

使用EMR建立機器學習模型
前言
Amazon EMR 是透過 AWS 雲端虛擬機器集群的分散式運算服務,可用於分析和處理海量數據。EMR 集群利用 Hadoop 的開源框架管理,使用戶可以專注於數據處理和分析,不用花時間煩惱 Hadoop 集群的配置、管理和優化,也無需擔心所需要的計算能力。
ETL (Extract-Transform-Load) 是將數據從來源端經過extract、transform以及load至目的端的過程,主要目的通常是將即時數據或非結構化數據經過一系列的數據前處理過程,轉化為方便企業查詢或是訓練模型的形式,並儲存在指定的數據庫。
在ETL過程中將數據進行合併和計算新的特徵,使得數據的維度提升等等一系列改進原始數據的過程,又稱為數據豐富。這個過程可以幫助企業依據自身的營運狀況,將有限的數據轉化成更合適的決策資產。
EMR在ETL以及機器學習的優勢在於可以利用Hadoop分散式計算技術,處理容量大的數據或是大數據或複雜演算法所帶來的大量繁複計算。透過MapReduce,使用者可以在上千台機器上平行處理巨量的數據,大大減少數據處理及modeling的時間。
本次實驗情景
在本次實驗裡我們採用葡萄牙銀行的直銷數據,這個數據集一共有兩份數據,分別為使用者的基本數據,例如年齡、工作、婚姻狀況以及教育程度等等, 以及銀行行銷該客戶的狀況,例如最後一次聯繫的時間以及聯繫方式等等。
我們首先利用EMR搭配hive及spark dataframe將這兩種數據框架合併、計算所需要的欄位並替代掉遺漏值,讓數據變得乾淨並儲存在S3儲存桶以利後續的機器學習流程。
下一步,我們利用python的pyspark套件在EMR建立的機器學習模型,用數據豐富後的數據特徵判斷客戶是否會購買銀行的定期存款,最後我們比較數據豐富前後的數據在同一個模型的差異,凸顯數據豐富的重要性。這個modeling的過程我們會在Zeppelin notebook完成。
架構
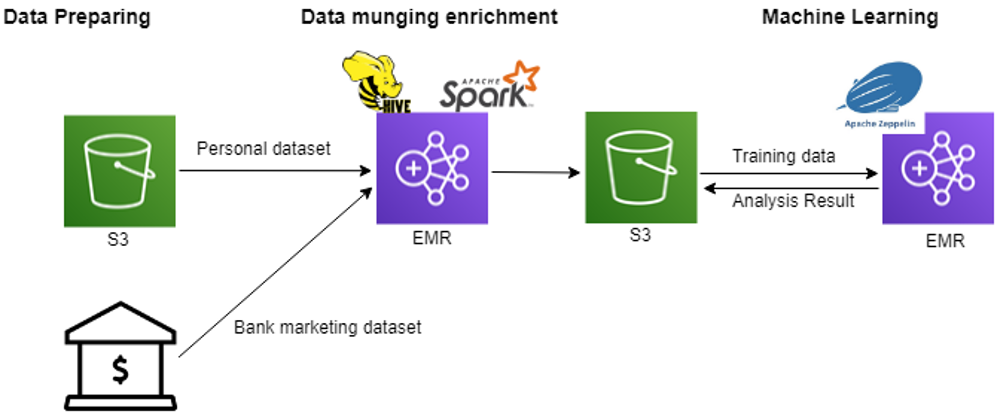
事前準備
-
建立一個S3桶用來儲存ETL的數據,您可以到下列的網址下載 BankMkt2.csv 數據並在S3儲存桶建立一個新的folder,放入此筆數據。
-
下載此 Lab Zeppelin Note json 檔案。
步驟
一、 配置安全組
在建立EMR群集之前,我們必須先配置安全組。
-
在 EC2 服務中創建 安全組,依循下述資訊配置安全組:
- Security Group Name:
EMR Security Group - Description:
Security for the EMR - VPC:
default VPC
- Security Group Name:
-
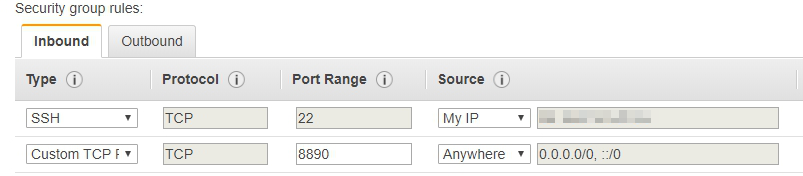
設定安全組規則, 選擇 入站 並點選 添加規則。 使用下圖的值,設定以下規則:
- 可以讓管理員 SSH 訪問 Master EC2。
- 可以開啟Zeppelin notebook的 8890 Port。
二、 創建 EMR 集群
在這部分我們將在AWS console上創建EMR集群,並部署所需要的軟體版本以及安全設定。
-
在 AWS 管理控制台 中,開啟 服務 並點選 EMR 服務。
-
點選 創建集群 並點選 轉到高級選項。
-
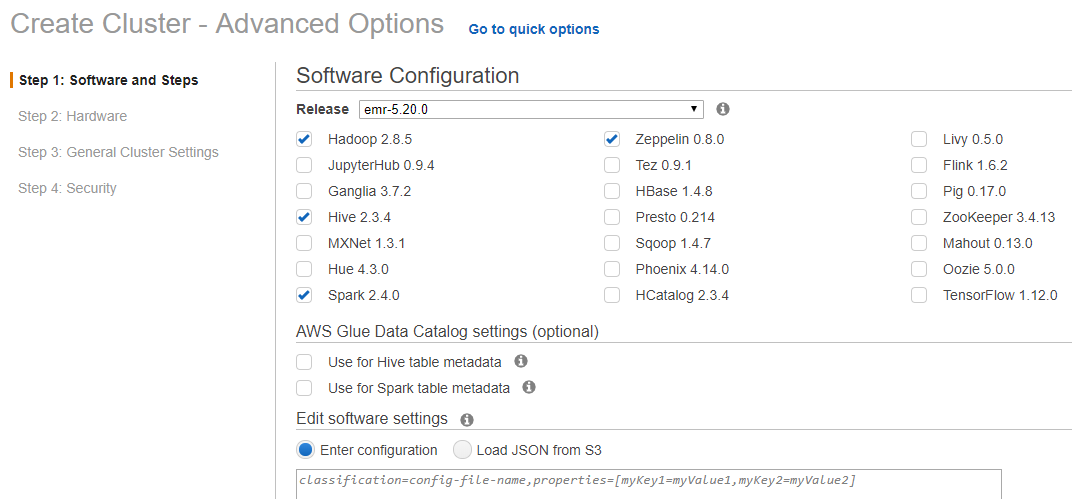
在步驟1: 軟件與步驟: 從發行版選單選擇 EMR 5.20.0 並勾選下圖所示之方框。
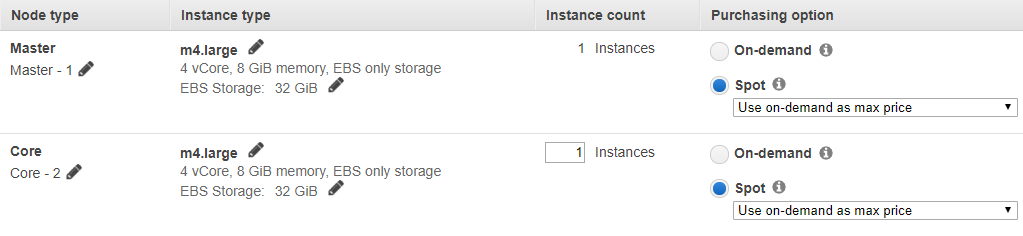
- 選擇 m4.large 實例並點擊方框 Spot。
選擇 Spot Instance 可以讓您的 EMR 成本大幅降低,建議設定在僅用於暫時參與運算的機器,由於相容性問題,在這裡建議也選擇 m4.large 的 Instance。
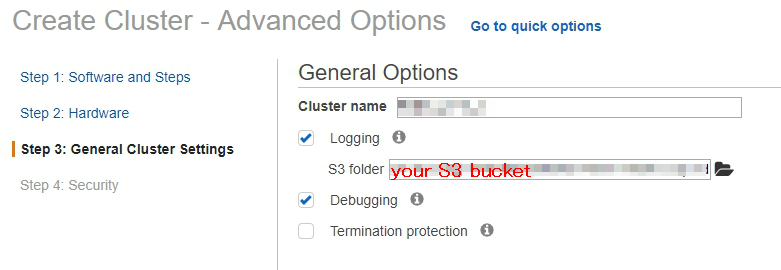
- 在一般選項的頁面,集群名稱輸入 My cluster,並選擇一個您想儲存資訊的S3儲存桶。
三、 開始ETL流程
此步驟主要是利用 hive 和 spark 將數據進行合併及清理,在這一步開始之前,我們利用 SSH 連線至 EMR 的 master node 並連線至zeppelin notebook 藉由 8890 port。
a. SSH 連線至 EMR master node 後,輸入以下指令創建新的hdfs dictionary 並給予讀取權限:
hadoop fs -mkdir /user/zeppe-user
hadoop fs -chmod 777 /user/zeppe-user
b. 接著我們從指定的數據連結中獲取數據:
mkdir /tmp/banktmp1
wget -O /tmp/banktmp1/BankMkt1.csv https://s3.amazonaws.com/ecv-training-jj-v/emretl/bankMKT/BankMkt1.csv
c. 建立一個新的 dictionary ,並把下載的數據distribute into HDFS:
HDF (Hierarchical Data Format) 是 Hadoop 的分布式儲存技術,可以將數據儲存在不同的node上,這個技術設計可以很好的處理大數據的mapreduce計算。
hadoop fs -mkdir /user/zeppe-user/bankmkthdf/
hadoop fs -put /tmp/banktmp1/BankMkt1.csv /user/zeppe-user/bankmkthdf
d. 開啟 Hive 並建立表格 此步驟的目的是替數據建立Hive表,在後面的步驟裡我們將使用這個數據做簡單的 ETL。
Hive 是基於 Hadoop 的一個數據倉庫工具,可以將結構化的數據檔案映射為一張數據庫表,並提供完整的 SQL 查詢功能,可以將 SQL 語句轉換為 MapReduce 任務進行運行,可以用來進行數據提取轉化載入(ETL)。
-
在EMR輸入以下指令:
-
開啟 Hive
hive -
建立 bankmkt1 表的 metadata
CREATE EXTERNAL TABLE IF NOT EXISTS bankmktable1 ( id string, age int, job string, marital string, education string, default string, housing string ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = '\,', "quoteChar" = '\"' ) STORED AS TEXTFILE; -
將數據輸入這張表
LOAD DATA INPATH '/user/zeppe-user/bankmkthdf' INTO TABLE bankmktable1; -
查看前面兩列,確定數據是完整的
SELECT * FROM bankmktable1 DESC LIMIT 2; -
建立 bankmkt2 表的 metadata,並從 S3 輸入數據
CREATE EXTERNAL TABLE IF NOT EXISTS bankmktweb2 ( id string, loan string, contact string, month string, dayofweek string, duration int, campaign int, pdays int, previous int, poutcome string, empvarrate int, conspriceidx double, consconfidx double, euribor3m double, nremployed double, label int ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' LOCATION 's3://<your s3 data path>/' TBLPROPERTIES("skip.header.line.count"="1"); -
查看前面兩列,確定數據是完整的
SELECT * FROM bankmktweb2 DESC LIMIT 2; -
離開 hive
exit;
-
-
開啟 Zeppelin Notebook
在這一步,我們將在Zeppelin notebook中利用spark對數據進行合併及清理。
-
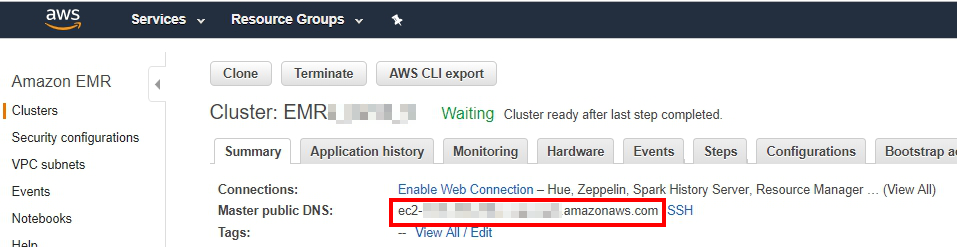
到您剛剛建立的EMR Cluster中複製Master node的public DNS,並在網址後方加上
:8890。8990是Zeppelin的default port。
-
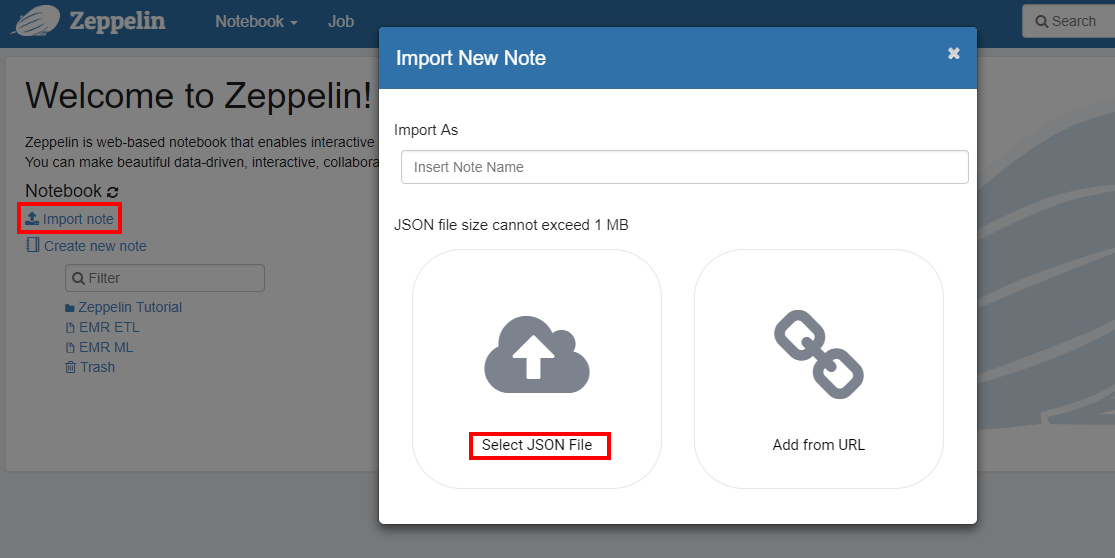
連上Zeppelin後,點選Import note建立兩個新的note, 點選Select JSON File。
-
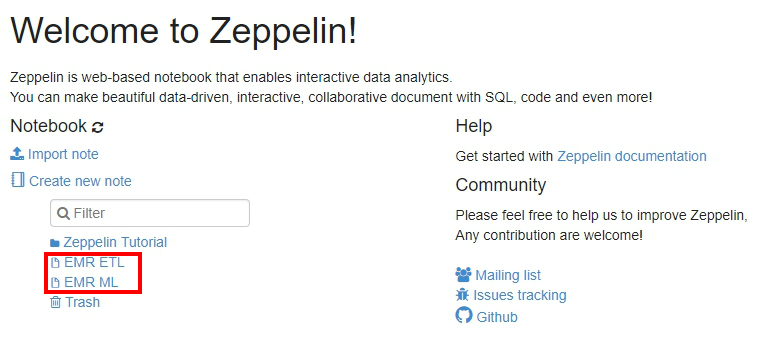
建立完成後,我們可以看到兩個分別為ETL和ML的新note。
-
首先我們打開EMR ETL的notebook,按Ctrl+Enter執行第一格的命令,把兩筆數據進行合併。

-
當然也可以看一下數據的形式,在這裡我們發現了一些遺漏值。

-
我們想要取代掉這些值。可以利用以下指令取代:
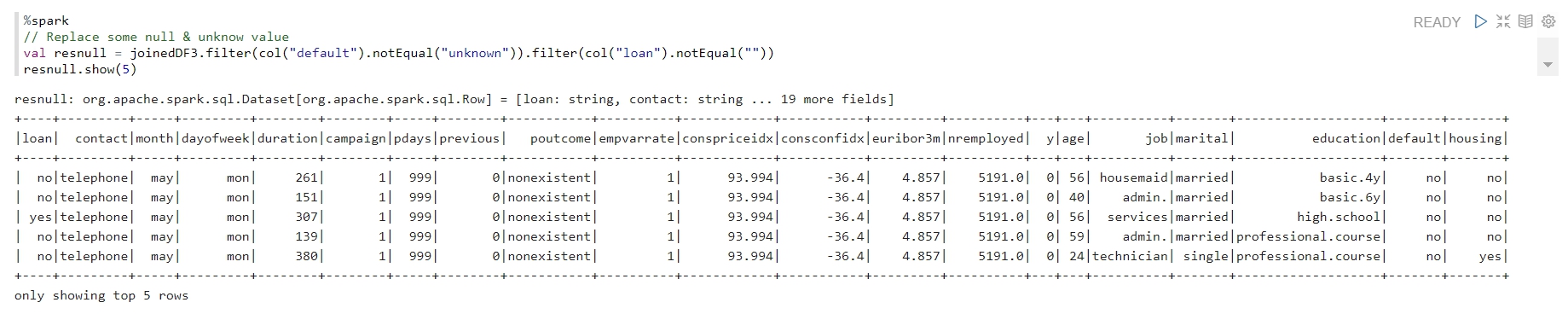
-
接著我們將這個數據儲存到S3儲存桶。
請建立一個新的folder放入此數據並記住這個路徑,我們稍後會使用它。

-
在 Zeppelin 使用 spark sql 畫圖。
Zeppelin 提供了互動的視覺化界面工具,可以利用 spark sql 語法畫一些圖,以提供資料分析的洞見。
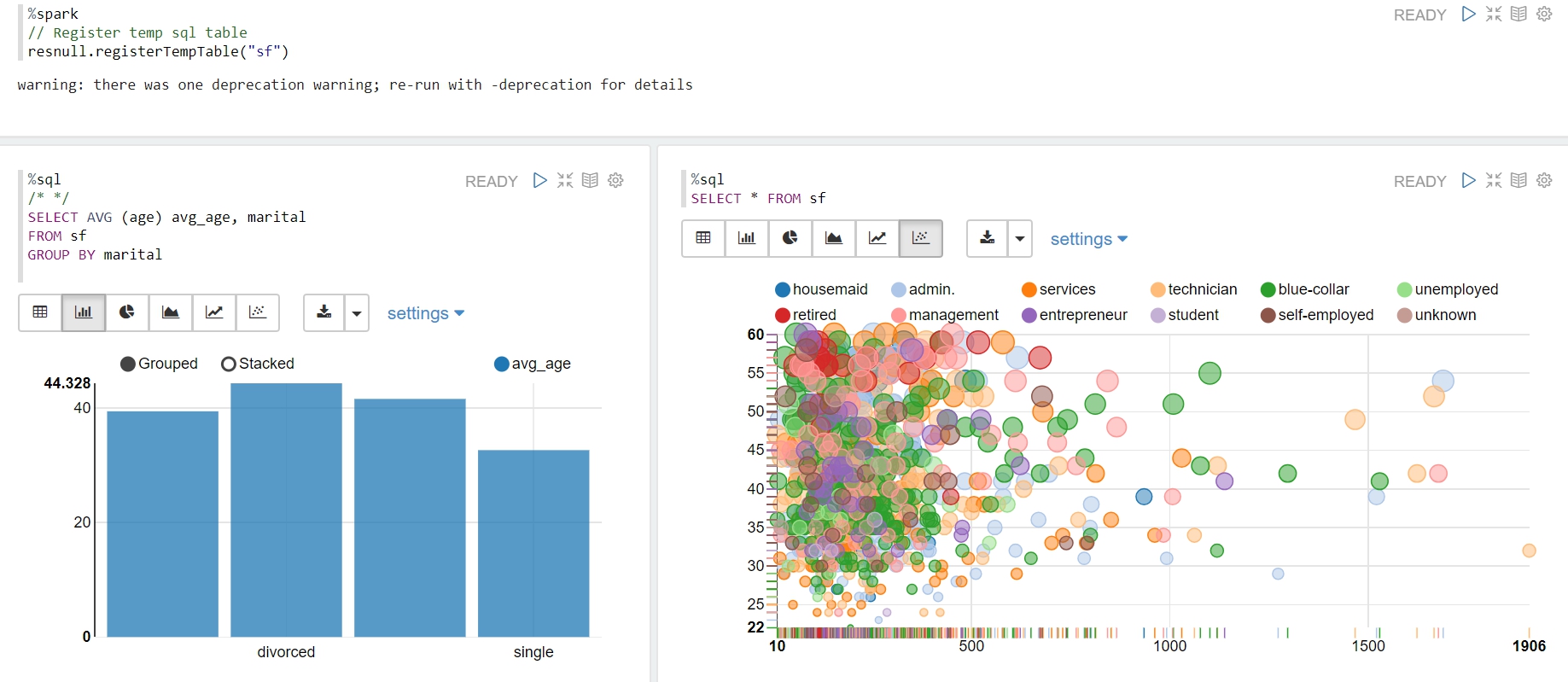
四、 建立EMR的機器學習流程
經過ETL流程後,我們再從S3儲存桶讀取這筆整理完的數據並建立機器流程。我們利用pyspark套件將spark與python結合,進行機器學習分析。本次實驗建立機器學習pipeline用來將類別變數encoding成dummy variable。
pyspark可以調用HDF分布式儲存的數據,結合spark dataframe可以更快速地訓練機器學習模型。
-
讀取資料
讓我們利用以下代碼從自己的S3儲存桶存取數據:
在這裡必須修改 csv 數據的 S3 路徑。
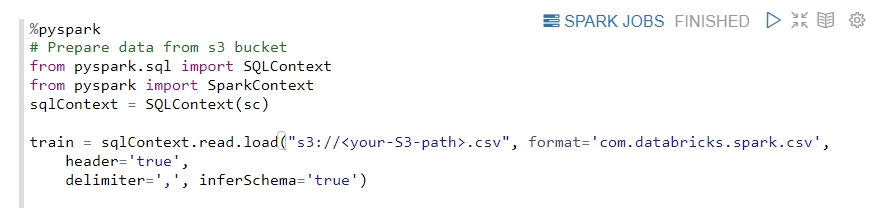
-
區分數據成Training & Testing dataset > 在這裡我們設定隨機種子,保證每一次隨機抽取的數據都是一樣的。

-
建立機器學習流程參數
機器學習流程把機器學習的必經過程串接起來,建立機器學習pipeline讓我們只需要管理來源數據,不必重複轉換數據以及定義機器學習模型參數。
-
首先,我們用以下的參數協助我們建立機器學習流程,這些參數分別代表了:
dt: 決策樹模型。indexers: 此參數幫助我們轉換字串成數值。encoders: 轉換多類別數值成1與0的類型。assembler: 將所有 Feature 整合到一個向量中。
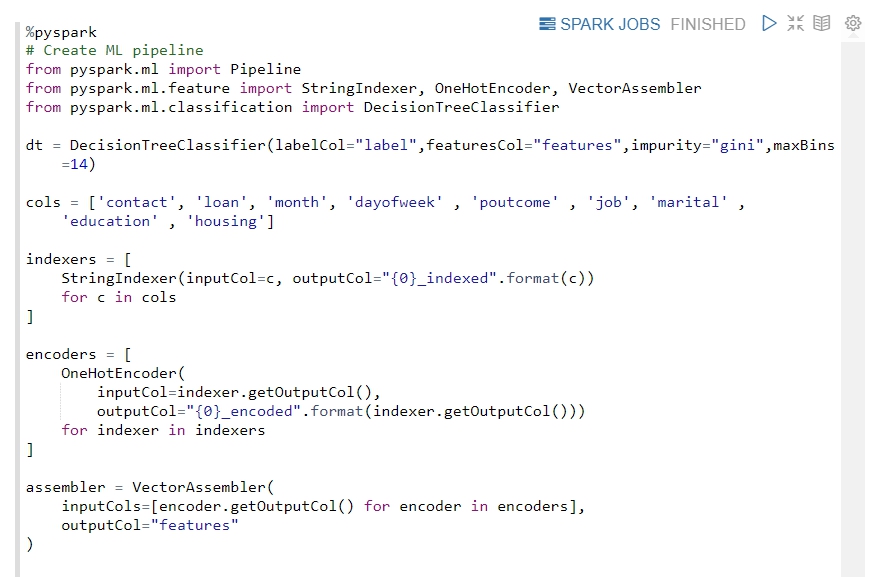
-
建立機器學習流程參數
機器學習流程把機器學習的必經過程串接起來,建立機器學習pipeline讓我們只需要管理來源數據,不必重複轉換數據以及定義機器學習模型參數。

-
訓練決策樹模型
現在我們可以用剛剛建立的 ML pipeline 訓練機器學習模型,有了機器學習 Pipeline 我們只需要改變測試數據,大大簡化了機器學習設置參數的麻煩。 在模型訓練後我們想比較一下模型的表現,在此使用的模型評估函數是 AUC,AUC 是一介於 0 和 1 之間的值,越接近 1 意味著預測績效越高,表示模型的表現越好。
更詳細的 AUC 原理及介紹可以參考: Classification: ROC Curve and AUC 。
下圖是訓練後的評價結果,可以看出 AUC 值僅有0.365,顯示分類效果並不是很好,這個模型似乎太過於簡單,我們想要提升這個結果。
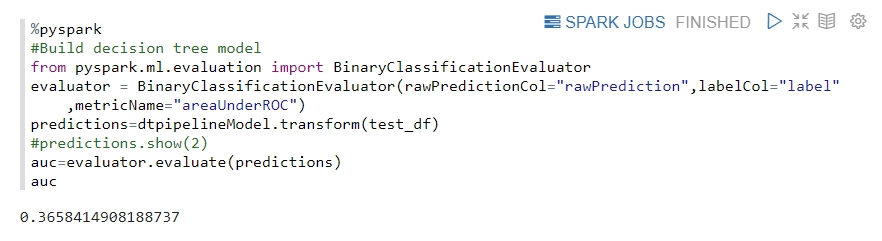
-
訓練隨機森林模型
為了將此數據訓練得更好,在這裡我們用了隨機森林模型,隨機森林模型是由多個決策樹所組成,相較於決策樹模型考慮的資訊更多,在這裡我們想要和決策樹模型做一個比較。
有關隨機森林模型與決策樹模型的差異可以參考: Decision Trees and Random Forests。

從上圖可見隨機森林模型的表現較決策樹好,AUC 值為 0.772,相較之下更應該採納此模型。如果實驗結果可接受,後續可以自行建立 API 或 endpoint 將這個模型作為預測基準,應用到您的商業決策上。
結論
您現在已經學習如何利用EMR做簡單的ETL流程,並在裡面建立機器學習pipeline,半自動化建立機器學習模型。 針對此筆數據,您也可以考慮更多更複雜的機器學習模型,例如 GBM、XGboost、Stacked Ensembles、Generalized Low Rank Models (GLRM) 等等,測試在相同條件下不同演算法的表現差異。而評價指標也可考慮更多例如Precision、Recall等等,有關更多評價指標可以參考此篇關於 Validation Index 的介紹。
在本次實驗結束後您可以使用自己的大數據集訓練更複雜的機器學習模型,部屬更多 EMR 集群並與單台主機相比,相信可以看出在運算效能及結果上會有顯著的不同,體會分散式運算所帶來的優勢。
You may also like

【焦點新聞|Microsoft Build 2022】

【焦點新聞】0428-0511 AWS 服務更新
