

Labeling Data with SageMaker Ground Truth
Overview
Today, Machine Learning is mainly used in supervised learning. Supervised learning using large amounts of data to enable machine learning or build a model, and use this mode to classify or predict new data.
It’s like people saw a rabbit, at first when no one told us it was a rabbit, we might not understand what it was. But when someone showed us a thousand times the rabbit and told us he was a rabbit. The next time we see it, we know it’s a rabbit.
A common problem for banks is credit card transaction data, which may contain normal transactions or fraudulent behavior in a large amount of transaction data. Machine learning real-time forecasting can prevent losses from fraudulent behavior. That’s why we understand the keys to impact the accuracy of supervised learning is training datasets, and it’s important to ensure the accuracy of training datasets.
In many companies, it takes a lot of time to label special training sets, such as the identification of medical images. Tagging thousands of images or text takes a lot of time and labor.
To resolve high labor costs and insufficient staff, Amazon has introduced Amazon SageMaker Groud Truth to accelerate the construction of highly accurate data sets, and reduce the labor costs of labeling, can reduce costs by up to 70%, and these savings are achieved through the use of automatic labeling for data.
Scenario
With this Lab, you will use Amazon SageMaker Ground Truth to quickly labeling datasets, classify and add the label of cats and dogs images, and this Lab will use public labor with automatic labeling technology. At last, store the results of classification to S3 Bucket.
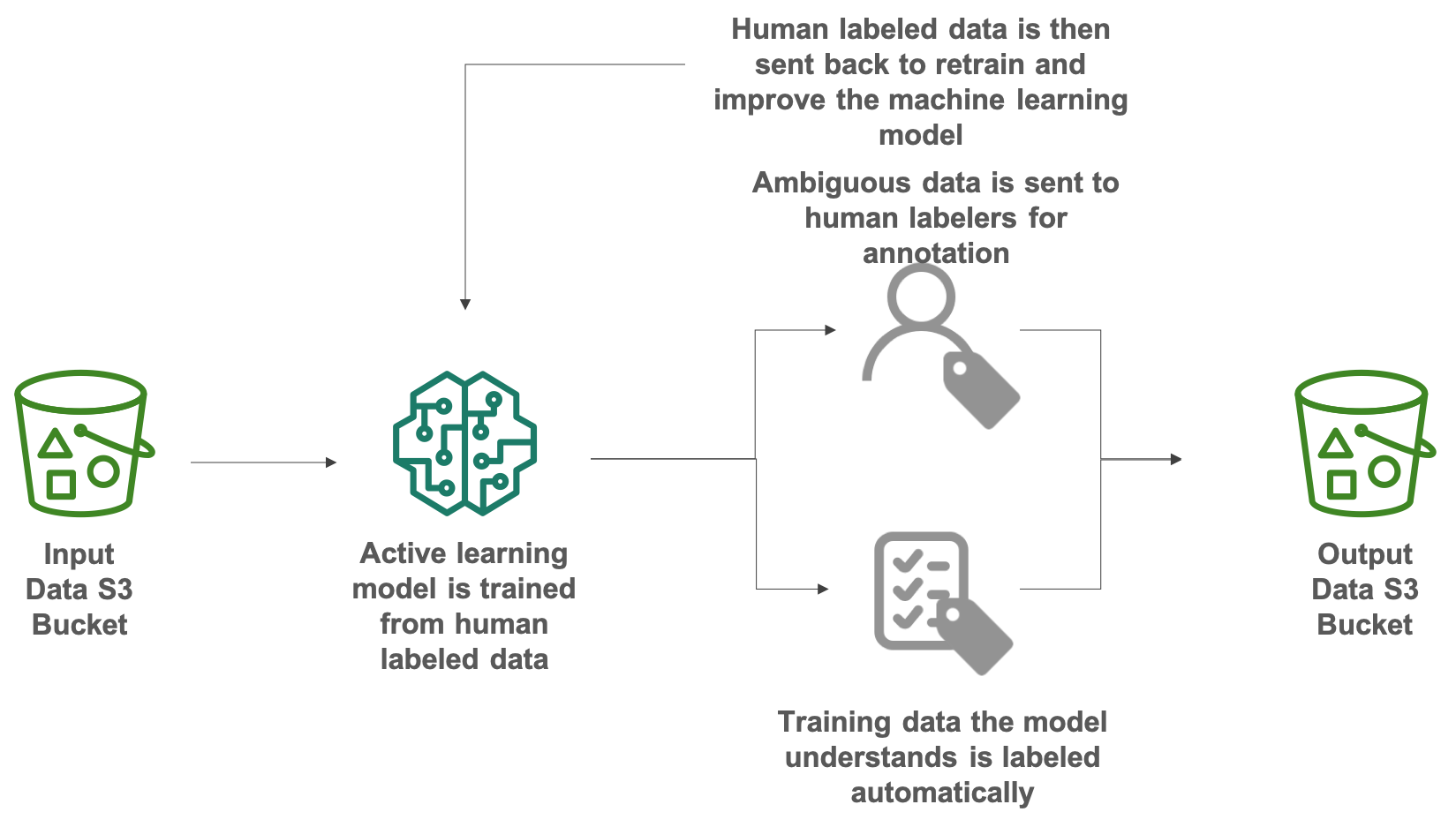
Step by Step
Step 1. Create the first Bucket to store input data
Here we create an S3 bucket to store the input data for data labeling.
-
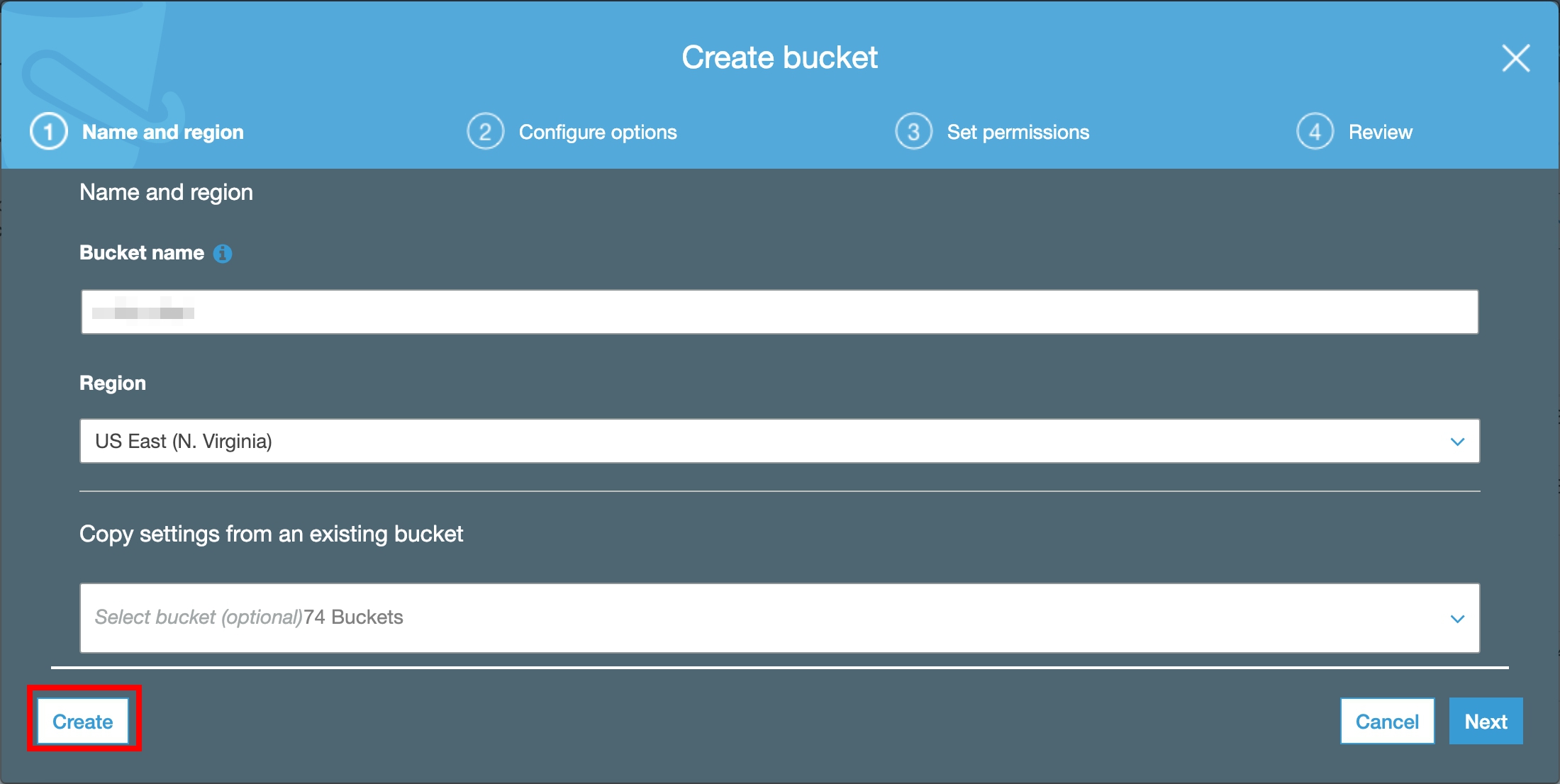
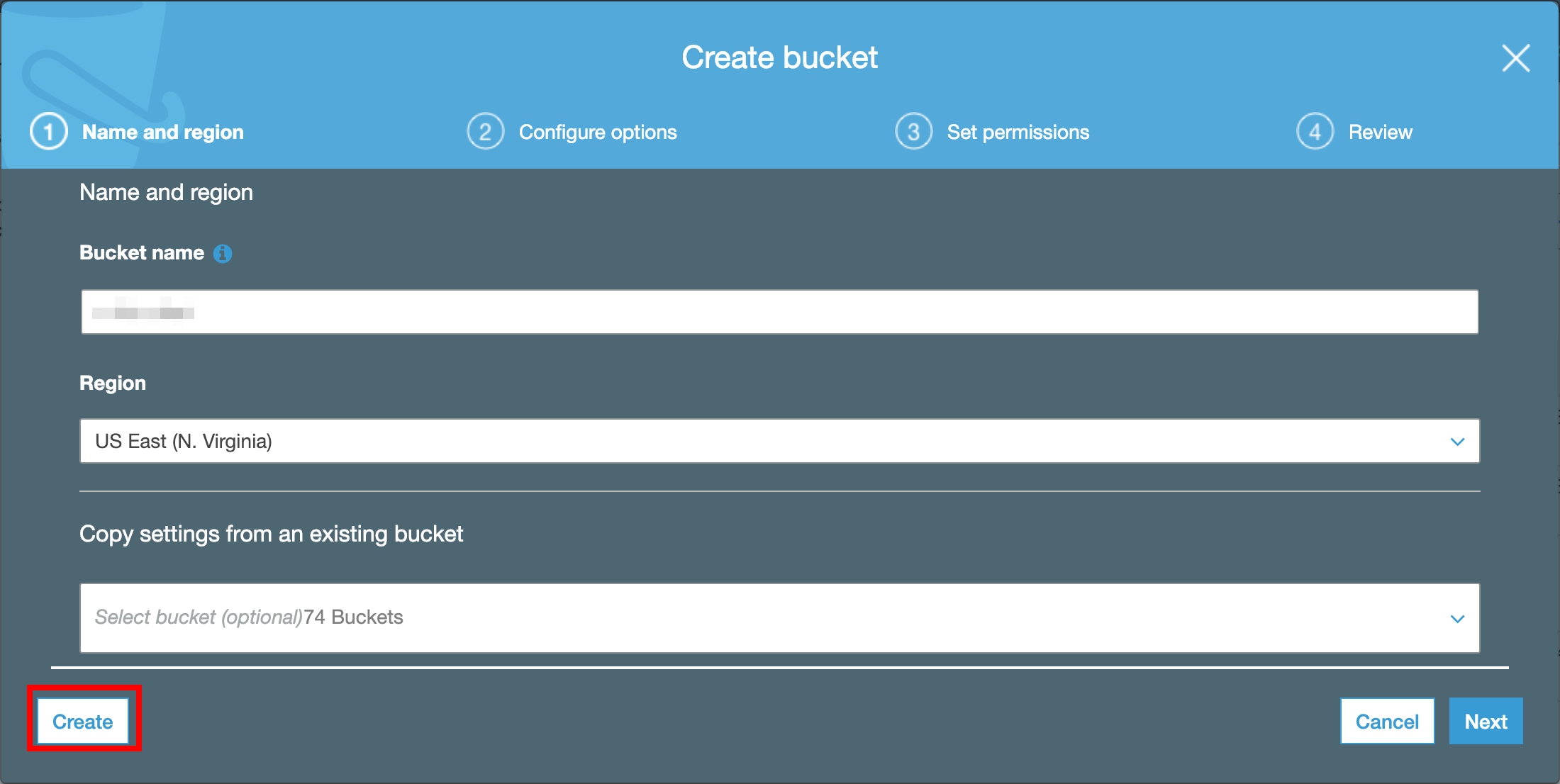
On the Service menu, click S3, Click **Create Bucket **.
-
For Bucket Name, type Unique Name.
-
For Region, choose US East (N. Virginia), Click Create.
- Select the bucket which you created before, Click Upload then download this repository and drag the images in label images folder to S3 bucket to be the input data, and click Upload.
- You will see images in your bucket.
Step 2. Create the second Bucket to store output data
When SageMaker Ground Truth finish the labeling job, it will export a manifest file to S3 bucket, so here create another bucket for output data.
-
On the Service menu, click S3, Click **Create Bucket **.
-
For Bucket Name, type Unique Name.
-
For Region, choose US East (N. Virginia), Click Create.
Step 3. Create a Labeling Job
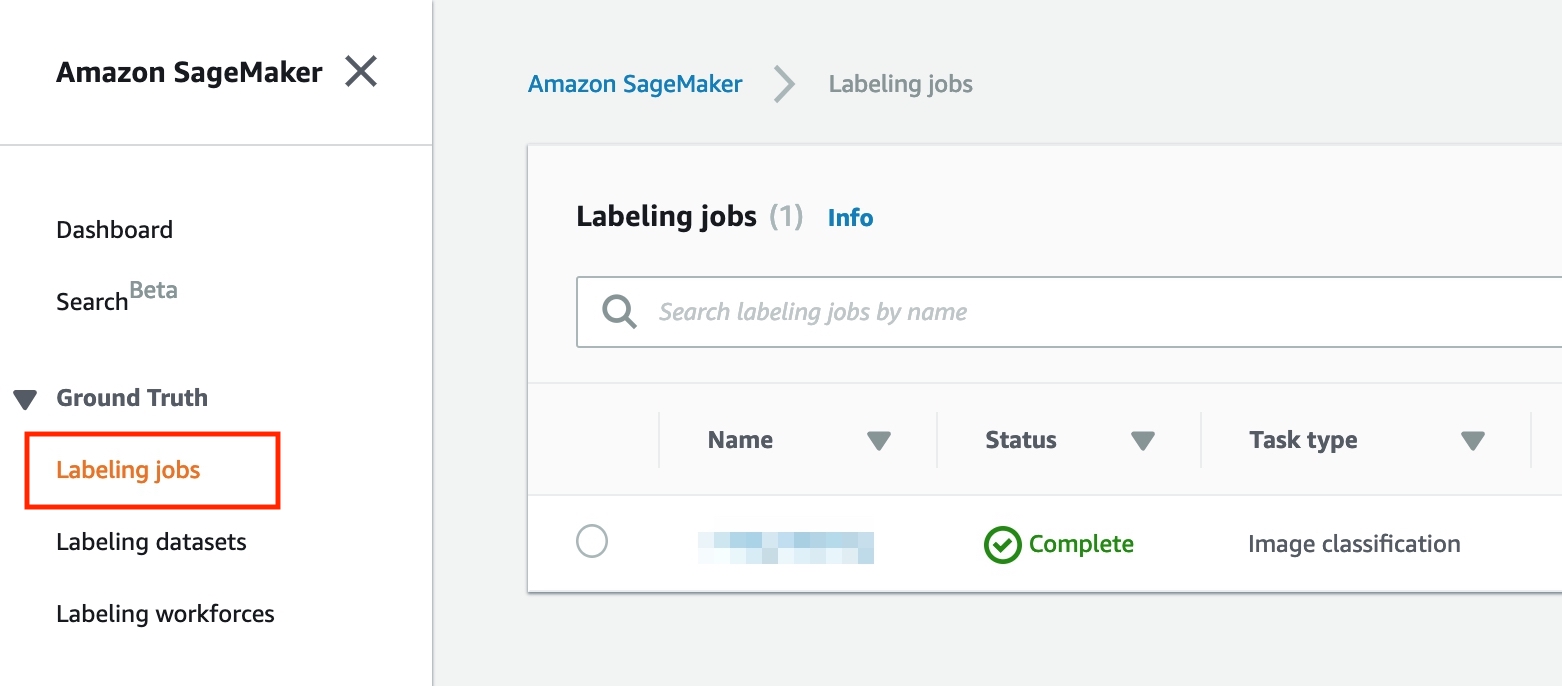
- On the service menu, select SageMaker and at the left panel, choose **Labeling jobs **.
-
Choose Create labeling job to add a new job for labeling data.
-
In the Job overview form, following these step:
-
Job name :
classify-cat-and-dog -
Input dataset location :
The bucket and dataset objects must be in the us-east-1 region
-
Choose Create manifest file to create the manifest file that contains all input data location in S3 bucket.
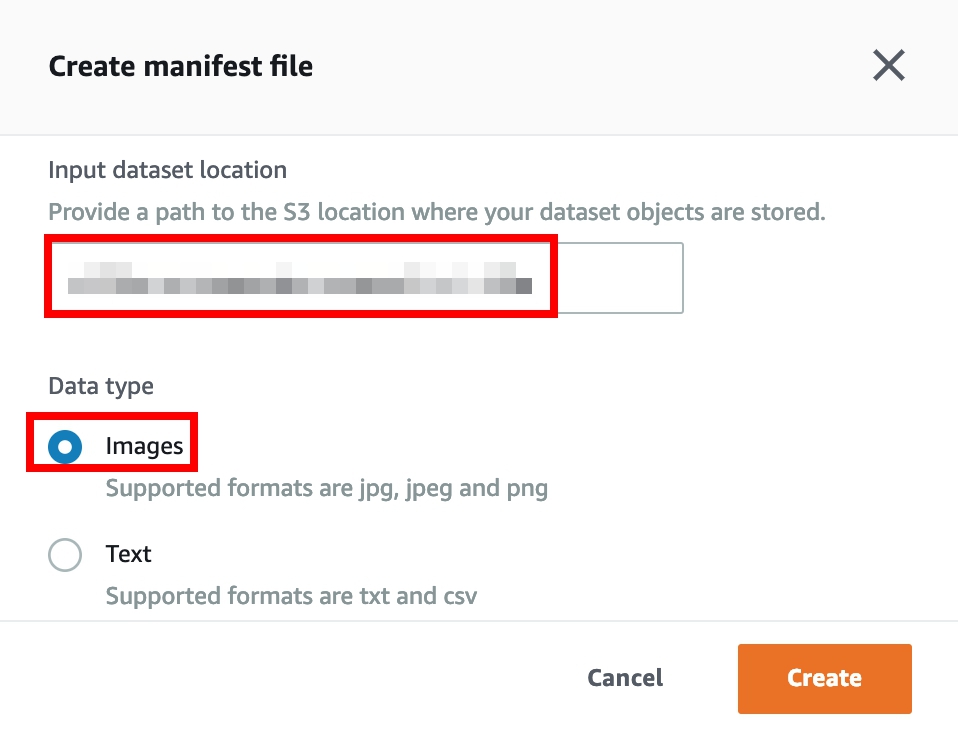
- Input dataset location: Enter the bucket name
s3://<your input data bucket name>for store input data. - Data type: Select Images as your data type, and Click Create.
- Input dataset location: Enter the bucket name
-
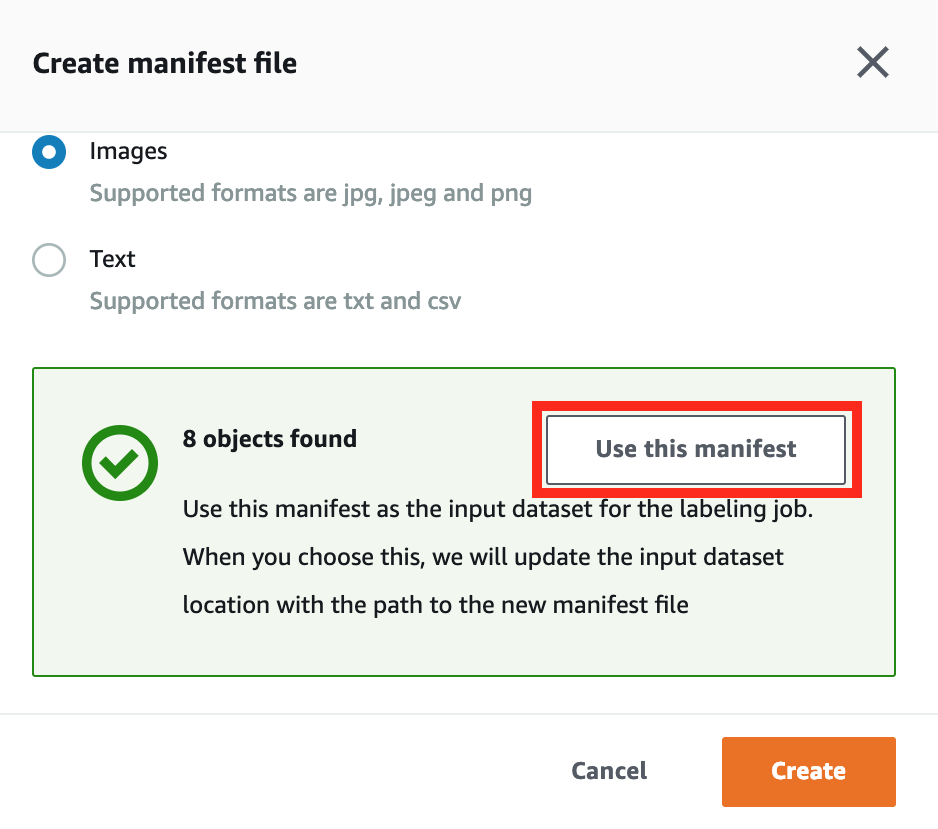
In the bottom of Create manifest file window, the success message to create a manifest will show up. And click Use this manifest to choose this file as your input file.
-
-
Output dataset location: Type the bucket name
s3://<your output data bucket name>for output data.The bucket and dataset objects must be in the us-east-1 region
-
IAM Role: When using SageMaker Ground Truth to labeling data, it needs permission to access S3 bucket.
-
Select Create a new role.
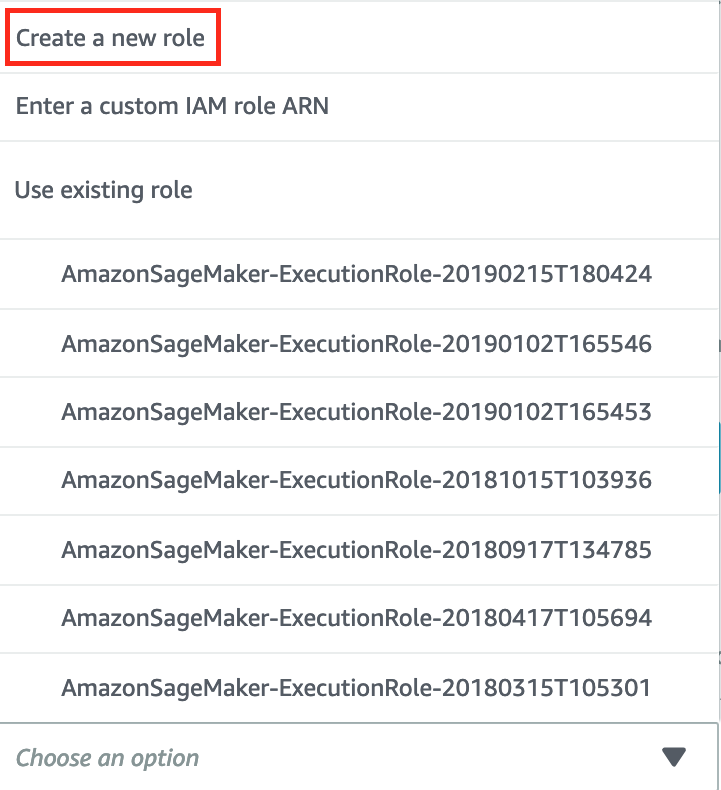
-
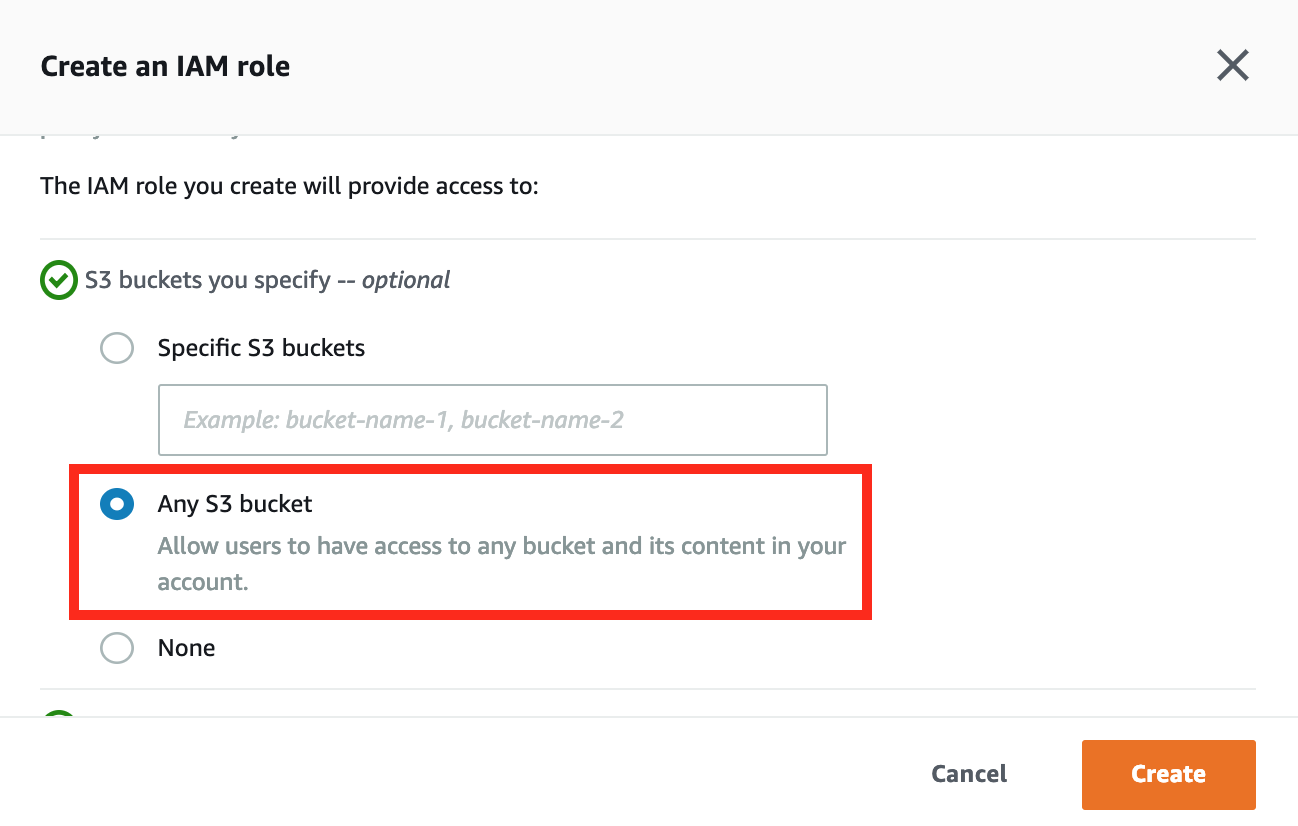
In the Create an IAM role window, choose Any S3 bucket to allow this role have access to any bucket, and click Create.
-
-
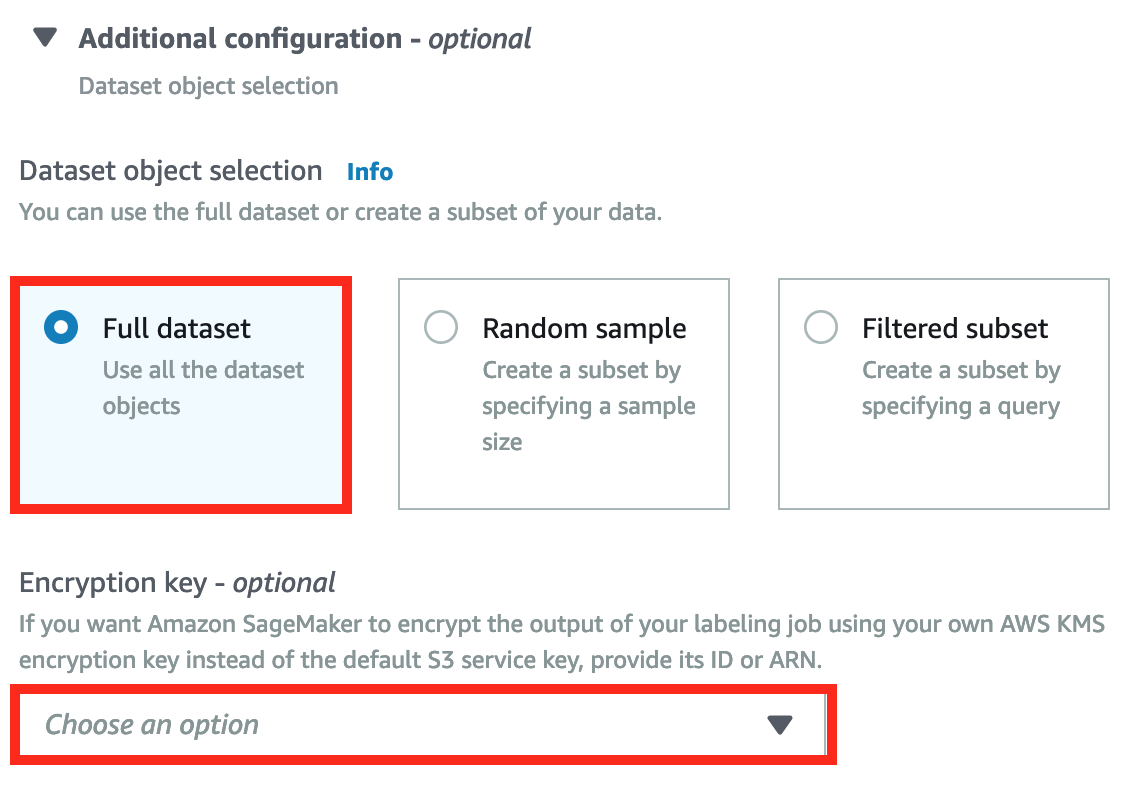
Expand Additional configuration :
-
Datasets object selection : Choose Full dataset use all data as input data.
**Another options **: If you want to use part of your data as a sample, select Random sample and set up the sample size for the random sample. You can also use Filtered subset and use SQL expressions to query your dataset.
-
Encryption key: Use default setting to encryption output data with S3 service key.
-
-
All sets will like below.
-

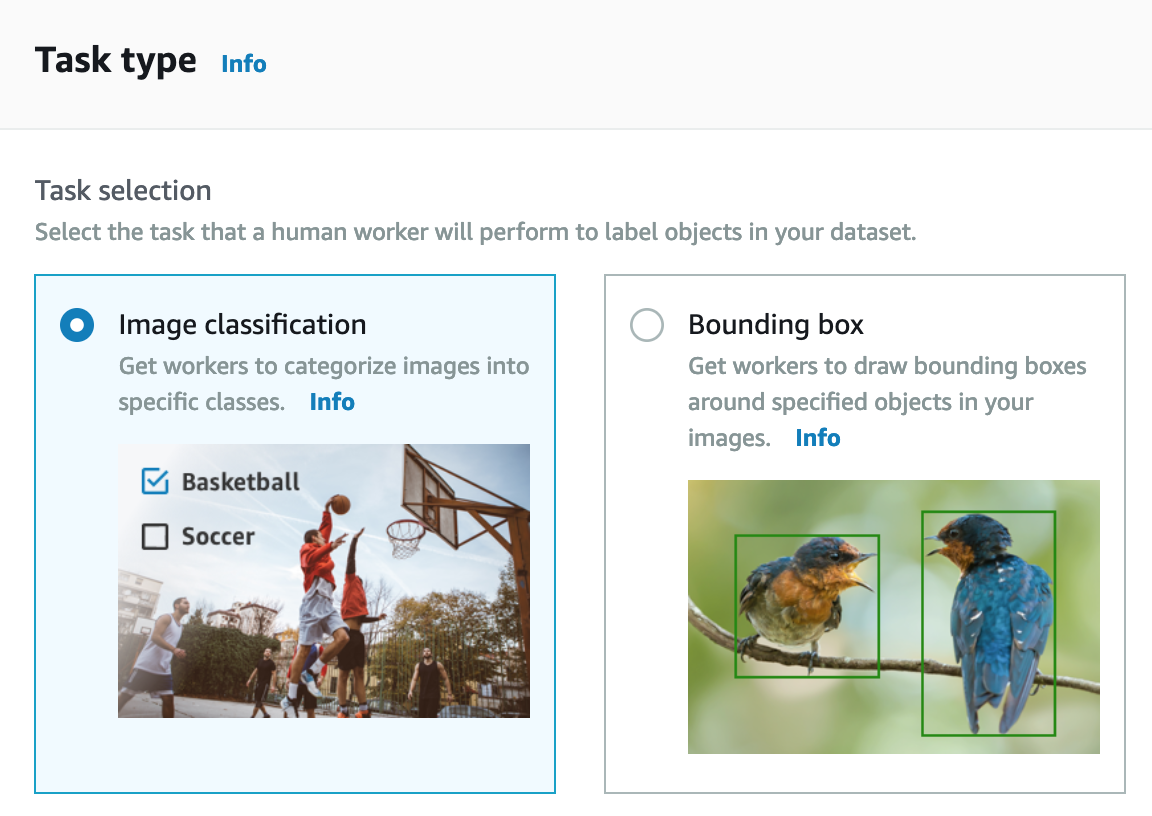
- In the Task type section : Choose Image classification to classify cat and dog, and click Next.
-
In the Workers part :
-
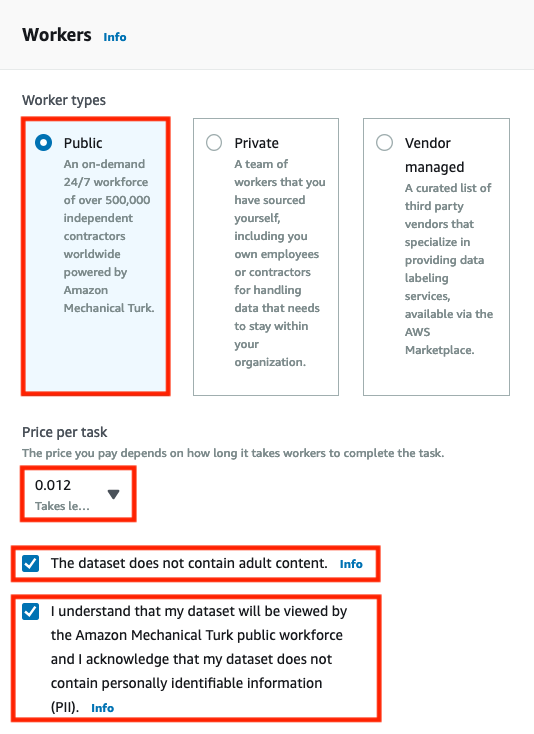
Worker types : Select Pubilc to use Amazon Mechanical Turk workforce to label your dataset.
-
Price per task : Choose 0.012 as the price you pay to workers.
It will depend on how long workers to complete the work.
-
Enable The dataset does not contain adult content.
-
Enable I understand that my dataset will be viewed by the Amazon Mechanical Turk public workforce and I acknowledge that my dataset does not contain personally identifiable information (PII).
-
Expand Additional configuration :
-
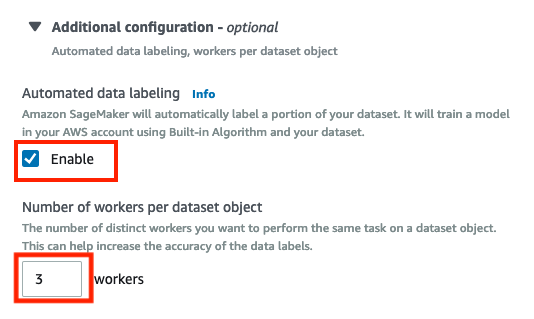
Select Enable in Automated data labeling part, it will automatically label a portion of your dataset.
-
Enter 3 in the Number of workers per dataset object filed, you can improve accuracy by increase number.
-
-
-
In the Image classification labeling tool part :
-
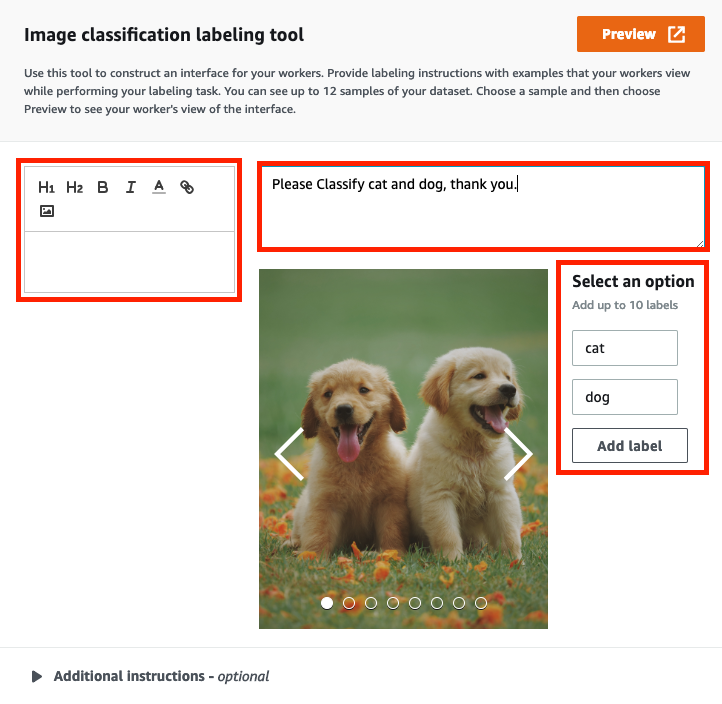
Delete the text in left block.
-
Enter the following as a description of this task.
Please Classify cat and dog, thank you. -
On the Select an option, add
catanddogas the label.
-
-
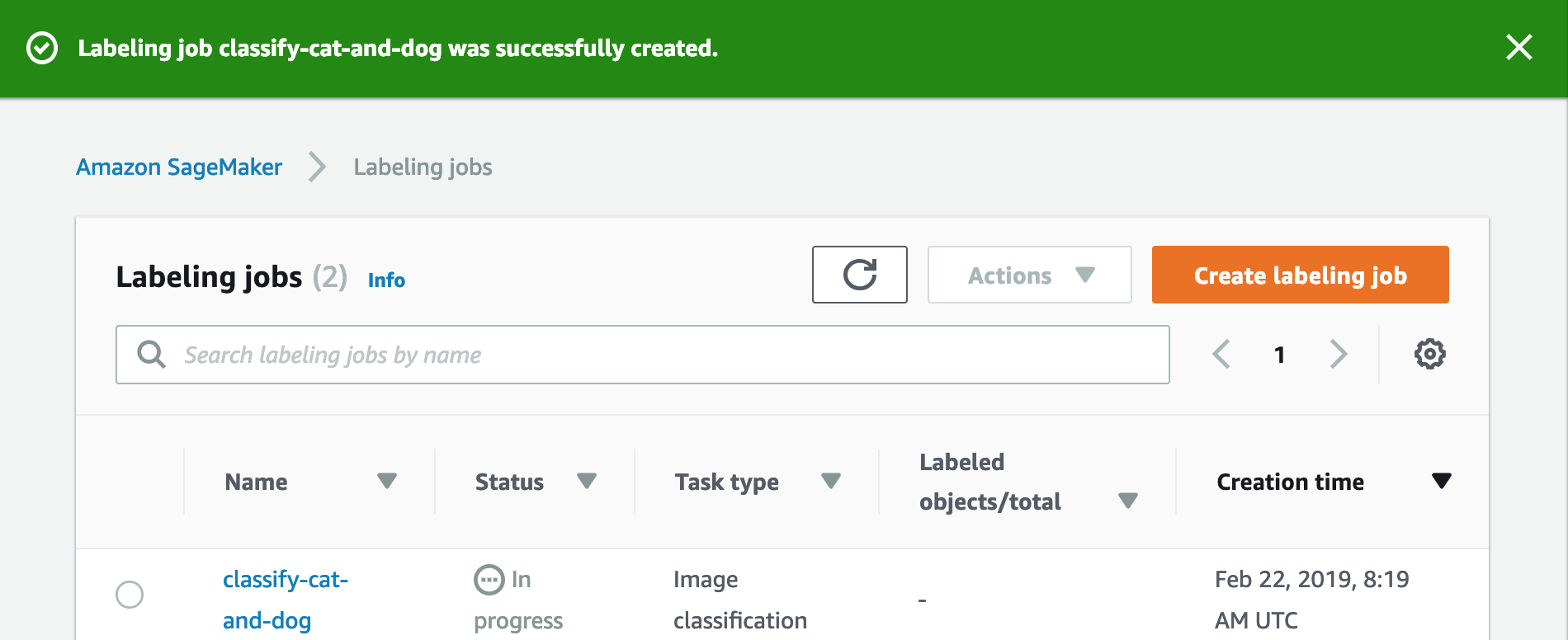
Select Submit to submit labeling job for workers.
-
Back to console, you will see the labeling job is in progress.
-
Please wait for the status become Complete.
Here may take some time to complete.
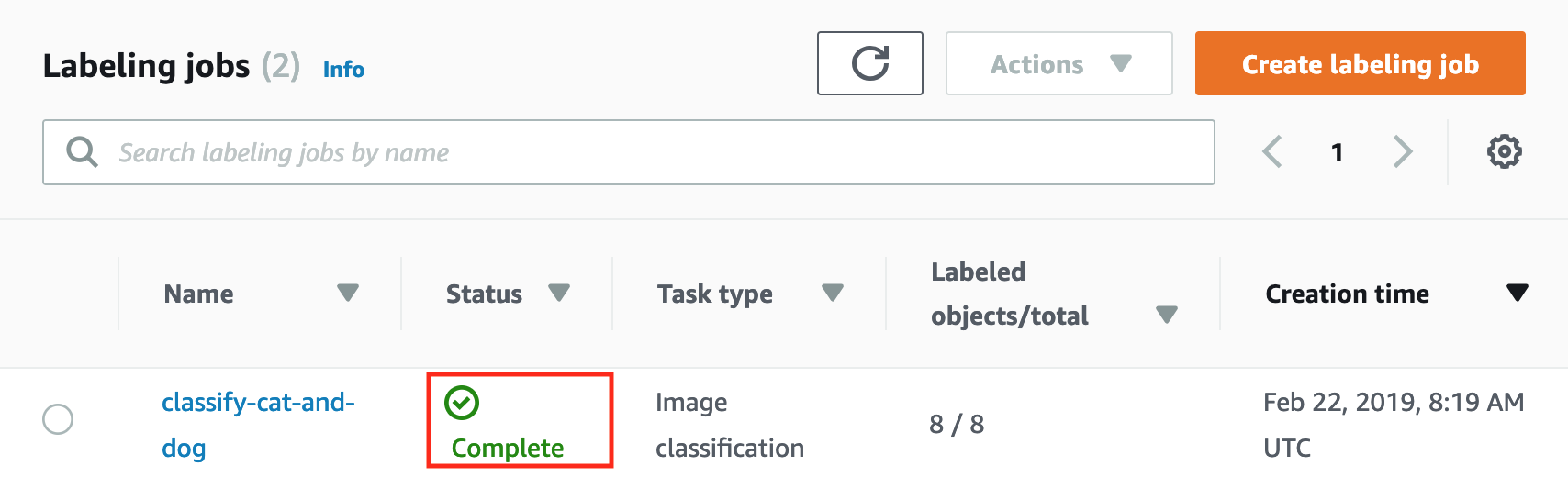
- Click the job named classify-cat-and-dog and scroll down choose Output section to check the data after labeling. You will see all data had been labeling and classification.
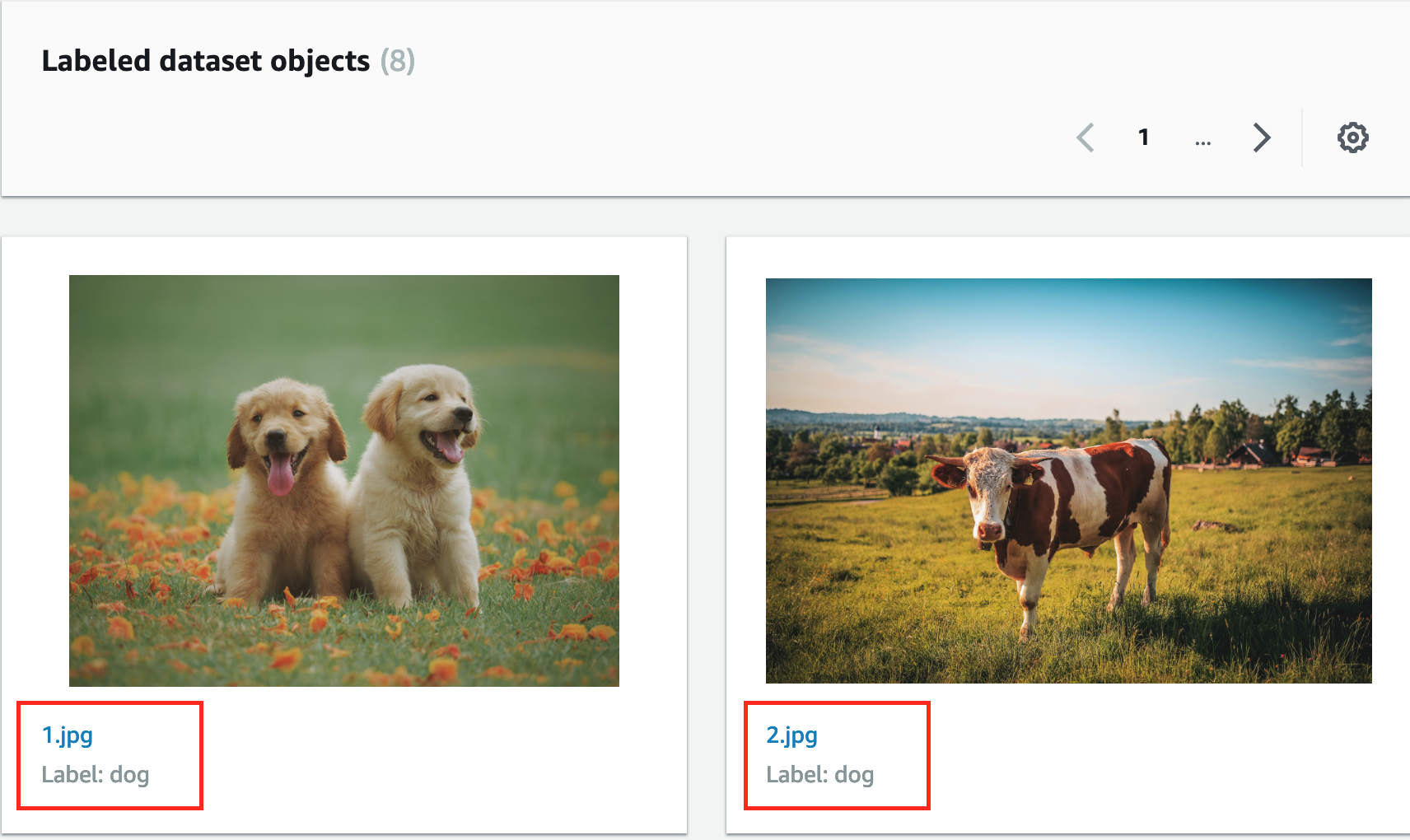
Furthermore
Amazon SageMaker Groud Truth offers three kinds of the workforce for enterprise and users:
-
AmazonMechanical Turk’s Public Workforce: Workers are available 24 hours a day, 7 days a week. Offering a rapidly scalable workforce for the small and data-heavy enterprise.
-
Private workforce within your organization: Tag data using in-house teams and use Amazon Cognito, social accounts (Google, Facebook), OpenID Connect providers authenticate, so you can address issues such as the need for confidentiality or privacy of your data.
-
Professional workforce from third-party vendors: Suppliers have extensive experience in data labeling, you can select the vendor to meet the time costs and expectations to the list provided by suppliers.
Conclusion
By completing these tutorials, you will learn how to label your data with Amazon SageMaker Groud Truth and choose the way that best suits your needs to create a labeling process. Amazon SageMaker Groud Truth not only has a wide choice of the workforce, but also allows the enterprise to choose image classification, text classification, and object inspection, etc., to build the dataset.
Because of the convenience of the Internet, social media produces a growing amount of data, and businesses must preprocess data before analyzing it. Large amounts of data increase the labor demand and cost of data labeling. The company is looking for how to speed up data labeling and reducing costs. Amazon SageMaker Ground Truth is one of the services that can resolve this issue.
You may also like

AWS re:Invent 2021 – Werner Vogels Keynote

AWS re:Invent 2021 – Adam Selipsky Keynote
