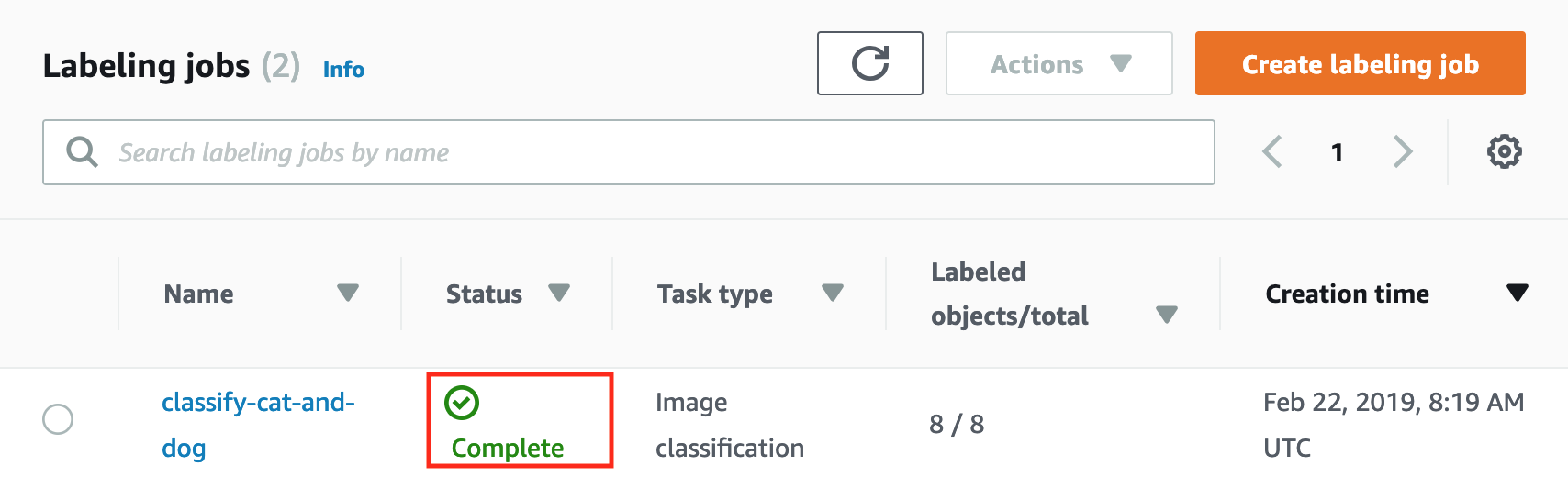
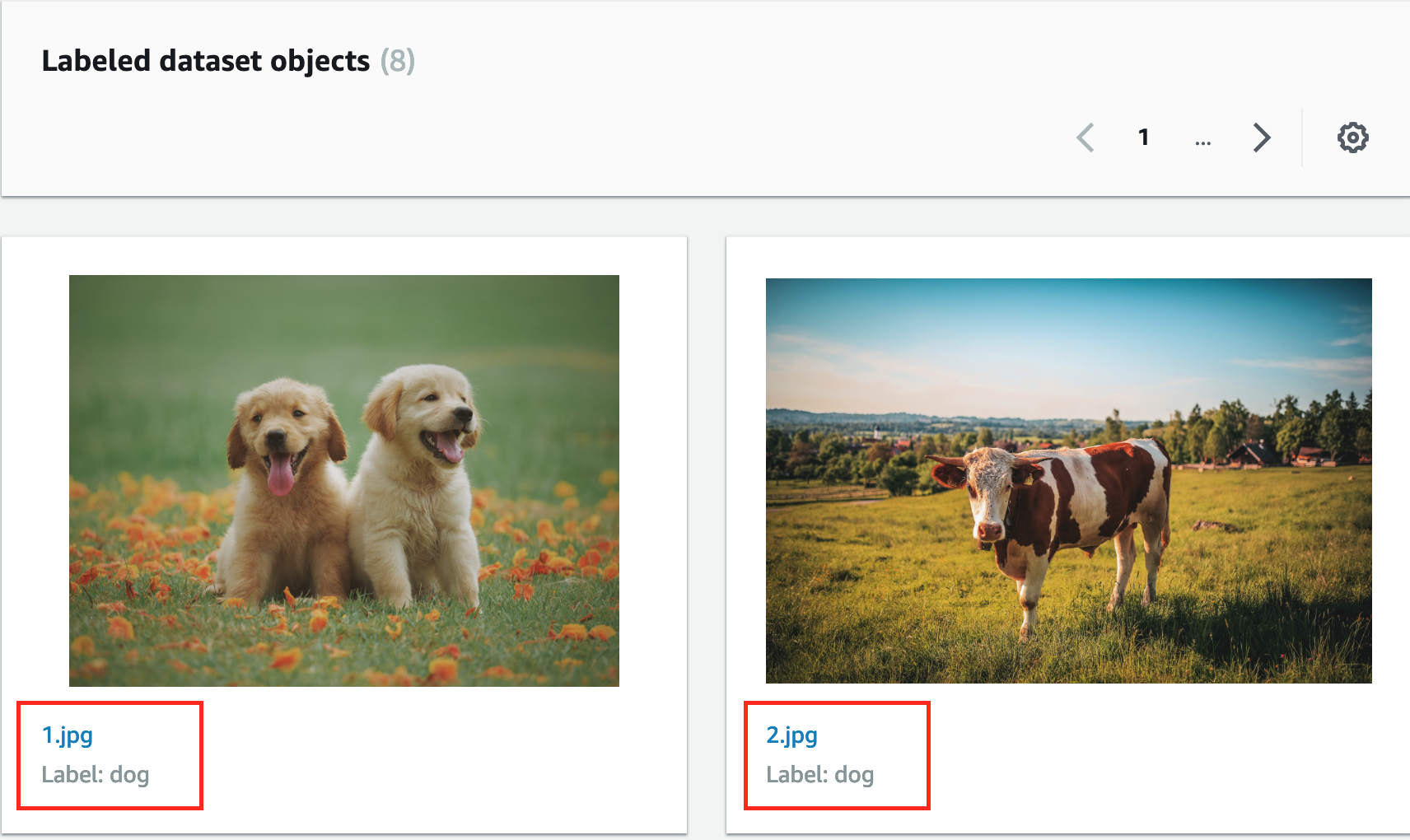
- 選擇命名為 classify-cat-and-dog 的工作並滾動至 Output 部分查看分類後的圖片,您將可看到每張圖片被標籤到的分類。
補充
Amazon SageMaker Groud Truth 提供了三種人力供企業及使用者運用,分別是 – Amazon Mechanical Turk 的公共勞動力 :提供高度可用性且24/7不間斷的服務,對於小型與資料量龐大之企業提供快速擴展的人力。 – 組織內部的私人勞動力:使用公司內部團隊對資料標籤化,並以 Amazon Cognito、社群帳號(Google,Facebook)、OpenID Connect提供商進行身份驗證,因此可解決資料需要保密或具有隱私等問題。 – 第三方供應商所提供的專業勞動力:供應商擁有豐富的經驗,藉由供應商所列出的服務內容,選擇符合你的成本與期望作業的時間。
結論
藉由完成上述教學您將了解到如何利用 Amazon SageMaker Groud Truth 進行資料標籤化,並且選擇最符合您需求的方式建立標籤化流程。Amazon SageMaker Groud Truth 不只在人力的提供上有多種選擇,同時也讓企業可以選擇圖像分類、文本分類、物件檢測等方式建構資料集。
由於網路的便利性,社群媒體所產出的資料量越來越龐大,當企業要進行分析前,必須將資料進行前處理。大量的數據提高了資料標籤化的人力需求與成本,企業都在追求如何加快資料標籤化的速度同時減少成本,透過雲端平台所提供的服務解決此問題,而 Amazon SageMaker Groud Truth 正是其中一個可以解決此問題的服務。
You may also like

【焦點新聞|Microsoft Build 2022】

【焦點新聞】0428-0511 AWS 服務更新
